论文笔记
[1] 视觉神经系统的注意机制研究
国防科大 陈勇 的硕士论文。
人类有 80% 的信息通过视觉获得,但只有其中一部分信息可以通过选择性的注意机制的筛选而被大脑优先加工。注意是脑信息处理的一种主动策略,具有选择性、竞争性、定向性等特点。越来越多的生理数据表明人脑中至少存在表面注意、边界注意和原型注意。然而,问题在于
- 这些注意是怎样产生的?
- 这些注意是怎样影响生物视觉系统的信息处理的?
- 注意阶段与前注意阶段是如何在视觉系统中融合?
人类有 80% 的信息通过视觉获得,但只有其中一部分信息可以通过选择性的 注意机制的筛选而被大脑优先加工。这种注意机制是一种有意控制的眼动,可使 视觉系统凝视中心聚焦于某一特定物体,即将视觉刺激成像于视网膜的中央凹, 使大脑知觉系统进入“预激”状态。Duncan[2] 认为注意即通过感觉、已存储的记 忆和其他认知过程对大量现有信息中有限信息的积极加工,既包括有意识的加工, 也包括无意识的加工。可见注意是脑信息处理的一种主动策略,具有选择性、竞 争性、定向性等特点。
在分类上,
- 根据刺激选择的内外因,注意可分任务驱动型注意和刺激驱动型注意;
- 根据感觉通道,注意可分为听觉注意、视觉注意和跨通道注意;
- 根据注意选择单元,注意可分为基于空间的注意、基于客体的注意和基于特征的注意;
- 根据注意选择内容的表征,注意则可分为知觉水平的注意和概念水平的注意。
与注意有关的脑皮层主要包括: 丘脑 (Thalamus)、枕核 (Pulvinar)、上丘 (Superior Clliculus)、后顶叶 (Posterior Parietal Regions)、前额叶 (Prefrontal Regions)、扣带回前部 (Anterior Cingular Cortex) 以及其他一些神经节。这些脑区可以分为前部系统 (Anterior System) 与后部系统 (Posterior System)。前部系统 (包括前额叶) 主要参与注意机制的执行; 而后部系统则与注意的选择有关。视觉系统的注意选择是以刺激的视觉特征或空间特征为基础的: 当个体被动地将注意分配在某个特定的刺激信息上时,对刺激进行加工将引起后部脑区 (Posterior Brain Region) 的激活。
- 20 世纪 50-60 年代围绕注意机制争论的焦点是探讨目标信息的选择发生在哪个阶段。
- Broadbent 的过滤器模型[3] 认为信息一旦在感觉层次记录后,选择性就 开始过滤;
- Treisman 的衰减模型[4] 则认为未注意刺激不是完全被过滤掉,只是强度减弱而难于识别,但特别有意义项目如自己名字,虽然较低阈值却仍可受到激活被识别;
- 而 Deutsch 的反应选择模型[5] 则认为所有未注意刺激都可进入高级加工,注意仅对重要的刺激做出反应,而有些输入信息没被报告是由于要对其他信息作出反应,使得这些信息没有得到继续加工。
- Lavie 通过整合相关的行为和脑成像数据,提出了知觉负荷理论[6],调节了上述理论的对立。知觉负荷理论认为当前任务知觉负载的高低决定了注意过程中的资源分配。如果当前任务的知觉负载较低,其加工过程只耗用一部分注意资源,多余的注意资源会自动溢出去加工干扰刺激,从而产生干扰效应; 如果当前任务的知觉负载较高,则有限的注意资源被消耗尽,那么与任务无关的干扰刺激无法得到知觉加工,从而不会产生干扰效应。
- Duncan 的注意整合竞争假设7 理论认为 注意是解决竞争的许多神经机制的一种突现特征,选择性是多脑区相互竞争协调的结果,而注意从概念上分为基于空间的注意和基于客体的注意。
- 20 世纪 60-80 年代初的研究避开了注意机制所处位置的争论,而从注意的资源分配及注意与知觉操作的联系出发研究注意的选择性。
- Kahneman 的注意中枢能量分配理论[8] 提出注意是控制选择刺激并调节行为的一种内在机制。该理论认为人可利用的资源总是与唤醒水平相连,只要不超过可利用资源,人就可以同时接收两个或多个输入,或者从事两种或多种活动。
- Treisman 的注意特征整合论[9] 则从知觉和注意关系的角度出发,将客体知觉过程分成早期的前注意阶段和特征整合阶段; 认为知觉在前注意阶段是自动平行加工,无需注意; 而通过集中注意在特征整合阶段将诸特征捆绑整合为客体,其加工方式是系列的,即对特征和客体的加工是在知觉过程的不同阶段实现的。
- Tipper 等将无关信息的命运引入选择性注意理论,提出了注意的目标激活和无关信息抑制双重机制理论[10]。
- 20 世纪 80 年代以来,研究者开始意识到由所选刺激 (目标) 和非选刺激 (分 心物) 的特性及对其进行的心理加工特点出发来研究注意的本质。
- 目标激活理论认为被选刺激 (目标) 在如果在任务之前受到激活就会使反应任务受到促进作用。
- 分心物抑制理论认为注意对非选择信息 (分心物) 也进行抑制加工,但注意对分心信息的抑制使目标被选择时信息通道更畅通。
- Watson[11] 在对预览搜索 (Preview Search) 的研究中,提出视觉标记 (Visual Marking) 假设,即在任务预先设定的条件下视觉系统通过抑制旧刺激所处的位置来实现对新刺激的优先选择。
- Desimone 与 Duncan 的偏向 - 竞争模型 (Biased-Competition Model)[12] 则认为注意需要两类资源:(1) 由感知觉刺激引起的自底向上 (Bottom-Up) 的加工资源;(2) 当前任务下对 注意加工起引导作用的自顶向下 (Top-Down) 的加工资源。注意任务的完成需要这两种加工之间的相互协调与平衡: 来自物体 (Object) 的信息产生自底向上的加工资源; 而当基于物体的信息不明显或不能引起有效的注意加工时,被试就会使用自顶向下的加工资源引导注意加工。
- Grossberg[13] 等人认为在视觉感知与认知系统中至少存在三种比较显著的注意机制:边界注意、表面注意与原型注意。
- (1) 边界注意是指空间注意在物体边界加强而对该物体进行处理;
- (2) 表面注意是指空间注意选择性地对物体进行表面形状填充而形成“注意覆盖”
- (3) 原型注意是指视觉系统的目标注意对待分类物体的重要特征模式进行选择地加强。
- 边界注意在前注意阶段可通过合作竞争自底向上地产生,在学习知识的自顶向下调制中得到抑制或加强;
- 边界注意在视皮层 V4 区通过表面填充产生自底向上的表面“注意覆盖”,表面注意通过选择性覆盖对场景目标进行感知与定位,引导眼睛对场景主动扫描[14],进行主动视觉搜索, 通过 V3 区的表面轮廓处理自顶向下地调制边界注意。
- 原型注意在认知识别中通过激励性匹配自底向上的输入特征模式与自顶向下的期望特征模式增强人脑对感兴趣特征的认知,该注意机制在自适应共振理论 (ART) 中得到实现。
- 可见三类注意机制的综合作用融合了数据驱动的自底向上的视觉感知以及任务驱动的自顶向下的视觉感知与视觉认知期望,综合了空间注意与目标注意在视觉神经系统的调制功能,实现了大脑中的共振反馈环。由于这三类注意机制在 What 和 Where 视觉通道中存在通道内以及通道间的相互作用,因此区别它们比较困难。例如,当 Where 通道中的空间注意投射到 What 通道中的感知边界表征时,边界注意以及表面注意都得到激活并互相作用,从而形成了表面覆盖共振现象;而原型注意机 制在整个 What 中都存在。另一方面,分辨出这三类注意机制的特征也是非常复杂的,因为视皮层 V1 区和 V4 区的边界和表面表征通过 V3 区的表面轮廓存在反馈关联,从而帮助目标 -背景在深度上的分离以及控制眼球移动[14]。空间注意的 这两种方式由于存在跨通道的反馈调制而影响了边界和表面表征。在运动感知方面,运动激励能够同时激活 What 和 Where 处理通道并能自动诱发空间注意。
视觉神经系统的解剖学结构
- 视网膜 (Retina) 是生物视觉处理的第一步。
- 它将光信号转化为神经脉冲 (Neural Impulse),反应明暗、颜色变化。
- 猫视网膜神经节 (Retinal Ganglion Cells) 分为大神经节细胞 (M 细胞)、小神经节细胞 (P 细胞) 以及非 M 非 P 细胞 (W 细胞)。
- W 细胞感受野大,突触特别细,动作点位传导速度最慢,主要投射到上丘 (Superior Colliculus),与眼球运动的控制有关;
- M 细胞感受野与 W 细胞相似,兴奋或抑制是非线性的,对大光斑以及运动目标敏感,瞬变反映光变化,主要分布在黄斑中心凹的外围,敏感于地空间频率;
- P 细胞感受野小,兴奋或抑制可线性叠加,对小目标光斑敏感,分辨细小目标的空间分布,持续性反映光变化,主要分布在黄斑中心凹附近,敏感于高空间频率。
- 外膝体 (LGN)[15] 是视觉信息从视网膜到视皮层通路的中继站,介导了如中心周边拮抗、方位 / 方向选择等一些基本的信息加工机制。
- LGN 分为 6 层,第 1、2 两个腹侧层为大细胞层,第 3∼6 层为背侧小细胞层。
- 视网膜 M 细胞全部投射到 LGN 大细胞层; P 细胞全部投射到小细胞层; K 细胞接受来自 W 细胞的输入,把 LGN 各层细胞分开,并投射到视皮层。
- 视皮层通过直接的兴奋性连接和间接的抑制性连接,反馈调节着 LGN 的反应模式,从而提高视网膜到 LGN 信号传导的时间精确性,有助于立体视觉感知、同步振荡及 LGN 的自动簇发 (Burst)。
- 初级视皮层 (Primary Visual Cortex,V1) 又称纹状皮层或 17 区,代表了视觉 皮层信息处理的第一阶段。
- 扩散张量成像清晰地表明从 LGN 发出的视放射纤维,一部分直接向后沿双侧脑室外上部到达 V1; 一部分向前外走行至侧脑室颞角外上部,然后转向沿侧脑室后角外侧壁走行 (即 Meyer 环),向后内成扇形投射到 V1;
- 另外约 10% 则投射到皮层下[16]。接受 LGN 大细胞输入的IV cα 层主要向 IV β 投 射 (M 通道); 接受 LGN 小细胞输入的IV cβ 层则主要向II层斑块间区投射 (P 通 道); 而接受 LGN 颗粒层输入的第III区为斑块通道 (K 通道)。M 通道、P 通道、K 通道分别对物体的运动、形状、颜色进行处理。同时,V1 也接受中颞叶 (Middle Temporal Cortex,MT)、内上颞叶 (Medial Superior Temporal Cortex,MST)、颞上沟底部等脑区的反馈投射[17]。
- V1 区神经元对颜色、空间频率敏感; 能够辨认出方位、运动方向和视觉上的微妙变化,并且保留小的感受野以提供高空间信息的详细特征。它是按照自然界生物提取处理信息的最经济的稀疏编码原则对视觉信息进行独立成分特征表达[18]。
- 纹外视皮层中 V2 区 (18 区)、V3 区 (19 区)、V4 区、V5(MT) 区为高级视皮层 区。V2 接受来自 V1 的前馈输入,并投射到 V3、V4 和 V5,同时对 V1 反馈;
- 该区的神经元除了对位置、空间频率和颜色等简单特征进行调制外,也调制某些复 杂视觉特征。
- V3 接受来自 V1 和 V2 的输入,投射到后顶叶皮层,其背侧和腹侧分别负责对侧视野的下部和上部; 辅助区 (V3A) 负责整个对侧视野的运动加工。
- V4 区通常被认为是人脑的颜色处理中心,与 V5 区有一定的连接,接受来自 V2 和 V1 的前馈输入,投射到后颞下回皮层 (PIT),对诸如简单几何形状等相对复杂 的位置、空间频率和颜色刺激进行调制。MT 区加工复杂的视觉运动刺激,把局部的视觉信号整合到物体复杂的整体运动中去,接受 V1、V2、V3、腹后区、内顶区以及上丘脑区的输入[19],也接受来自 LGN 的少量输入。该通路从理论上解释了盲视现象 (V1 受损后,患者仍能判别视野物体的运动等信息),使人能够在没有注意指引的情况下对高速危险物体迅速作出反应[20]。
脑功能定位研究表明视觉系统存在两条解剖和功能上相对独立的通路:
- 腹侧通路 (Ventral Pathway)。该通路沿着大脑皮质的枕颞叶分布,从枕叶的 V1、V2,经 V4 区投射到颞下回 (Inferior Temporal Cortex,IT),包括颞下回前区 (AIT)、中区 (CIT)、后区 (PIT)。该通路主要处理物体的颜色与形状等客观特征,也称为“What”通路。
- 背侧通路 (Dorsal pathway)。该通路沿着枕顶叶分布,从 V1、V2、V3 经 MT、MST 投射到顶叶,包括顶内外侧区 (LIP)、顶叶腹内侧区 (VIP),该通路主要处理物体的运动及空间关系等空间特征,又称为“Where”通路。
两通路均投射到前额叶,同时额叶反馈投射到视皮层,实现视觉加工自上而下的调节作用。同时 Gazzaniga[23] 的研究表明位于 V1 和 V2 边界的胼胝体把大脑 右半球的左半视野和左半球的右半视野综合起来,实现两侧半球间的信息传递以及协同性。各种视觉特征是在视觉系统不同皮层区域被平行分布加工的,通过同步振荡现象[16] 使视觉特征整合成一个整体而形成知觉。
大脑的加工神经机制
两种广泛存在于大脑神经加工机制: 互补计算加工机制以及 Laminar 计算加工机制。这两种加工神经机制的共同作用使大脑在抑制不确定的同时融合自顶向下的注意调制和自底向上的前向信息处理。
大脑的互补计算加工机制
大量的证据显示大脑是以具有互补性质的并行加工流程的形式组织起来的。加工流程内的分层调制以及流程间的并行调制的共同作用构建了连贯的行为表征,从而抑制了每个流程的互补性缺陷,实现了统一的心理知觉。因此互补加工流程是大脑的功能单元。只有通过它们之间的调制,重要的行为特征才能完全被大脑所知觉。为什么加工流 程需要分为不同的层次阶段呢?许多证据显示这些层次实现了对不确定性 (不确 定性是指在给定阶段对某一特征的感知能够抑制另外不同特征的计算信息) 的分 层解析。而运用分层加工流程可以这些抑制不确定性。
互补计算 (Complementary Computing)[24] 性质是加工流程内以及流程间的信息处理的基本形式,如同物理学中的海森伯不确定原理。在图2.1中,边界与表面感 知是视觉形状加工流中的互补对。它是在 FACADE(Form-And-Color-And-Depth, 即形状、色彩和深度) 模型[22] 框框中提出来的。该模型认为表面感知过程经过视网膜 → 外膝体小细胞 →V1 色斑区 →V2 细条纹区 →V4 区,而边界感知过程经过视网膜 → 外膝体小细胞 →V1 区色斑间区 →V2 中间条纹区 →V4 区。表面感知敏感于亮度与色彩而边界感知敏感于局部对比度与对比度方向。边界感知通过竞争和合作机制得到不受噪声干扰和小范围遮挡的自动边界分割和边界完成。这些边界结构是不可见的,只有通过表面感知以无方向的填充的形式才能产生可见的输出。图2.1的运动感知过程是在“FORMOTION”(Moving-Form-In-Depth)[25] 理论框架中提出来的。该感知经过视网膜 → 外膝体大细胞 →V14B 区 →V2 粗条纹区 → 颞叶中区。形状感知运用方位调谐细胞形成突发的物体边界和表面表征,精确的左右眼的方位对比产生物体的相对深度表达,从而形成三维边界与表面感知。 运动感知流程运用同方向上的不同方位产生运动物体方向和速度的精确判断。大量的心理和生理数据表明运动方向感知流程只能产生粗糙的深度判断,而形状方位感知流程能够产生精确的深度判断。从这一事实可以得出方位和方向具有互补性质。FACADE 理论认为形状感知流程的 V2 区与运动感知流程的 MT 区具有跨通道的调制联系。正是基于此,大脑才能得到在不同深度下物体的精确的运动方 向和速度大小。
互补的形状和运动感知是“What”和“Where”感知的一部分。形状感知所得信息送到颞叶下区,这一脑区被认为是对物体的分类和识别,而运动感知所得信息送到顶叶区,这一脑区被认为是对物体空间位置的感知、跟踪以及处理。然而知觉和认知感知并没有被认为是互补于空间与运动感知。神经建模已经证明感知与认知过程解决了“稳定性 -可塑性”矛盾 (Stability-Plasticity Dilemma)[13],从而使大脑能够快速且稳定地学习外部世界而不灾难性地遗忘已学知识,即大脑既保持持续学习的可塑性又保持已学知识的稳定性。这种快速稳定学习能够使人类 非常专业地处理复杂变化的外部环境; 而已学知识在偶然变化中得到修正;新的 知识在不损坏由于灾难性地遗忘已学知识的情况下产生发展。但灾难性地遗忘空 间和运动的感知却是非常有效的方法。由于人类不可能继续运用幼年所感知的空间与运动表征指导成年的行为,大脑不必记忆所有童年所感知的空间和运动表征。这种 “What” 和 “Where” 记忆的显著区别被认为来自于对外部世界预期的 学习与对这些预期所进行的预期与外部世界数据的匹配的互补机制。认知流程运用激励性匹配和注意聚焦产生大脑选择性的共振状态来支持意识活动。另一方面,空间和运动感知则采用抑制性匹配从而不产生共振状态,使大脑能够快速适应变 化的外部世界。因此认知过程中的学习是匹配性学习,而空间和运动感知过程中 的学习则是非匹配性学习。认知过程中的匹配与学习与空间与运动感知过程中的匹配与学习具有互补性质。正是基于此,大脑才能稳定地感知变化中事件的发生,从而解决了“稳定性 -可塑性”矛盾,而又能自适应地修正物体在大脑中表 征以及对它的处理手段。匹配性学习只是一种监督性的学习,而人类以及动物在 其早期表现出显著的非监督性学习方式,以及半监督和自监督学习方式。ART 理 论[26–29] 运用互补性的注意性学习与视觉搜索解决了上述问题。
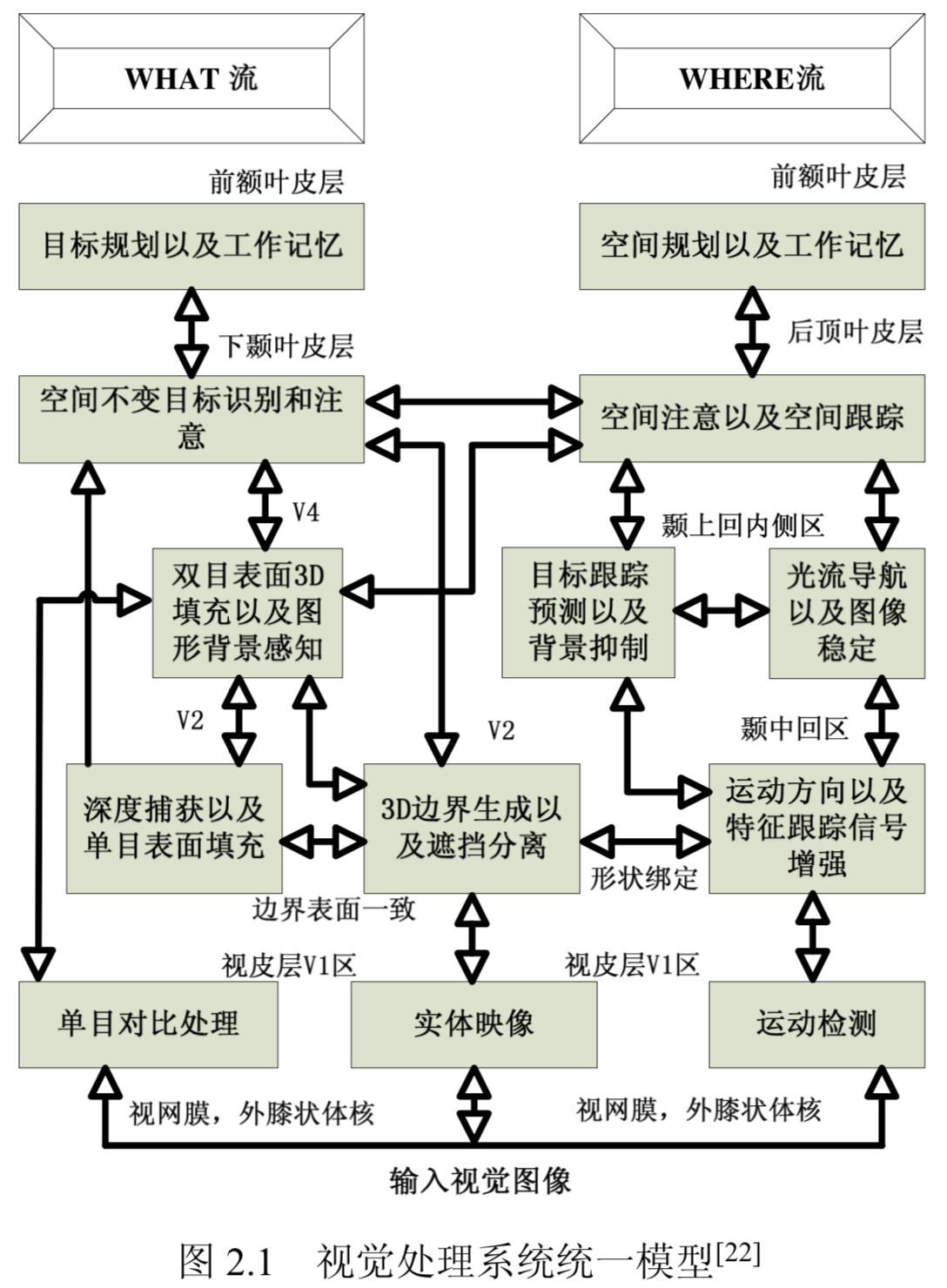
大脑的 Laminar 计算加工机制
Laminar 计算[13, 22] 是基于这样一个事实: 大脑皮层 (高级智能所在的位置) 由
层次网络组成,通常主要由六层组成; 层次结构之间存在着自底而上、自顶而下垂直以及层内的水平的调制。根据回路厚度的不同,德国解剖学家 Korbinian Brodmann 发现在新皮层中存在 50 种这样的层次结构。最近研究表明前额叶区中 Laminar 网络能在工作记忆中对事件序列作短时记忆存储,进行选择性学习分类以及在意志控制下的按不同速度执行已存储序列。表2.1列出了 Laminar 计算加工 机制的相关生理学依据。


Laminar 计算有三个特征[22]:
- Laminar 计算是一种全新的集前馈 -反馈,数字计算以及模拟计算的混合 感知计算,已经超过了当前盛行的贝叶斯计算,为视皮层发展以及终身学习提 供了快速且多尺度的自组织特征。在初级视皮层内,Laminar 计算实现了特征组群(大脑依据场景或图像中纹理、形状以及深度信息形成突发的边界结构从而分离目标和背景),通过存在于第 6 层和第 4 层的前注意与注意接口把数据驱动的自底向上的前注意过程与任务驱动的自顶向下的注意过程集成在同一网络中,从而实现了“捆绑问题”(空间分布的特征如何绑定为外部世界中目标和事件)。 Laminar 计算如同实时概率决策网络,在确定的情况下表现为快速的前馈模式, 而在显著不确定的情况下自动转换到较慢的反馈模式。注意机制选择一个获胜的决策从而加速计算。获胜组群的幅度随着获胜组群的选择而同步地得到加强,从而使确定性得到增加,进而加快处理速度。这一特点在 3D FORMOTION[31] 以及 Retina/LGN-V1-MT-MST-LIP-Basal Ganglia[25] 模型中得到证明。
- Laminar 计算是一种全新的实现同步数字计算的稳定性和模拟计算的敏感性的混合计算。2/3 层 -4 层 -2/3 层的反馈网络能同步存储获胜组群而不丢失对输入模式不同幅度的模拟敏感性,即模拟凝聚[22]。同步的选择性和存储的凝聚性提供了数字计算的稳定性,而模拟计算的敏感性在 4 层和 2/3 层中的激励与抑制的平衡以及抑制的膜电位动态过程中得到展示。
- 通过 2/3 层 -6 层 -4 层 -2/3 层的皮层内的反馈得到自稳定发展和学习,从 而使人类能从婴儿阶段就开始稳定地发展以及在全部生命过程中不断学习,也使人类在成人阶段能够快速处理获胜组群。这种皮层内的反馈在自顶向下的皮层间反馈作用之前通过稳定皮层的发展而阻止了无限循环。通过两种不同的反馈, Laminar 计算能够稳定视皮层的发展和学习;通过前注意组群而产生它自身的原始注意机制,Laminar 计算可以在没有自顶向下的注意的情况下通过 6 层 -4 层的竞争决策网络来选择正确的群组细胞从而得到学习。
生物视觉系统的生理解剖结构与视觉系统的功能结构是对应的。生物视觉的功能主要是在大脑皮层中实现,主要由 What 与 Where 通路加以承担。 而空间注意中边界与表面注意以及目标注意中的原型注意广泛存在于 What 与 Where 通路,调制着视觉系统对外部世界的感知与大脑内部表征。
人类至今还没有完全理解大脑的工作机制以及大脑对视觉信息的处理机制; 对注意机制在生物视觉信息处理中的作用机理还没有完备的理论。
自适应共振模型
- 边界与表面注意调制下的视觉信息感知
- 原型注意调制下的认知识别分类
自适应共振模型 (Adaptive Resonance Theory,ART) 是由美国 Boston 大学 S. Grossberg 和 G.A. Carpenter 于 1976 年提出来的。他们对人类认知的特点进行了研究 (诸如集中注意力、记忆的弹性和刚性、认知过程中自底向上以及自顶向下的双向作用等),并在此基础上设计出对输入模式进行自组织 (神经网络在与环境交互时,对环境信息的编码会自发地在网络中产生,则认为该神经网络在进行自组织活动) 分类且具有人类认知特点的无监督的神经网络。
ART 模型来源于 Helmboltz 的无意识推理学说的协作-竞争网络交互模型。该学说认为原始的感知信息通过自底向上以及自顶向下的学习过程不断修改,直到成为一个真实的感知结果为止。该模型有三个特点:(1) 交互作用是非局域性的; (2) 交互作用是非线性的;(3) 自顶向下的期望学习是非平稳随机过程。图4.1详细 描写了 Helmboltz 的协作-竞争模型结构,可以看到环境输入信号对自上而下学习期望进行触发,使协作-竞争网络 1 产生自底向上的学习的输出。该输出送到协作-竞争网络 2,产生自顶向下的学习期望输出,并送回协作-竞争网络 1。这种自底向上与自顶向下的学习过程不断吸收环境输入信息,经过协作-竞争的匹配,最终得到谐振感知。
ART 模型以连续非线性网络为基础,由代表神经元的激活值的短时记忆 STM 以及权系数的长时记忆 LTM 共同作用实现人类的无监督学习。
ART 模型由注意子系统 (Attentional Subsystem) 和与之具有互补性功能 的取向子系统 (Orienting Subsystem) 组成。在注意子系统中,有 F1、F2 两个短时 记忆单元 (STM),以及两者之间的长时记忆单元 LTM。增益控制的作用为:(1) 在 F1 中用于区别自底向上和自顶向下的信号;(2) 当输入模式信号进入系统时, F2 能够对来自 F1 的模式起阈值整流作用。取向子系统由警觉 ρ 和 F2 重置信号通 道组成。其中注意子系统的作用是对熟悉模式进行处理。在这个子系统中建立熟 悉模式对应的内部表征,以便响应相关熟悉模式。这种处理实际上是对 STM 中 的激活模式进行编码。同时在这个子系统中还产生一个从 F2 到 F1 的自顶向下的期望模式样本,以帮助稳定已学习的模式编码。调整子系统的作用是对不熟悉模 式产生响应。在有不熟悉模式输入时,孤立的一个注意子系统无法对不熟悉的模 式建立新的聚类编码,故而设置一个调整子系统。当有不熟悉模式输入时,调整 子系统马上产生重置信号对 F2 进行调整,从而使注意子系统对不熟悉模式建立 新的编码表征。实际上,当自底向上的输入模式和来自 F2 的自顶向下的期望模 式即原型注意模式在 F1 中不匹配时,取向子系统就会发出一个重置波信号到 F2, 而从重新选择 F2 的激活单元,同时取消 F2 原来所激活的输出模式。
简而言之, 注意子系统的功能是完成自底向上的输入模式的竞争选择,以及完成自底向上输 入模式和自顶向下原型注意期望模式的相似度比较;而取向子系统的功能是检验 期望模式与输入模式的相似程度,当相似度低于某一给定警觉 (警觉是指对不可 预测刺激出现的警惕,刺激可以通过任何感觉通路加以感觉) 值时,即取消该时 刻的竞争优胜者,转而从备选类别中选取优胜者。
[2] 基于上下文的目标检测与与识别方法研究
华中科技大学 高常鑫 的博士伦说
目前主流的目标检测与识别方法是基于局部特征的, 但是该类方法在图像质量比较差的情况下存在不确定性或者歧义性, 而且视觉搜索效率比较低。上下文信息主要有两个作用, 即消除不确定性或歧义性以及减少处理时间。 因此上下文信息正好适合解决基于局部特征方法的问题 。
识别是计算机视觉研究的热点, 但是同时也是难点, 导致识别性能不高的主要原因包括视点变化、亮度变化、遮挡、尺度变化、形变、复杂的背景、目标类内变化等等。但是人类视觉在目标识别方面的性能却非常突出, 即使目标发生很大的变化, 仍然能够很容易地识别它们 。
很多研究者希望从人类视觉系统中找到一些启发, 以提高计算机视觉系统的性能。但是其关键点不是机械地模仿人类视觉系统, 而是通过对人类视觉系统的研究发现是什么因素使人类视觉系统的性能如此之好, 并且把它结合到计算机视觉系统中去。
对于目标检测与识别任务, 上下文信息在人类视觉中起到了至关重要的作用。传统的目标检测与识别方法是将图像中的有效特征与目标物体的描述匹配, 同时拒绝背景干扰的特征。也就是说, 传统的方法认为目标的上下文阻碍了识别的准确性, 正是这些上下文组成的干扰使得识别过程非常复杂。而人类在感知现实世界过程中, 目标的上下文是人类视觉突出性能的重要保证, 而不是阻碍作用。
探索基于上下文的目标检测与识别方法, 在此之前需要弄清楚三个问题:
- 什么是上下文?
- 人类视觉中如何使用上下文?
- 基于上下文目标检测与识别方法研究现状如何
上下文概述
什么是上下文
从更普遍意义上讲, 上下文是研究对象所处的周围环境。在 目标检测与识别任务中, 上下文可以定义为和任务相关但是不是直接依赖于目标的 物理表观的信息。比如路的位置可能会影响汽车的检测。一般来说, 自然图像中, 目标和场景都有很强的特定关系, 上下文就是描述这种关系的。在目标检测与识别中, 上下文信息从尺度上可以分为下面三种
- 局部区域上下文:待识别目标图像中包含很多局部区域, 每个局部区域与其周围都有一种关系 , 描述这种关系的信息称为局部区域上下文特征 , 包括局部区域的邻域上下文和局部区域之间的几何上下文位置关系
- 目标上下文:待识别目标与周围目标都有一定的联系, 包括这些目标是否出现, 以及这些目标与待识别目标的位置和尺度关系, 这些信息称为目标上下 文
- 场景上下文:目标都是处于一定场景的, 目标所处的场景对于目标的检测与识别有很大的帮助, 该场景信息称为场景上下文。
人类视觉是如何使用上下文的
上下文对视觉的影响
认知心理学认为, 知觉与人的知识经验是分不开的。知识经验对于视觉的影响是多方面的 , 最引人注目的体现为上下文作用。人的视觉过程可以看作是在上下文的引导和规划下进行的。人类在目标检测与识别时, 上下文是很重要的提示, 主要基于两方面的原因消除歧义性和不确定性以及减少处理时间。而这两个原因正好对应上下文的两个功能。上下文可以指出什么是值得注意的, 什么是可以忽略的, 这就大大减轻了视觉的负担, 减少了处理时间。在局部特征不足时, 局部特征方法很难做出决策, 上下文的加入可以比较容易地确定目标。 Bieberman 等指出人类在目标检测时, 违背上下文时间会增加, 也更容易出错。另外功能磁共振成像结果已经证实了人在识别时是使用上下文的。如果人体是处理视觉上下文的进化体, 那么上下文信息就是理解视觉世界的有效途径。因此, 可以推断上下文对于人造视觉系统也是有利的。
自下而上方式和自上而下方式
视觉的处理有两种方式:自下而上方式和 自上而下方式。
自下而上方式指先从小尺度的单元进行分析, 然后再在较大尺度的单元上进行处理, 逐级向上, 最后得到视觉图像的解释。而自上而下方式是指先从视觉对象的相关知识得到相关的期望或者假设, 然后根据这些期望和假设调整视觉对更小尺度的注意。人类视觉系统中两种处理方式并不是孤立存在的, 这两种方式是同时存在且相互作用的。
反转分层理论认为两种方式是同时存在的, 信息首先是自动的自下而上处理过程 “第一印象”, 然后是自上而下的处理过程 “仔细审查”。但是该模型没有特别强调两种处理方式之间的交互。Eysenck 指出在不同的条件下, 两种方式的 “参与” 程度是不同的, 良好的条件下, 自下而上处理比较多, 随着条件恶化, 自上而下处理逐渐增多。 进一步指出, 人类视觉系统中自上而下的连接是自下而上连接的 10 倍。
计算机视觉中主流的方法是基于提出的视觉计算理论的, 它是一种自下而上的、模块化的、单向的、数据驱动的结构。虽然在 “良好” 的条件下取得了不错的效果, 但是近年来很多研究者发现对于 “恶劣 ” 的条件, 该模型有很大的局限性, 仅仅利用自下而上的处理结果往往是模糊的, 有歧义的。而上下文的作用之一就是可以消除歧义性和不确定性。因此上下文信息的参与是解决 “恶劣” 条件下目标识别问题的有效途径 。
整体优先与局部优先
视觉还涉及另外一个重要问题 —— 整体和部分问题, 是整体优先还是局部优先, 即人类视觉是从整体开始, 还是从部分开始。
- 特征分析理论认为知觉首先是从局部开始, 局部组成整体 。
- 拓扑知觉理论认为局部图形之间的知觉组织决定了整体知觉相对于局部知觉的优先性。
- 格式塔心理学认为整体多于部分之和, 整体决定着其部分的感知。认为整体知觉发生在比局部知觉更早阶段。
一些研究认为人类对于现实世界场景的识别任务也是从整个场景开始的, 甚至不需要识别其中的目标。人类可以在 200 ms 内捕获一幅场景中一定的感知和语义信息(图像和其中部分目标的语义类别以及它们的一些属性)。Biederman 还证明了人类识别一幅场景和识别一个物体同样快, 这就是说人类不是感知场景中的物体后才感知整个场景的。近年来一些研究认为绝大多数现实世界场景图像的语义类别可以通过它们的空间分布推断得到。这些场景感知实验说明视觉系统首先处理场景上下文信息, 然后在场景上下文信息的指导下来获得目标的属性。
基于上下文的检测与识别方法的研究现状
目前计算机视觉中应用最广的模型是的视觉计算理论。虽然该框架极大地推动了计算机视觉研究的发展, 但是很多学者认为该理论还不能被认为是一个完善的理论, 它并没有包括视觉系统的所有方面, 而且它没有能反映人类视觉的某些本质, 这就是人类视觉中的选择性和整体性。其中选择性就是指在上下文的指导下自上而下的处理方式, 整体性就是指整体优先的策略。而这些处理方式正是人类的视觉如此优秀的原因。
目标与上下文的关系越强, 检测与识别就越容易
通常来说, 计算机视觉中上下文可以定义为和目标相关但不是目标本身的表观描述的所有信息, 这些信息一定程度上揭示了该目标的 “内涵”。
局部上下文
BoW 效果不错,但是该模型没有考虑局部特征之间的位置关系, 而这个关系对于目标检测与识别是非常重要的, 因为目标是一个整体, 构成目标的局部区域之间不是毫无关系的, 而是按照一定的规律组织的。
另外局部上下文还包括局部区域的邻域上下文 。
目标上下文
目标上下文是指场景中待识别目标与其它物体的共现关系和位置关系。
在神经生理学中, 侧抑制是一个非常重要的机制, 它使得一个兴奋的神经元减少周围神经元的活跃性。侧抑制主要有三个功能, 分别为对比增强、极大值选择以及竞争学习。
在教育界,有这么一句话:“if content is king, then context is queen”(Elliott Masie)(内容为王,情景为后),其中指出:上下文就是使隐含的知识清楚的体现、把最好的实践转化到训练中的东西;因人而异地选择相应的学习对象,应该是通过选择满足相关上下文需求条件的对象,并且使自己的学习对象的行为适应上下文的特殊属性。
Elliott 进一步指出 king 的时代已经过去了,king 徒有其表。而且,king 可以没有 queen,反之亦然,但是 content 不能脱离 context 而存在。实际上 content + context = learning。Jay 认为,content 是内部的,context 是外部的,他们是不可分割的。
上面的观点使我们普遍接受的,但是 Peter Baumgartner 更疯狂的认为 “Context is King!”,因为他认为 content 只是学习环境的另外一部分。我们可以简单的认为广义的 context 是包括 content 的,这也无可厚非。
appearance features VS Contextual features
在计算机视觉中,上下文的重要性也是不言而喻的,上下文可以为确认目标、定位和大小提供丰富的信息,这是一个共识,很多心理学试验也印证了这个观点。一般来说我们所处的世界是有一定结构规律支配的,正如同一个物体内部的情况一样。对于上面的观点,我们可以做同样的推论:appearance features + contextual features = 目标表征,两者共同决定目标是本质,当前者相同后者不同时,目标的表征也可能不同,即相同的东西在不同的上下文所描述的内容是不同的
上下文如此的重要,但是在机器视觉系统中上下文的成分却很少,这是因为人们对上下文的理解多为高层的语义层次的,而 appearance features 则是底层的,两层之间的鸿沟导致计算机视觉系统中上下文的匮乏。然而上下文不一定非得是高层的,最近的研究表明底层的上下文描述非常重要,这样简单有效的上下文描述就是解决途径之一。
From: 高常鑫 的博客,Context is King!
[3] 陈霖院士:三十年改写认知科学权威理论
对于 “知觉过程从哪里开始?先看见树木还是先看见森林?” 这一根本问题的争论从没停止过。在近代的知觉研究中,强调视知觉过程是从局部到整体的初期特征分析的理论路线一直占统治地位。
陈霖的拓扑性质知觉理论,独创性地提出了 “大范围首先” 的拓扑性质初期知觉理论
视知觉乃至认知科学其他领域研究中所遇到的各种根本性困难,可能正是来源于由局部到整体的错误假设。
“大范围首先” 的拓扑性质知觉理论,为知觉组织研究提供了一个科学准确描述的不变性知觉的系统理论。
- 图灵的计算模型,回答了什么是计算的问题,奠定了计算机科学的基础;
- 香农的通信数学原理,回答了什么是信息的问题,奠定了信息科学的基础。
发展新一代人工智能的核心基础科学问题是:认知和计算的关系。
陈霖进一步将认知和计算的关系细化为四个方面的关系:
####(1)认知的基本单元和计算的基本单元的关系
认知的基本单元是知觉 “物体(Object)、组块(Chunk)、时间格式塔(Temporal Gestalt)” 之类的表达。
陈霖认为,“大范围首先” 的知觉物体的拓扑学模型是认知基本单元的理论模型,并就知觉物体的拓扑学定义、空间和时间组织的统一模型展开论述。
知觉物体的拓扑学定义:在形状改变变换下保持不变的整体同一性的拓扑学描述。
视觉过程是从大范围性质开始的,这种大范围性质可以用拓扑性质来描述。而 “知觉物体” 的核心含义在于,在形状改变的变换下仍然保持不变的整体同一性。
如何科学准确地定义 “Chunk” 是目前工作记忆领域最具挑战性、原创性的重大科学问题之一。陈霖提出了 “大范围首先” 的工作记忆基本单元理论。“Chunk” 的核心含义在于,由 “grouping”,“belongingness”,“what goes with what” 形成的整体性。
体现在不同认知层次的基本单元(如知觉物体、组块、时间格式塔等)的共同本质 —— 同一性和不变性,可以定义为容限空间上的大范围拓扑不变性质。陈霖指出,各个认知层次(包括知觉、注意、学习、记忆、数的认知、发展和进化、情绪、意识)的实验,一致支持了 “大范围首先” 的认知基本单元拓扑学定义。
(2)认知神经表达的解剖结构和人工智能计算的体系结构的关系
大脑是由结构和功能相对独立的多个脑区组成的。这种模块性的结构,不同于计算机的中心处理器和统一记忆存储器的体系结构。(电脑是中心化决策,大脑是多模块各自决策)
(3)认知涌现的特有精神活动现象和计算涌现的特有信息处理现象的关系
(4)认知的数学基础和计算的数学基础的关系
[4] “ 大范围优先” 对象形成的神经关联: 前颖叶
陈霖院士 08 年在《生命科学》上的论文。
知觉对象是什么? “ 大范围优先” 的拓扑学方法把知觉对象的定义严格地联系到拓扑变换下的不变量。 知觉对象的直观概念 —— 形状改变时其整体一致性得以保持 —— 可以精确地被拓扑不变量 , 如连接组分和洞 , 所刻画。
功能磁共振成像实验揭示, 前颜页区参与拓扑知觉和知觉对象的形成, 而这一脑区本来是形式视 觉通路的终点。 行为学上 “ 大范围优先” 的结果与视觉通路神经解剖学结果的悖逆 , 提示我们应该 注怠对象表征形成的问题和更广泛的意义上, 知觉到底在何处发生的基本问题。(我想这里的 悖逆 指的是 生理上负责大范围优先的脑区位于视觉通路的终点,而在行为学上,大范围优先应当是最早发生的)
英文标题里 陈霖院士是把 大范围优先翻译成 global first 的,这是全局优先
最基本的问题则在于, 认知过程运作的基本单元是什么?
[5] The role of context in object recognition
Aude Oliva 和 Antonio Torralba 07 年在 TRENDS in Cognitive Sciences 上的综述。
为什么 context 有用的原因在于:In the real world, objects never occur in isolation; they co-vary with other objects and particular environments, providing a rich source of contextual associations to be exploited by the visual system. 我想本质就是 objects never occur in isolation 吧,存在一种 co-vary 关系。那问题来了,有 occur in isolation 的物体吗?如果有,那也可以用其他都有 contextual associations 而它没有来刻画?
要让 context 帮助 object recognition 的第一步应该是如何表示 context。目前表示 context 的方式有两种,一种是 object relationship to other objects,另一种是 a statistical summary of the scene。
因为作者是 Gist 和 SPM 的提出者,因此作者最后对如何利用 context 帮助 object recognition 的途径上的落脚点是 a statistical summary of the scene provides a complementary and effective source of information for contextual inference(也就是 Gist、SPM),而 statistical summary 的确能够起到帮助也有其生理基础,a statistical summary 能够 enables humans to quickly guide their attention and eyes to regions of interest in natural scenes
常用的 object recognition 方法是拒绝 background features 的,因为它们认为 the context of a target is a random collection of distractors that serve only to make the detection process as hard as possible. 然而,在现实世界的人类视觉中,context 是 a rich source of information,can serve to help 而不是 hinder the recognition and detection of objects。
这篇文章的结构大体如下:
- Contextual influences on object recognition -> 表明 context 有用,会有助于物体识别
- The effects of context -> context 是怎么影响物体识别的?
- Implicit learning of contextual cues -> 怎么隐式学习 context 的暗示, human observers have a remarkable ability to learn contextual associations. Observers do not need to be explicitly aware of contextual associations to benefit from them. 告诉读者 人有很强的 隐式学习 context 的能力,也就是说 context 不必被显式建模、刻画成 contextual associations
- Perception of sets and summary statistics -> 说明人类视觉感知中,编码 statistical summary 是先于 编码 individual elements 的,举了几个例子,这为后面作者用 statistics 去刻画 Global context 提供了支撑(statistical summary 先行对应为什么要编码 global,人脑也用 statistical summary 对应 用最后得到的 global 特征 )
- 展示了一堆 a statistical summary
- Global context: insights from computer vision -> 通过一些现有的方法展示了一下 summary representations 能够用来 encoding the structure and meaning of natural images
- Contextual effects on eye movements -> 感觉是针对 eye movements 重述了一遍 The effects of context
Contextual influences on object recognition
Contextual 会 influence 哪些?
- contextual information affects the efficiency of the search and recognition of objects
这背后的生理现象是 objects appearing in a consistent or familiar background are detected more accurately and processed more quickly than objects appearing in an inconsistent scene.
The structure of many real-world scenes is governed by strong configural rules similar to those that apply to a single object.
之所以会有 object relationship to other objects 背后的原因在于 The structure of many real-world scenes is governed by strong configural rules
决定 The structure of many real-world scenes 的 strong configural rules 其实是既决定了 object relationship to other objects (目标上下文),也同时决定了 the Scene structure (场景全局上下文)
object relationship to other objects (目标上下文)具体表现为 The presence of a particular object constrains the identity and location of nearby objects
Contextual influences on object recognition become evident if the local features are insufficient because the object is small, occluded or camouflaged. (本身特征不足的时候,就是用上下文的时候了)
The effects of context
context has effects at multiple levels:
- semantic,举例:a table and chair are prob- ably present in the same images, whereas an elephant and a bed are not(一起出现与否 whether)
- spatial configuration,举例 e.g. a keyboard is expected to be below a monitor(一起出现在哪里 where?)
- pose,举例 a car will be oriented along the driving directions of a street
the perception of one object or scene to generate strong expectations about the probable presence and location of other objects
the relative pose of pairs of objects
scene consistency–inconsistency effect 指的是 observers’ accuracy at an object-categorization task was facilitated if the target was presented after an appropriate scene and impaired if the scene–object pairing was inappropriate.
这个效应背后的原因在于 consistency information influences perception of both the object and the scene background if a scene is presented briefly (80 ms), which suggests a recurrent processing framework, in which objects and their settings influence each other mutually (这表明做 Inference 的时候其实不是简单的 Forward,还是有 feedback 的)
object–scene relationships
context provides a robust estimate of the prob- ability of an object’s presence, position and scale.
Implicit learning of contextual cues
contextual learning, the paradigm of contextual cueing offers an interesting framework to determine which properties of the background provide informative context.
Mechanisms of contextual influences
At which level in the processing stream does contextual information have a role?
一种认为是 Contextual effects are mediated by memory representations by preactivating stored representations of objects related to the context. Recognizing a scene context (e.g. a farm) enables an informed guess about the presence of certain classes of objects (e.g. a tractor versus a squid), in addition to their location and size.
另一种是 Context changes the perceptual analysis of objects. Contextual effects occur early, at the perceptual level, facilitating the integration of local features to form objects [1–3,12]. These models suggest that even the way in which the image is analyzed is affected by context. (context 先于 local feature 整合)
还有一个事情是 the extent that context affects the speed at which attention is deployed towards the target [26,34], alters target analysis [35] or biases response selection (context 不仅仅影响 recognition 的准确度,还影响 recognition 的 速度,而影响 recognition 速度的方式是 deploy Attention)
contextual associations 会让 observer 看东西的时候会 rely on memory search, instead of visual search,when looking for objects in familiar scenes(这样就会快很多)
Perception of sets and summary statistics
采用 object-to-object associations 来作为 context representation 背后的假设为 treats objects as the atomic elements of perception. It is an object-centered view of scene understanding.
Gist 是 a cruder but extremely effective representation of contextual information
the representation of an object can be mediated by features that do not correspond to nameable parts(global context feature 作为 object feature 一部分的特征)
the representation of the scene context can also be built on elements that do not correspond to objects(global context 的想法,抛弃掉 object-to-object associations,抛弃 object-centered view of scene understanding),为这种抛弃提供生理支撑,所以才有的这个 section,主要是想讲 humans encode statistical properties from a display instead of encoding the individual elements that compose a display
举了 Average size 先于 individual size,center of mass 这样两个例子,就是想说 a statistical summary of an image influences local object processing (a statistical summary 也是一种 global context,也就是收 global context 不一定非要特别高层语义的,也可以是 low level 的 statistical summary)summary representations for encoding the structure and meaning of natural images
Global context: insights from computer vision
One of the main problems that computational recognition approaches face by including contextual information is the lack of simple representations of context and efficient algorithms for the extraction of such information from the visual input.
including contextual information 最难的手段在于 怎么去做 representations of context?
global scene representations as sources of contextual information (scene recognition 里会用 global scene representations)
Box 2 里面的 global scene representations 是通过 statistics of low-level features over fixed image regions
global scene representations 作为 global features 能够 provide strong contextual priors
Because object information is not explicitly represented in the global features, they provide a complementary source of information for scene understanding, which can be used to improve object recognition. (为什么 global features 是另一种 complementary source)
Contextual effects on eye movements
When exploring a scene for an object, an ideal observer will fixate the image locations that have the highest posterior probability of containing the target object according to the available image information.
Attention can be driven by global scene properties and salient objects contextually related to the target.
Most scenes can be recognized by just a glance, even before any eye movements can be initiated and without requiring foveated vision to scrutinize the image(这个实验表明 整体 先于 局部,the scene content will have an immediate effect in the planning of subsequent eye movements,context will direct attention to the only image regions for which the target will have the appropriate role,也就是说 context 会 direct attention)
contextual information will provide additional cues in cases of image degradation,result- ing in an increase in detection
context 的作用,not only accuracy, but also attention(sequence)(Global context effects in attention deployment,make use of contextual information to direct attention to the most probable target location)
Saliency models can be enhanced by introducing task constraints and a context model
- The local pathway represents each spatial location independently and is used to compute image saliency and perform object recognition on the basis of local appearance.
- The global pathway represents the entire image by extracting global statistics from the image (Box 2) and is used to provide information about the expected location of the target in the image.
Concluding remarks
In the absence of enough local evidence about an object’s identity, the scene structure and prior knowledge of world regularities might provide the additional information needed for recognizing and localizing an object.(为什么在 image degradation 的时候 context 能够帮忙的原因在于 scene structure 和 world regularities)
Even if objects can be identified by intrinsic information, context can simplify the object discrimination by decreasing the number of object categories, scales and positions that must be considered. (即使 intrinsic information 足够,context 也可以用来缩小 search Space)
[6]【VALSE2018】浙江大学吴飞_记忆驱动的智能学习
之前看过李德毅院士的一个报告,知道记忆很重要,但对于记忆怎么运用很模糊,这篇报告稍微清楚了一点
瞬时记忆 只有被 注意力感知到 才可以变成 工作记忆,然后工作记忆跟长期记忆交互有望变成长期记忆
智能是对外界所产生的认知和决策,我目前做的是认知,而对于决策没有涉及,目前机器学习基本上就是默认决策论里的max utility为唯一最优解然后开发具体方法
瞬时记忆:多通道感知,持续时间小于 5 秒
工作记忆:直觉、顿悟、因果等推理,持续时间小于 30 秒
长期记忆:先验、知识等,持续时间 1 秒 - lifelong
以前 分段学习,每个阶段可灵活引入先验、经验与知识,但并不知道所引入信息的合理性
现在 端到端学习,数据说话,但缺乏了人类语言可表述的 “interpretability”
从图灵机到神经图灵机:利用外在记忆体中的知识(以前 分段学习 是 人把自己的知识嵌到算法里,现在还是要算法自动去激活外在的知识),利用外在记忆体中的知识进行可计算推理
不止是单纯追求将浅层模型拓展到深层模型,更重要的是,在这个转变过程中,巧妙融合数据、知识和交互经验,多种手段和方法的综合利用
游戏哦啊利用当前数据、已有知识和未知交互的挑战:
- 知识表达模型:逻辑、描述、事实型知识的表示方法,从离散符号到分布式向量表示,为深度神经网络推理打下基础
- 记忆激活机制:编码(形成新的记忆)以及记忆检索(回想过去)的机制,即实现模式分离和模式完成
- 交互更新手段:通过人-机交互、机-机交互等形式,或者利用认知模型、或者借助自我博弈,进行知识更新(GAN 就是自我博弈的一种吧)
数据 <=> 记忆 <=> 交互
我的认知里,怎么融入外部记忆(知识)可以算是 Meta-Problem 了,说 Meta 的意思是可以用在 自然语言处理、图像理解 各种用途
跨媒体综合推理:
- 数据驱动中归纳,知识涌现
- 知识指导下演绎,推理学习
- 行为强化内规划,经验探索
自顶向下的知识指导(推理)
自底向上的数据驱动(感知)
实现可解释、更鲁棒和更通用的人工智能:数据利用、知识引导和能力学习
数据驱动的机器学习方法 - 先验与知识引导
- 从浅层计算到深度神经推理
- 从单纯依赖于数据驱动的模型到数据驱动与知识引导相互结合
- 从领域任务驱动智能到更为通用条件下的强人工智能(从经验中学习)
[7] Using the Forest to See the Trees: Exploiting Context for Visual Object Detection and Localization
Torralba、Murphy、Freeman 三位大神 2010 年的 Communications of the ACM, Research Highlights
Sliding Window Approach 的缺点:detecting objects perform an exhaustive search across all locations and scales in the image comparing local image regions with an object model;而之所以只能这么盲目的 exhaustive search 是因为这些方法 ignores the semantic structure of scenes 所以只能 solve the recognition problem by brute force
而 context 之所以能够 providing a rich collection of contextual associations 的原因在于 In the real world, objects tend to covary with other objects
利用好这些 contextual associations 的好处是:
- reduce the search space by looking only in places in which the object is expected to be;
- increases performance, by rejecting patterns that look like the target but appear in unlikely places.
defined the context of an object in terms of other previously recognized objects 这种做法的缺点是 inferring the context becomes as difficult as detecting each object
另一种做法是 using the entire scene information holistically(a prior step of individual object recognition)
作者用了一个很形象的词 “近视 myopic”来形容那些 only look at local features of the image 的方法,认为 近视 是这些方法 the relatively high false alarm rate of standard approaches 的原因。一种补救办法是 leverage global features of the image,and to use these to compute the “prior” probability that each object category is present, and if so, its likely location and scale.
作者说 “gist” of the image 已经足够可以 provide robust predictions about the presence and location of different object categories,我有点怀疑,gist 不是用来做场景分类的全局特征向量的么,能够产生 prior probability map 吗?
对于 global context 用来做场景识别而不是 识别出 object 后根据 object 之间的关系来做场景识别的依据,作者除了在上一篇综述里给出在生理上 人能够在一瞥的时间、来不及运用 foveated vision 的时间内识别出场景以此说明人的视觉是整体先行的,也拉了现在的 object Detector 来为自己正名,an object can be recognized without decomposing it into a set of nameable parts,举例:the most successful face detectors do not try to detect the eyes and mouth first, instead they search for less semantically meaningful features。因此 scenes can also be recognized without necessarily decomposing them into objects
但是 gist 这样的 global scene representations (这里作者把 global scene representations 和 global context Representation 认为是一样的,scene 应该是 global context 的一种)是基于 statistics of low level features
gist 这样的 global context feature 不仅仅可以用来做 Scene Classification(这是 Classification),还可以用来做 object presence detection (这是 Binary Classification),还可以做 object counting(用 Regression 来做),还可以做 object localization (用 GMM 这么一个 Generative model 来做,generative model 最后能生成一个 map 啊)
把 limit search space 叫作 location priming,作用是 down-weighted the scores of the detections in improbable locations, thus eliminating false positives
The basic idea is to use the global features to make “top-down” predictions about how many object instances should be present, and where, and then to use the local patch classifiers to provide “bottom-up” signals.
[8] Contextual guidance of eye movements and attention in real-world scenes: The role of global features on object search
human visual system makes extensive use of contextual information for facilitating object search in natural scenes
However, the question of how to formally model contextual influences is still open.
本文做的是 an approach of attentional guidance by global scene context
top-down mechanisms at an early stage of visual processing
sliding window Approach 背后的思潮应该是 feature-integration theory (Treisman & Gelade, 1980),认为 the search for objects 需要 slow serial scanning since attention is necessary to integrate low-level features into single objects.
自底向上的 Saliency 机制工作好的前提是 the image itself provides little semantic information and when no specific task is driving the observer’s exploration
但在 real-world images 中,the semantic content of the scene, the co-occurrence of objects, and task constraints 这三个都扮演了很大的分量
the violation of typical item configuration slows object detection in a scene 说明人类视觉里存在 location priming 现象/功能,而且这个 location priming 是被 global property 驱动的(Observer’s can also be implicitly cued to a target location by global properties of the image)
Global context can thus benefit object search mechanisms by modulating the use of the features provided by local image analysis.
contextual information can be integrated prior to the first saccade, thereby reducing the number of image locations that need to be considered by object-driven attentional mechanisms.
early scene interpretation may be influenced by global image properties that are computed by processes that do not require selective visual attention(这个就很致命了,意思是 global 先于 selective visual attention)
Top-down control is represented by the specific constraints of the search task and it modifies how global-context features are used to select relevant image regions for exploration.(从这里看出,task、global context, local feature 是三种不同的信息)
scene context can be built in a holistic fashion, without recognizing individual objects
global context 难以利用在于 the high dimensionality of the input image I
One common simplification is to make the assumption that the only features relevant for evaluating the probability of target presence are the local image features.(这是 local features 背后的 Assumption,而采用 local features 的原因在于 the high dimensionality of the input image 难以利用)
The role of the scene context is to provide information about past search experiences in similar environments and strategies that were successful in finding the target.(那么问题来了,刻画 scene context,也就是在刻画 past search experiences in similar environments and strategie)
显著性检测的假设:locations with different properties from their neighboring regions are considered more informative and therefore will initially attract attention and eye movements
the intuition that repetitive image features are likely to belong to the background whereas rare image features are more likely to be diagnostic in detecting objects of interest
检测问题的表示只能是 $p(O,X|L,G)$,因为检测是要你告诉我,给定的图像里面,目标有没有,有的话在哪里?
目标有没有其实是 $p(O = 1|L,G)$,目标在哪里其实是 $p(X |O = 1, L,G)$,因此检测问题表示成 $p(O,X|L,G) = p(X |O = 1, L,G) p(O = 1|L,G)$
其中 $p(O = 1|L,G) = p(L | O = 1, G) \frac{1}{p(L/G)} p(O = 1 | G)$
$p(O = 1, X |L,G) = p(L | O = 1, G) \frac{1}{p(L/G)} p(X |O = 1, L,G) p(O = 1 | G)$
Sliding Window Approach 的思路其实是 $p(O = 1, X | L, G) = p(O = 1 | X, L, G) p(X | L, G)$,其中 $p(O = 1 | X, L, G)$ 表示指定窗口中含有目标的概率,是否含有目标,而 $p(X | L, G)$ 是一个 sampling 函数,取窗口的,通常都默认是一样的,都为 1
如果计算 $p(O = 1 | X, L, G)$ 的复杂度要远远高于 $p(X | L, G)$,则有很大的动力先做 $p(X | L, G)$ 如果概率高,则再进一步计算 $p(O = 1 | X, L, G)$,这其实就是 Region Proposal Network 的思想(或者所有 Two-Stage 方法的思想,应该说这就是 Region Proposal 来做 Detection 的方法的基础)
如果 $p(O = 1 | X, L, G)$ 和 $p(X | L, G)$ 两者计算复杂度一样,比如 $p(O = 1 | X, L, G)$ 后续不再做特征变换,则就会冒出来 Chicken-Egg Problem
[9] Salient Object Detection via High-to-Low Hierarchical Context Aggregation
24 Jan 2019 被挂在 arXiv 上,不知道投哪
Introduction
we observe that the contexts of a natural image can be well expressed by a high-to-low self-learning of side-output convolutional features(a natural image 的 context 的表示方式,a high-to-low self-learning of side-output convolutional features)
the contexts of an image usually refer to the global structures, and the top layers of CNN usually learn to convey global information
it is difficult for the intermediate side-output features to express contextual information(为了解决这个问题,design an hourglass network with intermediate supervision to learn contextual features in a high-to-low manner)
intermediate side-output features 和 the top layers of CNN 构成 the hybrid contextual expression
用 CNN 的 Hierarchical features 来表示特征的论文很普遍啊,本文跟其他论文有什么不同?本文把这种方式跟 Context 挂上钩的支撑理由在哪里?
current state-of-the-art saliency detectors mainly aim at designing complex network structures to fuse the features (指的是 Hypercolumn) or results from various side-outputs(指的是 SSD 那种的)
作者说 CNN can learn global contextual information for input images at top convolution layers by enlarging receptive fields 这一点没有被 saliency detection 运用过很奇怪诶?这个跟上面 fuse the features 有什么区别?作者给的理由是 because saliency detection requires not only global contextual information but also local spatial de- tails.
本文的 constructing hierarchical contextual features 和 fusing side-output features 有什么区别?本文的具体做法是 flow global contextual in- formation obtained at top sides into bottom sides;The top contextual information will learn to guide the bottom sides to construct the contextual features at fine spatial scales only emphasizing salient objects(这是模拟自上而下的反馈机制?)因此,本文得到的 context 是不同于 side-output features or some combinations of them 的,因为自上而下的本质上都是 local representations for an image
本文的 constructing hierarchical contextual features 和 FPN 有什么区别?
Related Works
Heuristic saliency detection 的缺点
Heuristic saliency detection 通常是 extract hand-crafted low-level features and apply machine learning mod- els to classify these features
会利用一些 heuristic saliency priors 来 ensure the accuracy,比如 color contrast、center prior、background prior
缺点是:it is difficult for the low-level features to describe semantic information, and the saliency priors are not robust enough for complicated scenarios
Region-based saliency detection
These approaches view each image patch as a basic processing unit to perform saliency detection
classify candidate regions as salient or not
The low-level features are compared with other parts of an image to form a distance map that is then encoded by the CNN(和其他比,)
CNN-based image-to-image saliency detection
Context learning
文章把 Context Learning 归结到 semantic segmentation
[58] added a pyramid pool- ing module for global context construction upon the final layer of the deep network, by which they significantly im- proved the performance of semantic segmentation.
[52] built context encoding module using the encod- ing layer [9] on the top of neural network to conduct ac- curate semantic segmentation
[59] pro- posed a global context module and a local context module to extract the global and local contexts
Salient object detection usually requires global information to judge which objects are salient(仅仅依赖局部特征对比度是不够的)
这篇论文是 28 Dec 2018 提交的,但是没有看到作者讨论跟 FPN 的区别,我感觉这里面的 MLHN 就是 FPN 啊,FPN 和 SegNet 那种又有什么区别?
intermediate Supervision 到底指的是什么?
这里的 FCN-Style 说的就是 FPN,不是的,作者这里提出的 MLHN 我觉得就是 FPN
我感觉本文就是 FPN + Hypercolumn
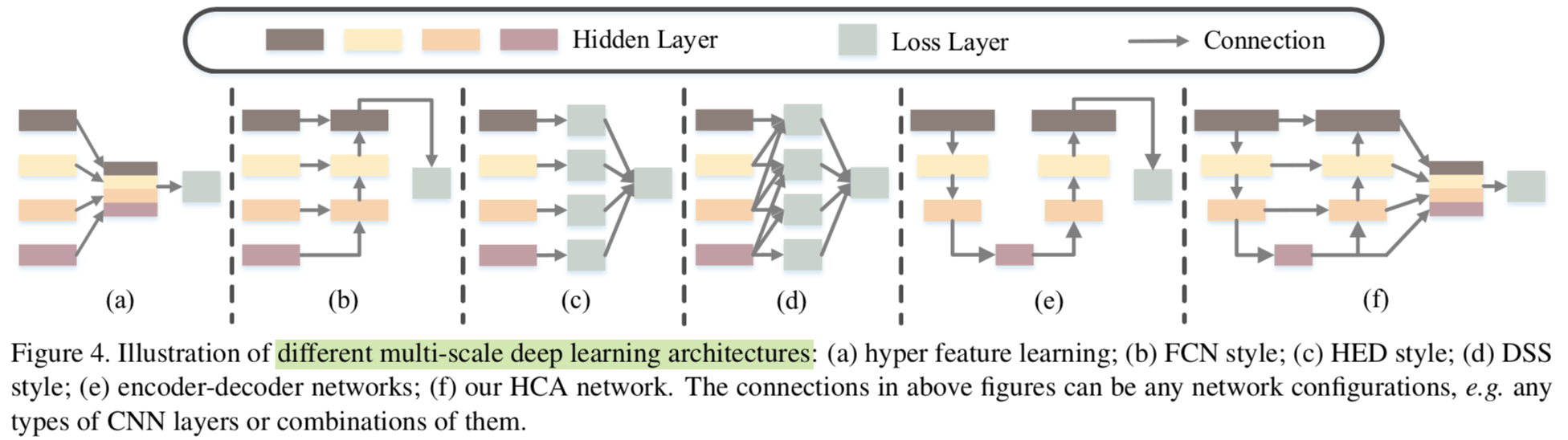
图 4 蛮好的,概括了 different multi-scale deep learning architectures,但是我觉得作者应该给 hyper feature learning 也花上向下的箭头(我猜作者是要强调 hyper feature learning 里面高层小的 feature map 是要插值得到,而这里作者是 autoencoder 方式增长得到的)
作者本文的卖点是 gradually flows the top global contexts into lower sides to obtain hi- erarchical contexts,这里面 global contexts 就是用 CNN 的 top features 来表示,本质就是用一个 FPN 来实现的
[10] Deep Reasoning with Multi-scale Context for Salient Object Detection
这篇文章要说的就是 enhance the ability of the “Saliency Reasoning” module 对于检测性能很重要
Related Works
To detect and segment salient objects accurately, existing methods are usually devoted to designing complex network architectures to fuse powerful features from the backbone networks.(跟上一篇论文的讲法一样啊)
However, they put much less efforts on the saliency inference module and only use a few fully convolutional layers to perform saliency reasoning from the fused features (inference 不就是 Prediction 么,不就是 conv 的输出么,作者要强调什么?)
传统方法的缺点:utilize hand-crafted features and heuristic clues, which are hard to describe high-level semantic objects and scenes.(手工特征没法表述具有高层语义的物体和场景)
作者认为 FCN-based saliency detectors 由 3 部分组成:
- backbone: The backbone network usually produces a set of feature maps with decreasing spatial resolution.
- feature fusion: The feature fusion component aims to enhance these hierarchical features to better capture both distinctive objectness and local detailed information for detecting salient regions
- saliency prediction: detectors predict saliency labels through two steps: one is saliency reasoning that is simply used for refining hierarchical features with a few fully convolutional layers; the other is a 1 × 1 convolution for differentiating saliency foreground and background parts.(看来多尺度特征融合好后还要经过几个 conv 非线性变换后才去做 1 × 1 convolution)
绝大部分工作都在改进 feature fusion,但作者认为如果你不改进 第三步 reasoning (saliency prediction),第 2 步做得再好性能也会饱和的,所以要改进第三步
其实也有改进第三步的工作,[3][35] propose to use graph convolution to do the relation reasoning, while [20] propose to introduce second order terms to enhance the learning capacity of the network. 但作者认为这些太复杂了,complicated and may require some non-trivial modifications
作者提出的策略是 adopt a more straightforward solution by stacking convolution layers to build a deeper and larger saliency reasoning module(就是在特征融合后多堆几层 conv 层增强推理模块的能力)
However, should feature fusion strategies receive much attention but saliency reasoning be ignored a lot?(作者点出现状的问题,feature fusion strategies receive much attention 而 saliency reasoning be ignored a lot)
本文工作 find that weakness of the saliency reasoning unit limits salient object detection performance, and claim that saliency reasoning after multi-scale convolutional fea- tures fusion is critical
作者怎么做到?To verify our findings, we first extract multi-scale features with a fully convolutional network, and then directly reason from these comprehensive features us- ing a deep yet light-weighted network, modified from Shuf- fleNet [45], to fast and precisely predict salient objects. Such simple design is shown to be capable of reasoning from multi-scale saliency features as well as giving superior saliency detection performance with less computation cost. 你这个跟 Reasoning 有什么关系?
[11] M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
AAAI 19 的文章,本质上是提出了一种新的 Feature Pyramid 用于克服 Object Instance 的 Multi-scale Variation,跟其他 Feature Pyramid 的区别下图 Fig. 1 概括的很形象
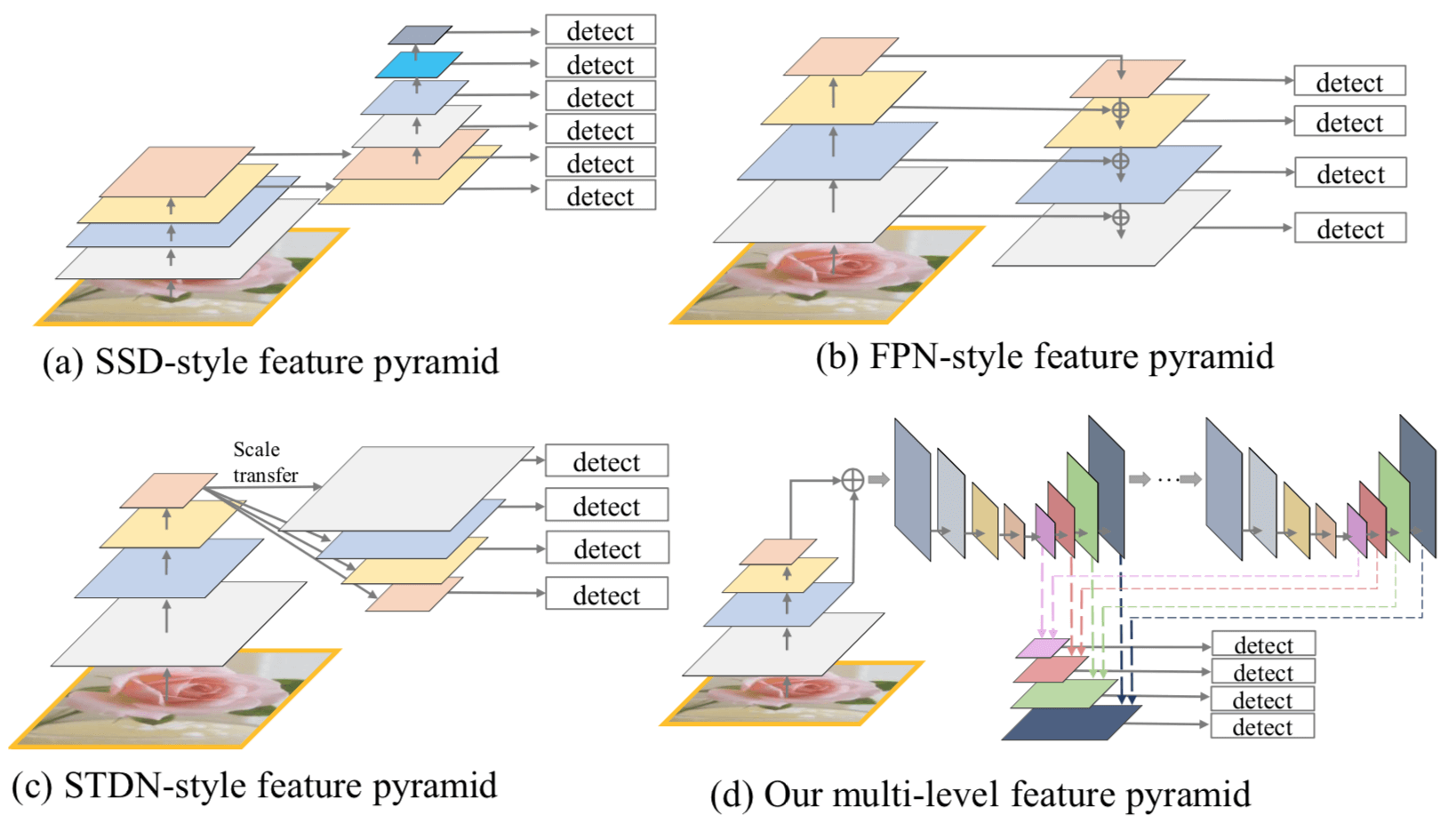
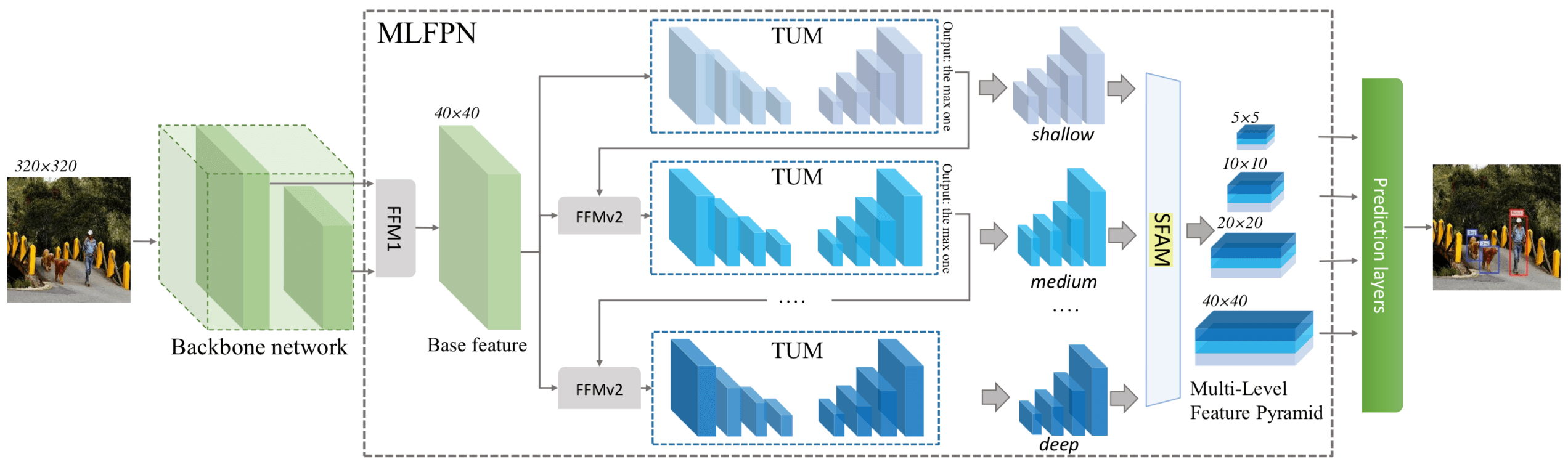
作者提出的这个新的 FPN 叫作 MLFPN,本文提出的 Object Detection 方法 M2Det 其实就是把这个 MLFPN 用于 Single-shot Detector 了(本质就是 Single Shot Detector = Feature Pyramid + Prediction(也就是最后一个 conv)),M2Det 具体示意图如下:
作者认为现有基于特征金字塔的方法的缺点就在于用了 Object Classification 的 Backbone 来构建特征金字塔: they only simply construct the feature pyramid according to the inherent multi-scale, pyramidal architecture of the backbones which are originally designed for object classification task ()
本文算法步骤:
- First, we fuse multi-level features (i.e. multiple layers) extracted by backbone as the base feature.
- Second, we feed the base feature into a block of alternating joint Thinned U-shape Modules and Feature Fusion Modules and exploit the decoder layers of each U- shape module as the features for detecting objects.
- Finally, we gather up the decoder layers with equivalent scales (sizes) to construct a feature pyramid for object detection, in which every feature map consists of the layers (features) from mul- tiple levels.
作者说了 SSD、FPN 这些方法的缺点
- First, feature maps in the pyramid are not representative enough for the object detection task, since they are simply constructed from the layers (features) of the backbone designed for object classification task. (Object Detection 需要专门为 Object Detection 设计的 Backbone,而不只是从 Image Classification 里面借来)
- Second, each feature map in the pyramid (used for detecting objects in a specific range of size) is mainly or even solely constructed from single-level layers of the backbone, that is, it mainly or only contains single-level information. (solely 喷的是 SSD 吧,mainly 喷的是 FPN 呢,意思是 FPN 的 top-down 只是稍微改变一点而已)
总而言之作者的落脚点是 mainly or only consists of single-level features 不好
本文的方法叫作 M2Det,多尺度特征抽取和融合的部分叫作 Multi-Level Feature Pyramid Network (MLFPN)
MLFPN 包括 3 个部分:
- Feature Fusion Module (FFM):FFMv1 负责 enriches semantic information into base features by fusing feature maps of the backbone;FFMv2s 负责
- Thinned U-shape Module (TUM) :负责 generates a group of multi-scale features, and then the alternating joint TUMs and FFMv2s extract multi-level multi- scale features
- Scale-wise Feature Aggregation Module (SFAM):负责 aggregates the features into the multi-level feature pyramid through a scale-wise feature concatenation operation and an adaptive attention mechanism
FFMv1 这个 fuse Module 怎么构成的,怎么实现的? FFMv1 的输入是 大小不同的多尺度特征,但输出的 base Feature 是一个大小一样的 cube;所以 FFMv1 的操作如下,Fig. 4 (a) 画出来了
- 首先,use 1x1 convolution layers to compress the channels of the input features
- 然后,adopts one upsample operation to rescale the deep features to the same scale before the concatenation operation
- 最后,use concatenation operation to aggregate these feature maps
FFMv2 的两个输入的尺寸是一样的,只对 base Feature 的输入用 conv 做 Channel 变化,然后把上面的 TUM 的输出一起 concat 来就可以了
以前像 SegNet,只有一个 Encoder-Decoder,而 MLFPN 这里有 3 个 Encoder-Decoder,也就是 TUM
FFMv1,FFMv2,TUM 的具体组成如下图所示
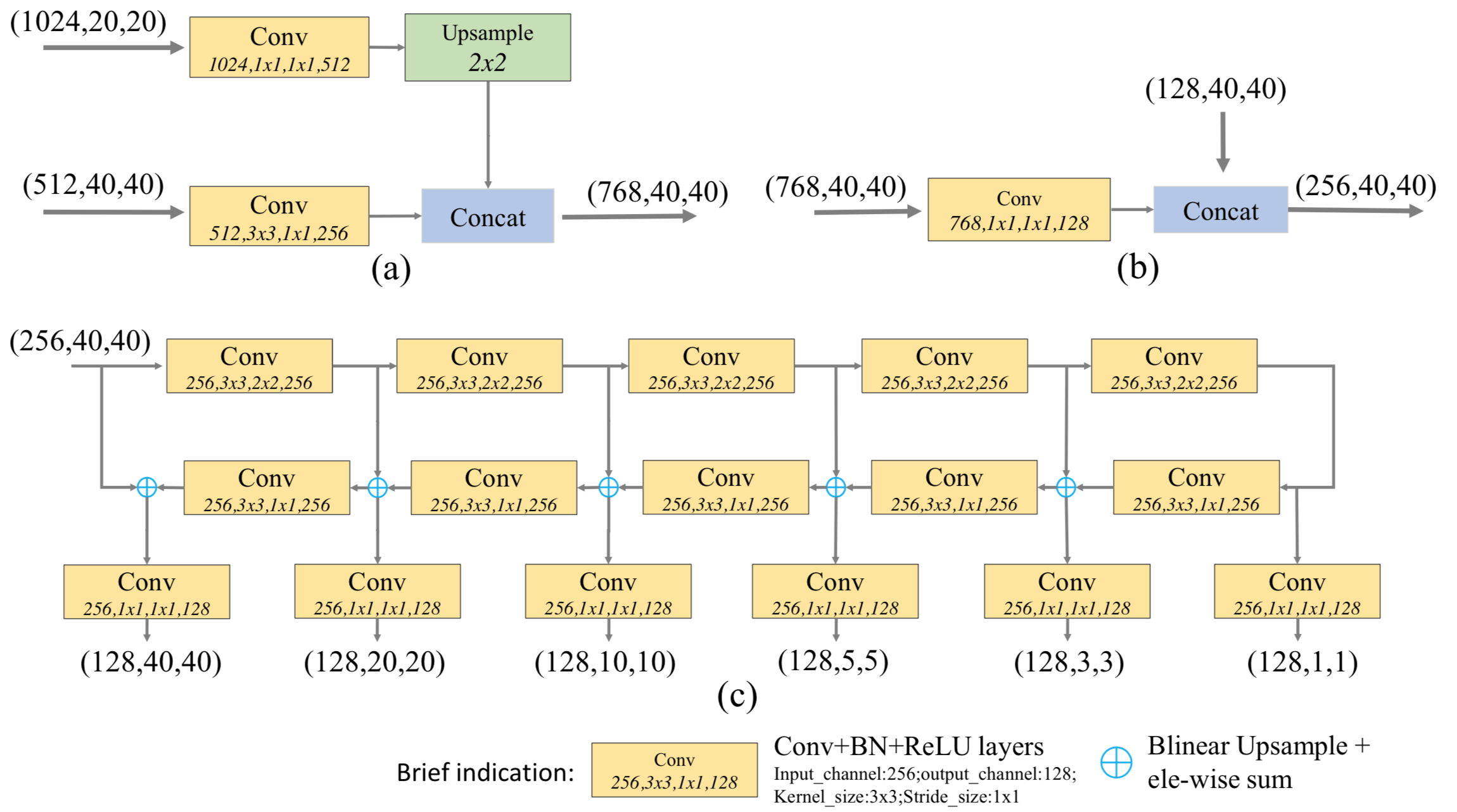
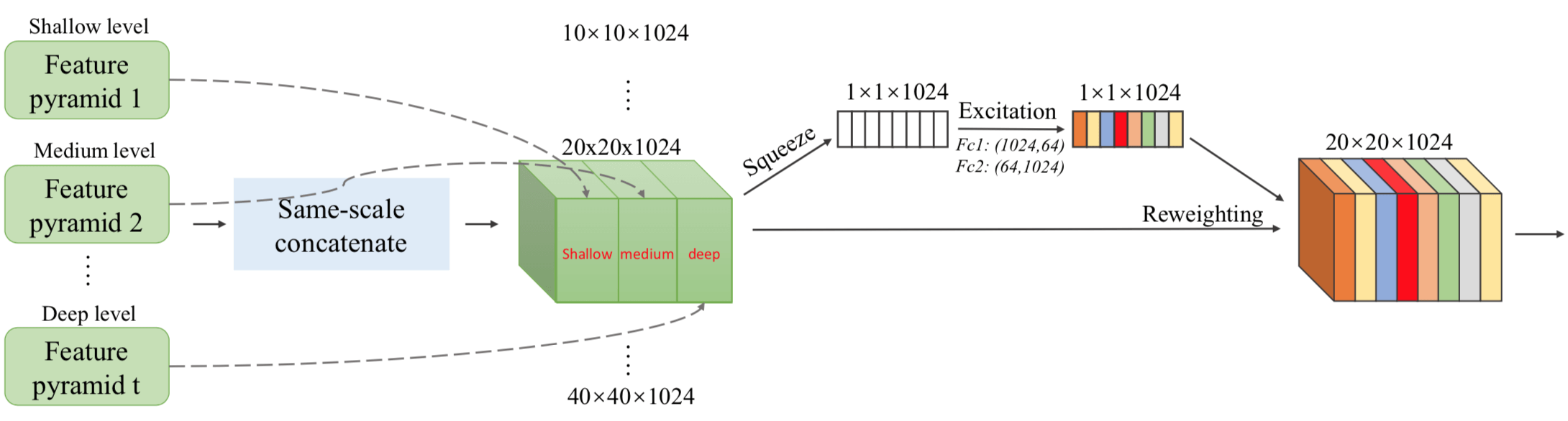
Scale-wise Feature Aggregation Module (SFAM) 其实就是把 3 个 Encoder-Decoder 尺寸一样的 Feature Map 拼起来了(aggregates the features into the multi-level feature pyramid through a scale-wise feature concatenation operation and an adaptive attention mechanism. 前面可以理解,但是 an adaptive attention mechanism 是什么?哦哦,就是 SE-Block,把同等尺度的拼起来后做 SE Operation,最后的 Prediction 是在这些拼起来的同样大小且做过 SE Operation 的 block 上做 ),具体如下所示:
这 3 个 Encoder-Decoder 的 TUM 其实是在进一步深加工 Multi-scale Feature,这里 Multi-scale Feature Fusing 做了两次,一次是 FFMv1,另一次是 SFAM;TUM 可以看做想 FPN 那样的 Top-down feedback
high-level features 的好处:
- more discriminative for classification subtask
- appropriate for objects with complex appearances
low-level features 的好处:
- helpful for object location regression sub-task
- more suitable to characterize objects with simple appearances
[12] R2-CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images
本文网络由 4 部分构成
- backbone Tiny-Net:用来抽特征
- intermediate global attention block:抽取 Patch 的整体特征,用来判断 Object Presence
- final classifier:判断 Object Presence,也就是是否含有目标
- detector:如果 classifier 判断出含有目标,再检测出目标在哪?
GF-1 images 高分一号,18000 × 18192 pixels, 2.0m resolution
GF-2 images 高分二号,27620 × 29200 pixels, 0.8m resolution
Object detection in large-scale remote sensing images 的难点:
- Firstly, the scale of input image is too large to reach practical application. The computation time and memory consumption are increased quadratically, making it too slow and not runnable on current hardware.(单张图像太大,没法直接输入,内存不行)
- Secondly, massive and complex backgrounds appear in real scenario may introduce more false positives.(背景复杂,容易虚警)
- Moreover, the performance drops drastically with tiny objects (such as 8-32 pixels), especially in low-resolution images, which further increases the difficulty of tiny object detection in remote sensing images.(tiny objects 存在,检测很难)
对于第一个难点,本文是 first crops large scale images with a much more smaller scale (such as 640×640 pixels) with 20% overlap to tackle the over- sized input size.
作者把这种 先做 Presence Classification 然后做 Detection 的方式叫作 self-reinforced architecture,之所以这么叫原因大概是 The classifier and detector are mutually reinforced each other under the end-to-end training framework.
这个 self-reinforced architecture 的好处、Motivation 如下:
- Since in large-scale remote sensing images most crops do not contain valid target, so that about 99% of the total patches do not need to pass the heavy detector branch. The light classifier branch can filter out blank patch without more heavy detector cost.
- As most false positives commonly occurs with massive backgrounds, benefit from the self-reinforced framework, the classifier can identify the difficult situation even when there is only one tiny objects in the patch given the fine-grained features from detector. On the other hand, detector receives less false positive candidates since most of them are filtered out by classifier. Even if the patches are distinguished incorrectly by classifier, the detector can still rectify the results later.
由下图(图 1)所示,本文方法一共是 4 个模块,文章也分别在这 4 个模块上各做了创新(工作量)
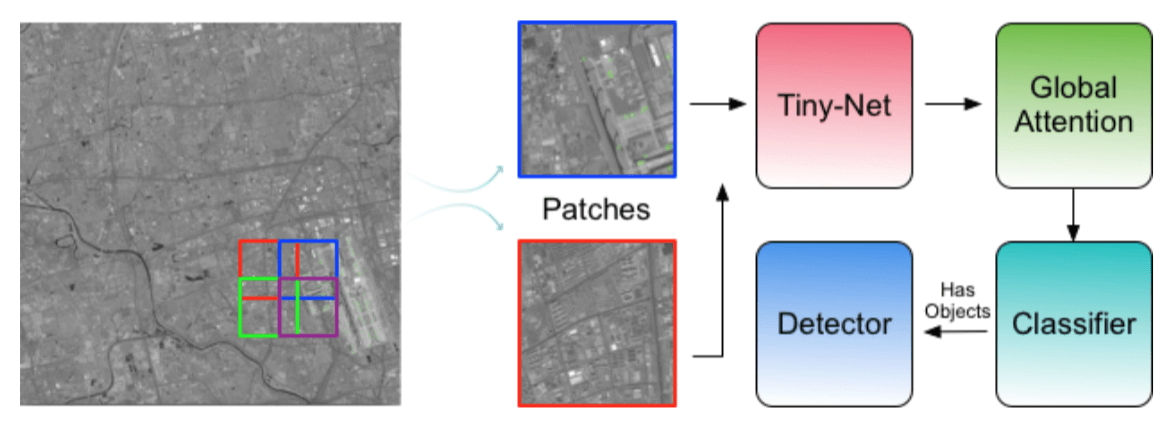
- 对于 Classifier,作者把这个叫作 a unified and self-reinforced framework,好处上面都讲了
- 对于 Tiny-Net,这个是作者为了这个 Task 设计的 a lightweight residual network
- 对于 Global Attention,动机是为了 通过 context 的帮助来减少虚警,而这个 context 是通过 enlarge the receptive field to the whole image 实现的,具体的做法是 The feature maps are firstly pooled in different pyramid levels, such as 1×1, 2×2, and 4×4. Then we recover the pooled features to their original scale with bilinear interpolation
- 对于 Detector,为了 detect tiny objects,作者提出了 a scale- invariant anchor strategy to tile anchors reasonably especially for small objects based on RPN;作者还 insert an efficient zoom-out and zoom-in architecture in Tiny-Net to enlarge the feature maps, which improve the recall of tiny objects obviously;此外作者还用了 Position sensitive RoI pooling,这是 R-FCN 里面的,我没印象了
网络的总体框架如下图所示
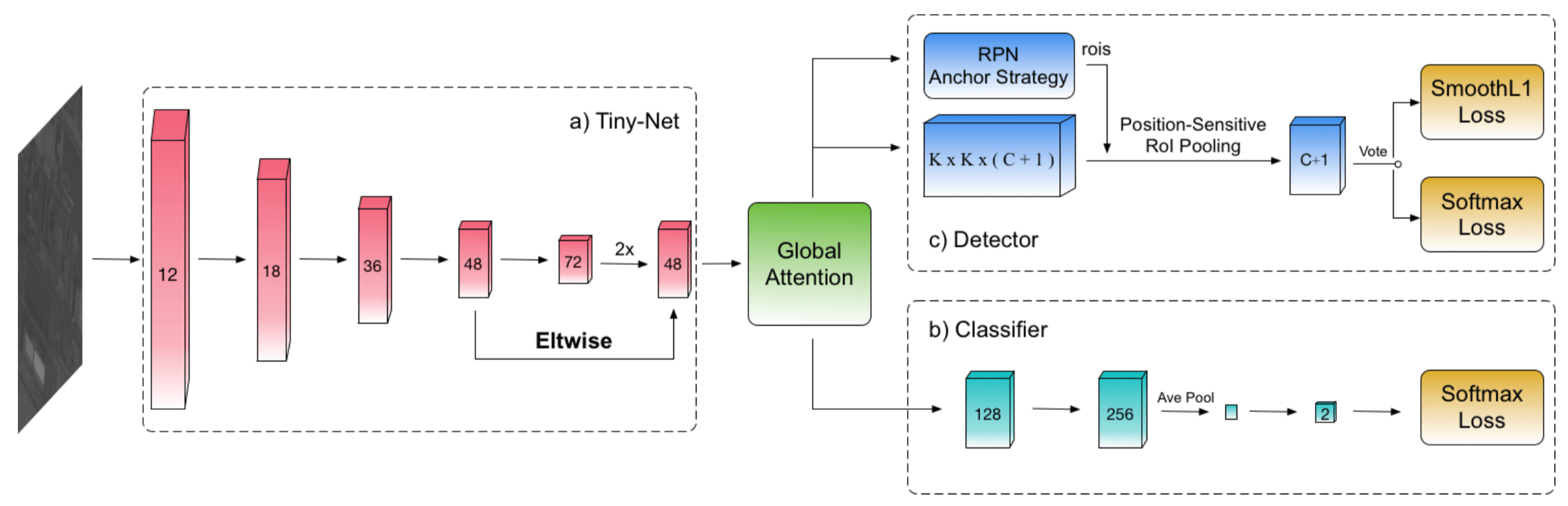
Related Works
Finding tiny faces 这篇文章 shows that context is crucial and defines templates that make use of massively-large receptive fields.
Pyramid scene parsing network 这篇文章我还没看过,employ the context reasonable
这篇文章也提到了 those models are designed specifically for image classification, make the feature resolution may be not enough for object detection,Detector 要有 Detector 的 backbone,不能用 Classification 的 Backbone
作者是通过 enlarge receptive field 来实现 context 增长的,而这么做的理由还在于 the theoretical receptive field and the effective receptive field,实际的 effective receptive field 要小于 theoretical receptive field(Only a subset of the area has effective influence on the output value, which is called effective receptive field.)
Global Attention Block 的图如下所示,问题来了,这个 Attention 在哪里了?
对于 anchor size 的选择,作者是用 k-means 是来自动选的,Instead of choosing anchors by hand, we run k-means clustering on the training set to automatically find good priors.
[13] R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy
作者概括的 object detection in Aerial images 里面的难点:
- Aerial images are very complex, not only because of the different image resolutions, but also due to the large number of interference objects.(要检测的类别多也是一个难点,区分度就小了)
- Aerial images contain a large number of small objects whose feature information is often overwhelmed by complex surrounding scenes.
- Some categories of objects are often densely arranged, such as vehicles, ships and so on, which pose challenges to detection algorithms.
- Due to the high altitude imaging, the object is appeared in arbitrary orientations. In addition, large aspect ratio object detection is a technical difficulty.
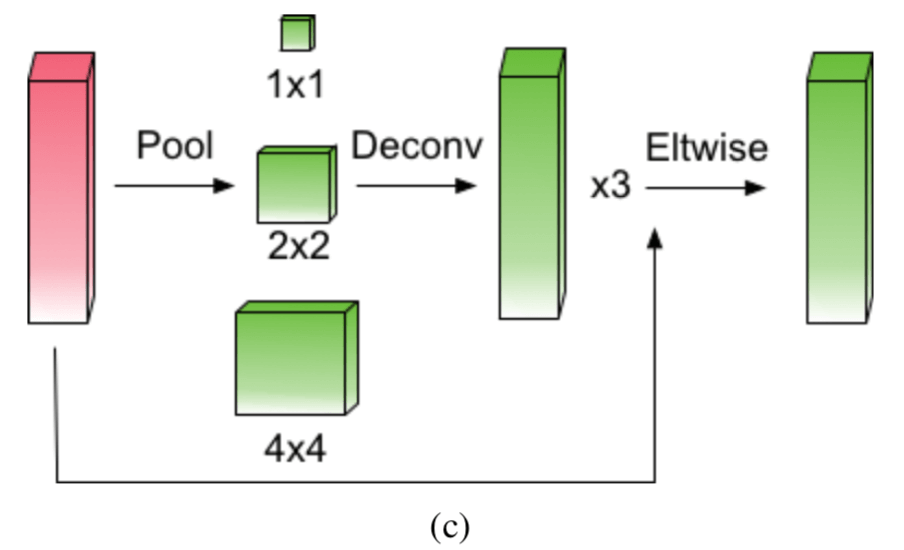
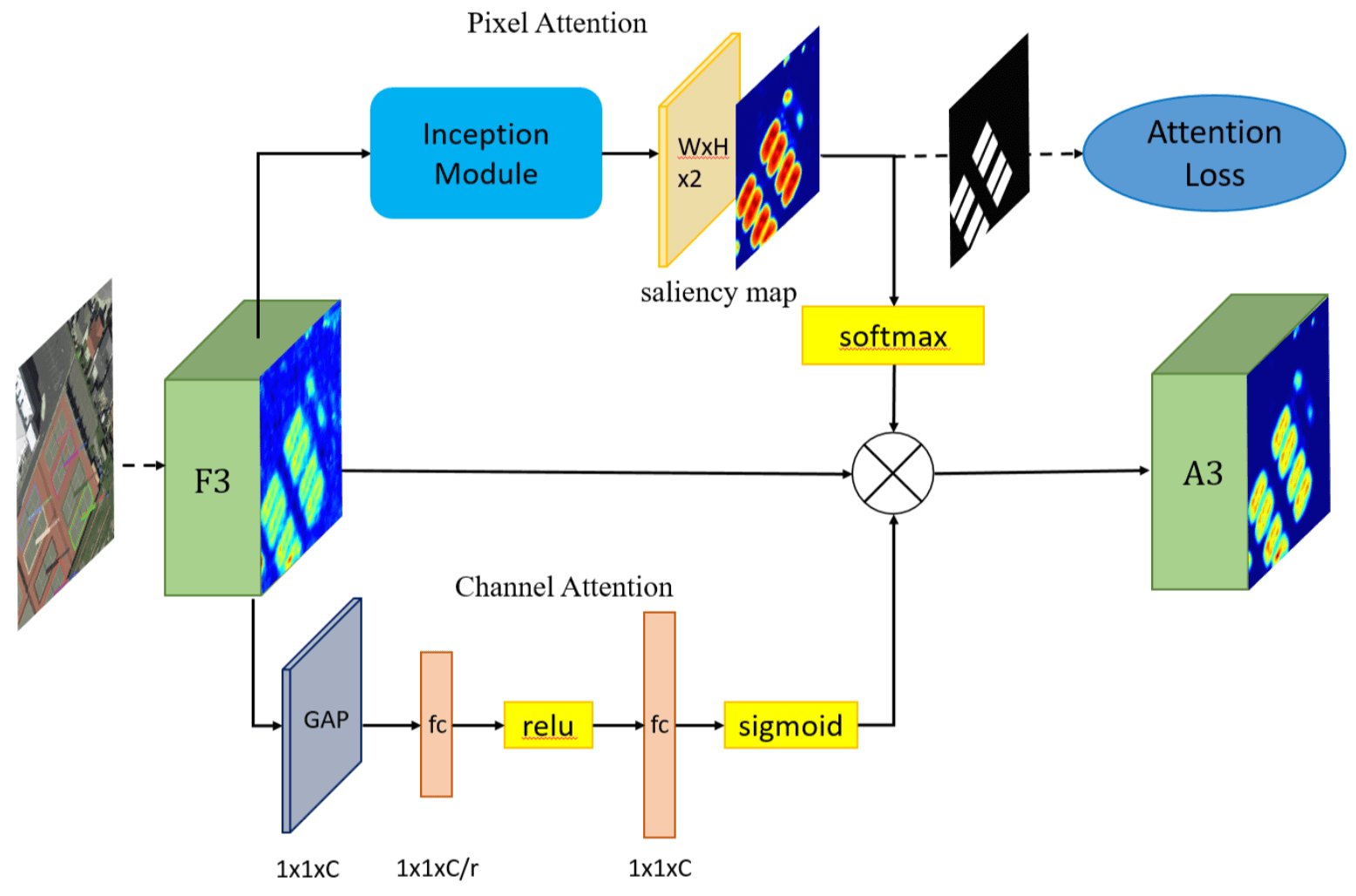
文章标题里的 Multi-Dimensional Attention 是指文章用了 pixel attention network and the channel attention network to weaken the noise infor- mation and highlight the objects feature
从下图中可看出,除了抽取特征的 backbone 之外,本文一共由下面 3 部分构成
- inception fusion network (IF-Net) :considers factors such as receptive field gaps, feature fusion, anchor sampling to effectively detect small objects 还不清楚具体是干嘛的?
- multi-dimensional attention network (MDA-Net):pixel attention network and channel attention network
- the rotational region detection branch: adding an angle parameter to overcomes the difficulty of detecting dense objects while providing the object direction
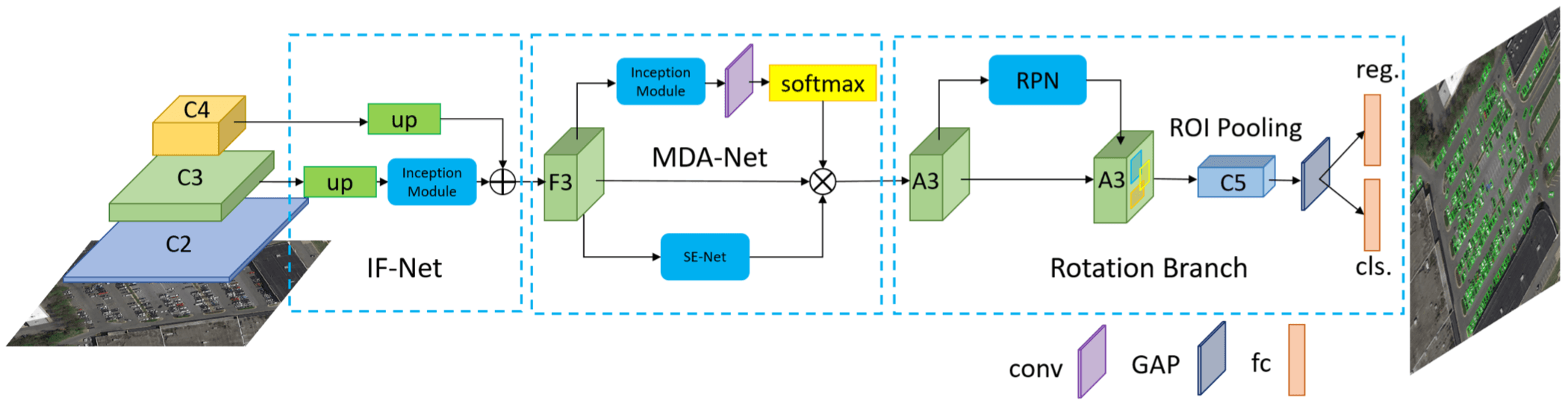
oriented bounding boxes (OBB) and horizontal bounding boxes (HBB)
Arbitrary-oriented object detection 在 scene text detection 这个领域被研究的比较多,但作者认为 aerial object detection is more challenging 的原因如下:
- first, many text detection models are only limited to for single-object detection,which is not applicable to multi-category object detection of aerial images.(text detection 只要检测 text,而 Aerial Object 要检测多类 Object,Multi-categories 本身就是一个难点)
- Second, there is often a large gap between texts, while the objects in the aerial image are very close, so the segmentation based detection algorithm [7, 39] may not achieve good results.(densely arranged)
- Third, aerial image object detection requires higher performance of the algorithm because of a large number of small objects.(没看懂作者要表达什么,大概是说 small Object 检测更难吧)
本文方法是 a two-stage method based on Faster-RCNN,Second stage 做的是 five-parameter regression(应该是多了一个 Orientation parameter) and the rotation nonmaximum-suppression (R-NMS) operation for each proposal
How to effectively detect small objects is the key to applying the object detection algorithm to aerial images.
There are two main reasons for the difficulty in detecting small objects:
- insufficient feature information
- inadequate training samples.
在 IF-net 里面 S3 上采样后还经过了一个 Inception block,作者说这是为了 expand its receptive field and increase semantic information,可以理解成对 feature 的进一步变换提取吧
注意一下,本文方法中的 Pixel Attention 是通过 supervised learning 学习的,有 Object Segmentation 的 Binary Map 作为 Groundtruth,loss 就是 cross Entropy,这个 loss 计算的是 Groundtruth binary map 和 Saliency map (Attention weight map)之间的距离,至于这个 binary Groundtruth 是怎么得到的,作者就说了 easily,我猜是 阈值分割?
Attention 模块的示意图如下图所示:
[14] Pyramid Scene Parsing Network
CVPR 2017 的论文,最后两个作者是 Wang Xiaogang 和 Jia Jiaya
强调语义分割中需要大的感受野来补充上下文信息,通过多尺度 pooling 的方法去弥补感受野不足的问题,从而增加 feature map 中的 context 信息
本文提出的方法叫作 pyramid scene parsing network (PSPNet),Motivation 是 exploit the capability of global context information(The local and global clues together make the final prediction more reliable.)
global prior representation
应该是把 global context information 作为 global prior representation 吧
Towards accurate scene perception, the knowledge graph relies on prior information of scene context.
FCN 来做 Scene Parsing 的缺点:lack of suitable strategy to utilize global scene category clues.
在本文之前,get a global image-level feature 的方式一般采用 spatial pyramid pooling,之所以这么用是因为 spatial statistics provide a good descriptor for overall scene interpretation
本文说是设计了一个 global pyramid pooling(相对于之前的 spatial pyramid pooling,这俩有什么区别?)
Related works 大概有下面 3 条路线:
- enlarge the receptive field of neural networks:指的是 DeepLab 的 dilated conv 那一路子
- multi-scale feature ensembling
- structure prediction:指的是用 conditional random field (CRF) 来后处理的那一路子
本文没用 Global Average Pooling 来获得 global descriptors,而是采用 different-region-based context aggregation via our pyramid scene parsing network,这具体是怎么做的?
Context relationship 是什么,是 co-occurrent visual patterns
因为 FCN 只用了 local 的特征,所以对于相似的场景,skyscraper 和 building,会一部分是 skyscraper 一部分是 building,These results should be excluded so that the whole object is either skyscraper or building, but not both. This problem can be remedied by utilizing the relationship between categories.(全局就会有这样的问题)
因为 the empirical receptive field of CNN is much smaller than the theoretical one especially on high-level layers,所以高层特征的语义其实没有想象中的那么丰富的,用文中的话说是 This makes many networks not sufficiently incorporate the momentous global scenery prior.
所以本文要解决的核心问题是 proposing an effective global prior representation
本文的 Pyramid Pooling Module 跟 Spatial Pyramid Pooling 的区别在哪里?
Spatial Pyramid Pooling 也有 concat,但是是 concat 成一个向量然后送入 全连接层
而本文的 Pyramid Pooling Module 是上采样成一样的大小,concat,起来,而且原来输入 pooling 的特征也一并 concat 起来,具体如下图所示
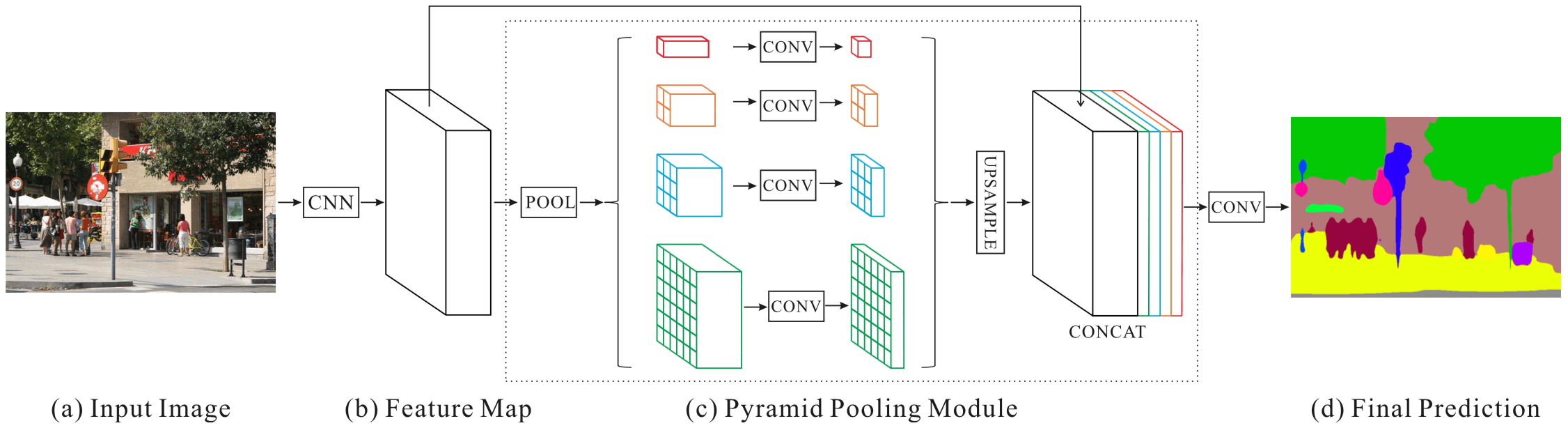
之所以要弄成金字塔是为了得到的 feature map 具有不同层次的语义信息,还能保留空间信息(对比 Global Average Pooling 就失去了空间信息)
PSPNet 还有 DeepLabv3 的一个很重要的实验结论就是 image-level 的 context 对于分割的结果性能提升非常重要
Fast-OCNet: 更快更好的 OCNet 这篇文章以及里面提到的文章都有必要好好看看
金字塔场景解析网络 —— 分割任务中的尺度问题(PSPNET) | Paper Reading 第一季第八期
同 目标检测中目标尺寸变化,需要在不同的尺寸下对目标进行检测一样,场景解析任务中也存在尺度问题,这是因为 不同尺寸的物体需要在不同的感受野范围内才能相对容易的将其与背景分割开来。由此,解决分割任务中的尺度问题也就等价于 解决不同的场景或分割的目标需要不同尺寸感受野的问题
在图像目标检测任务中,我们知道目前有许多深度学习网络使用基于 SPPNET 演化而来的多种尺寸的特征进行融合的方式来解决尺度变化的问题。而在图像分割任务中,同样可以采用类似的思想,例如 PSPNET 中的金字塔解析网络、Refine-NET 中图像的多级处理等;
数据集发展由易到难
从算法的发展演化看图像分割
在 2015 年之前,CNN 能够对图片进行分类,但是怎样才能识别图像中特定部分的物体还是一个世界性的难题。于是图像语义分割的一个标志性的发展事件就是神经网络大神 Jonathan Long 发表《Fully Convolutional Networks for Semantic Segmentation》,即 FCN 全卷积网络的诞生,它的贡献主要有两点:
a)使用全卷积替换全连接。不但去除了全连接层对网络结构的限制,还大量减少参数与计算量,提高网络的性能。然后使用反卷积层来上采样得到与原图同样大小的分割图。这里使用的全卷积的概念如下图所示,最开始是在《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》文章中提出。
b)使用跳跃结构将不同尺度与不同感受野情况下的特征图结合起来。因为在 32 倍下采样后直接上采样得到的效果是十分模糊的。所以使用上述方式将不同池化层的结果进行上采样后来优化输出。我们知道在高层特征中保留了更多的语义信息,但丢失了较多的空间位置信息;而低层特征保留了更多的细节信息与位置信息,但上下文信息相对较少。此处的信息融合起到优化结果的作用。
但是 FCN 得到的结果不够精细,对细节不敏感,且没有充分考虑像素与像素直接的关系,缺乏空间一致性。
DeepLab 2016 年在 FCN 的基础上,提出优雅的池化与带孔的卷积,其贡献主要如下:
a)对于 repeated convolution 导致分辨率丢失的问题。作者采用了一个叫做 atrous convolution 的卷积操作,同时添加了一个 rate 来跳过若干个相邻的卷积核,起到了 maxpooling+ convolution 的作用。
b)对于传统的强行将图像转换为相同尺寸的方法容易导致某些特征扭曲或消失,使用了 ASPP (atrous SPP)来解决这个问题。通过不同的 A convolution 来对图像进行不同程度的缩放,得到不同大小的 input feature map,(可以理解成 SPP 中使用不同大小的 proposal),这样 ASPP 就保证了 deeplabNet 可以处理不同尺寸的图片。由于目前的分割网络存在如下三类问题:错误的上下文信息(感受野不合适或不够大)、易分错的类别(感受野不够大)、易忽略的物体分类(感受野不够小或不合适);于是提出金字塔场景解析网络
综上可知,分割网络的尺度问题可以通过特征图的多尺度池化来解决,同时使用不同尺度池化后的特征融合来实现不同感受野的上下文信息融合,与整体轮廓与纹理细节的融合。从而在大尺度物体的分割与小尺度问题的分割上都能有效地结合上下文信息,同时尽量少的丢失细节信息,实现高质量的像素级别的语义分割。
[15] HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection
第一作者 Tao Kong 就是知乎上的 孔涛,这篇论文是 CVPR 2016 的 Oral。
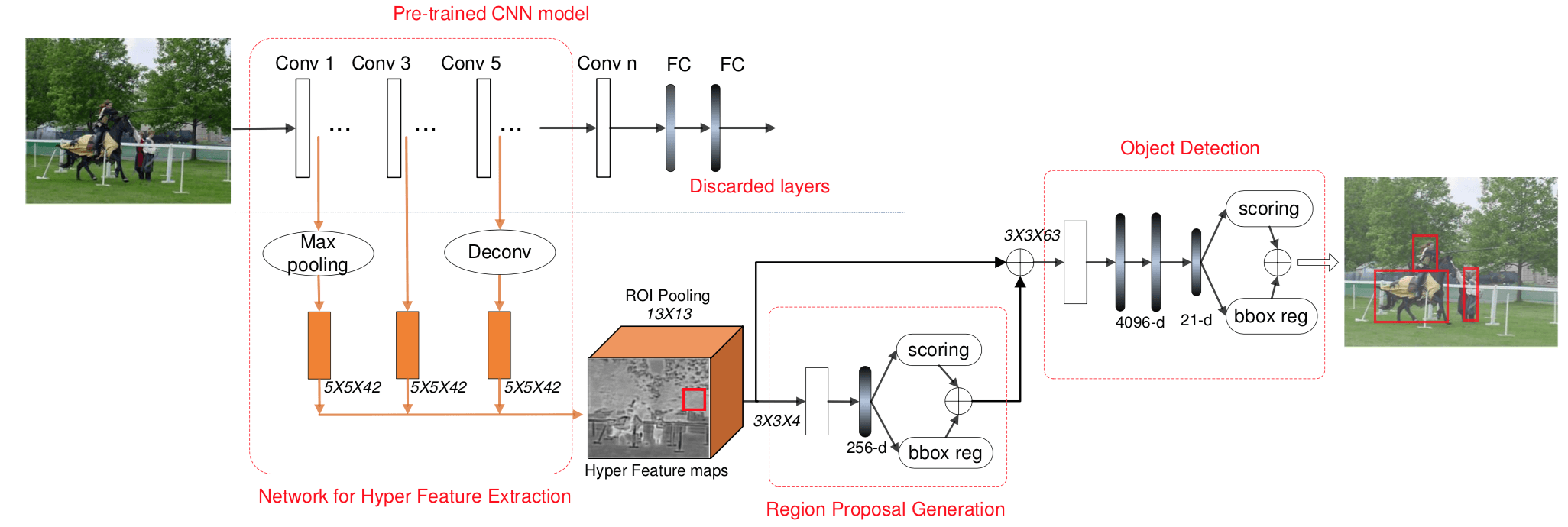
从名字 Towards Accurate Region Proposal Generation 上就可以看出来,这篇文章的做的是 Region Proposal Generation,而怎么让其 Accurate 呢?要么更好的 Feature,要么更好的 Inference. 作者这两个都做了,更好的 Feature 通过 Hierarchical Feature Fusing,更好的 Inference 是采用了相比 RPN 的简单 Conv 更加 Heavy 的 ROI Pooling - Conv - FC 来做 Region Proposal Generation。
Motivation 是 RPN 在 small-size object detection and precise localization 上表现不好,而原因在于 the coarseness of its feature maps,而作者解决方法就是 hierarchical 特征融合,用文中的表述是 aggregates hierarchical feature maps first and then compresses them into a uniform space
hierarchical 特征融合的 Motivation 都是一样的:
The Hyper Features well incorporate deep but highly semantic, intermediate but really complementary, and shallow but naturally high-resolution features of the image, thus enabling us to construct HyperNet by sharing them both in generating proposals and detecting objects via an end-to-end joint training strategy.
Generic object detection methods are moving from dense sliding window approaches to sparse region proposal framework. (然而 Sparse Region Proposal 仍然依赖于 Dense Sliding Window,只不过基于 Dense Sliding Window 的 Region Proposal 计算量相比 Final Classification 小很多)
作者认为随着输入 RPN 的质量的改善,the region proposal number 可以从 traditional thousands level 减少到 one hundred level and even less(减少不必要的 Proposal 自然可以提高速度)
用 CNN 来 generate region proposals 的方法
- Deepbox is trained with a slight ConvNet model that learns to re-rank region proposals generated by EdgeBoxes
- RPN has joined region proposal generator with classifier in one stage or two stages.
- In DeepProposal, a coarse-to-fine cascade on multiple layers of CNN features is designed for generating region proposals.
本文 fusing multi-level feature maps 的策略:
- 对低层做 max-pooling, 对高层做 deconv,将其都变换到同一大小
- normalize multiple feature maps using local response normalization (LRN)
- concat 起来
对 高层做 deconv 表明最后 Region Proposal 是在比最后那层大的中间层尺寸的 map 上做的,对小目标更加友好(这样其实会导致要做 Prediction 的数量大大上升)
对于 Region Proposal Generation, Faster R-CNN 就是用一个 conv 直接预测;而本文的 Region Proposal Generation 则是由 a ROI pooling layer, a Conv layer and a Fully Connect (FC) layer 组成,可以说是相当 Heavy 了,具体框图如下所示
可以说是在 Region Proposal 的 Heavy 和 Region Proposal 最后的数量 之间 Trade-off 了
最后 2 阶段 Detection 也是在 融合后的 Feature Cube 上
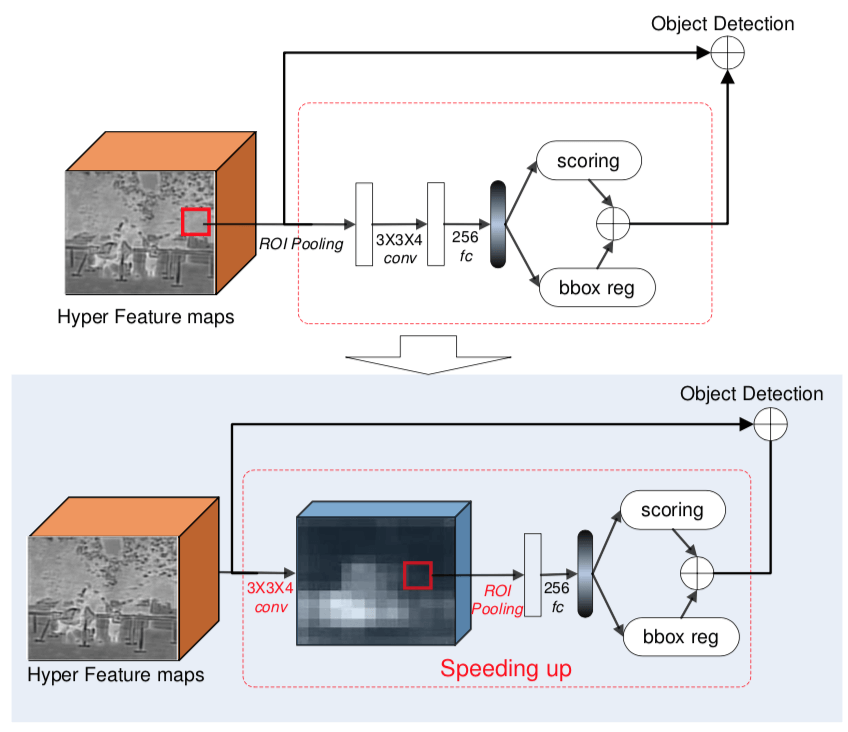
为了加速,作者把 Region Proposal Generation 中原先的 ROI Pooling - Conv - FC 的顺序换成了 Conv - ROI Pooling - FC,这样就只要做一次共享的 Conv 就可以了,具体如下图所示
[16] Cascade Region Proposal and Global Context for Deep Object Detection
海康威视研究院的文章
Two-stage Method 由两步构成:
- region proposal step
- object recognition step
本文的工作上 propose a novel lightweight cascade structure 来 improve RPN proposal quality
本文的 Contribution:
- a lightweight cascade RPN architecture
- revisit global context modeling
Cascade Region Proposal 的 Related Works:
- 基于 low-level features 的
- unsupervised 的:Selective Search 和 EdgeBoxes
- supervised 的:BING
- 基于 high-level semantic CNN features 的
- RPN
- a multi-stage cascading pipeline
- DeepBox: uses CNN to rerank proposals from a conventional method(抽取 Proposal 是一个 stage,rerank 是另一个 stage)
- CRAFT:uses a two-class Fast R-CNN to refine proposals from a standard RPN(这个跟 HyperNet 有什么区别?)
本文 shares similar pipeline with CRAFT,use a modified RPN instead of Fast R-CNN in the second cascading stage
Context Modeling 的作用:provide valuable information for discriminating objects of interest
- In R-CNN, classification of an object is solely based on the regional information.
- In SPP-Net and Fast R-CNN, with the enlarged receptive fields of convolution layers, contextual information is implicitly yet only partially exploited as regional features are cropped from feature maps of deep layers.
- Gidaris and Komodakis [24] proposed a Multi- Region CNN architecture, where a rectangular ring around the object is cropped and serves as context. [25, 26] utilized an enlarged area (e.g. 1.5×) around the object as local context.
- Bell et al. [27] used spatial recurrent neural networks (RNN) to model context outside the object
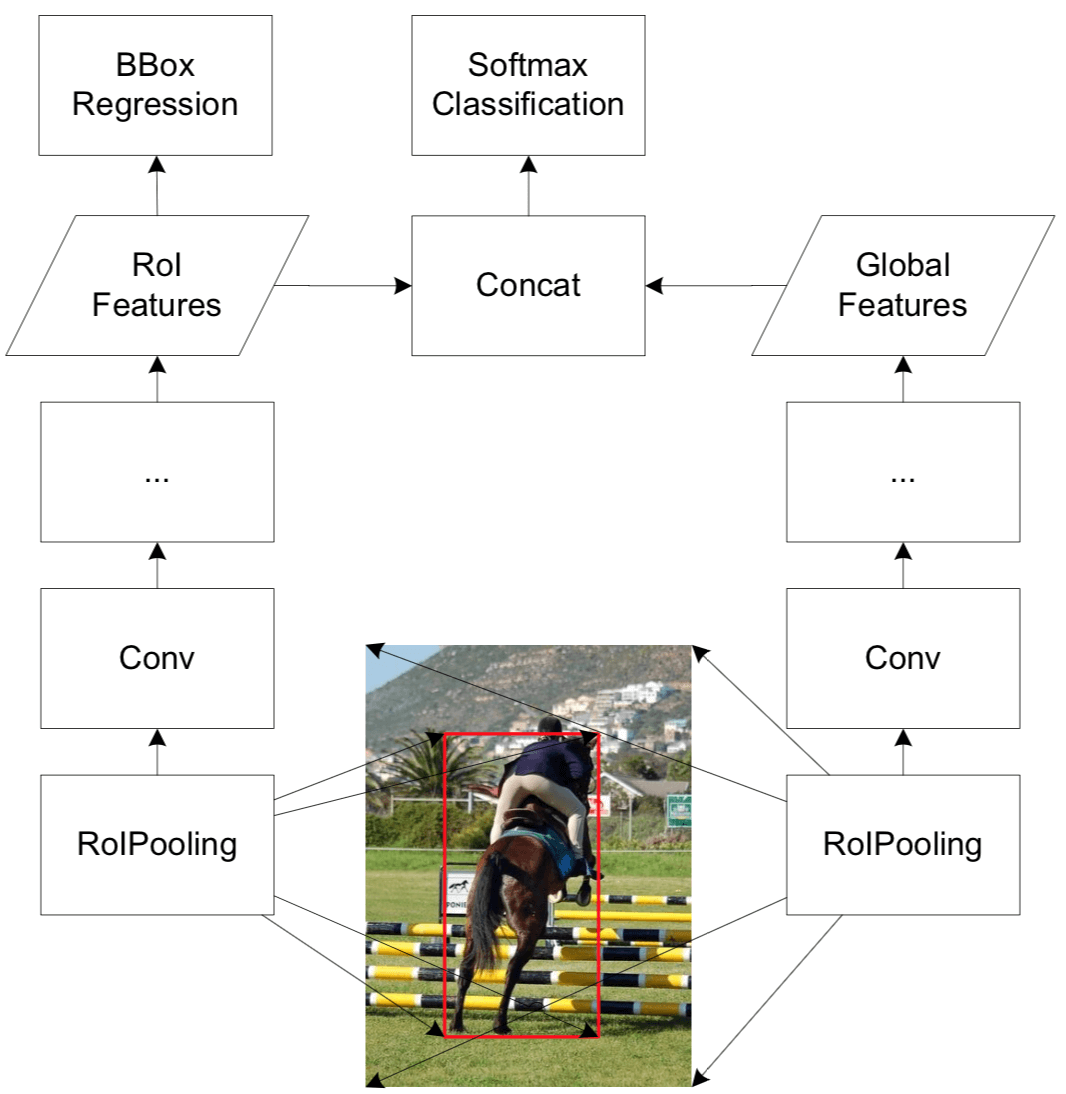
- Ouyang et al. [28] used ImageNet 1000-class whole image classification scores as scene information to refine per- object classification scores.
- He et al. [29] proposed global context modeling, where the image-level features are extracted through RoI pooling over the whole image.
作者 improve proposal quality 的策略:pretraining RPN, cascade RPN 和 constrained ratio of negative over positive anchors
pretrain as many layers as possible
pretraining RPN 具体指的是,由于 pretraining 可以改善效果,所以 pretrain as many layers as possible;而在 Faster R-CNN 中 RPN 是 randomly initialized and trained from scratch,所以本文就是通过 pretraining RPN
具体框图如下所示:
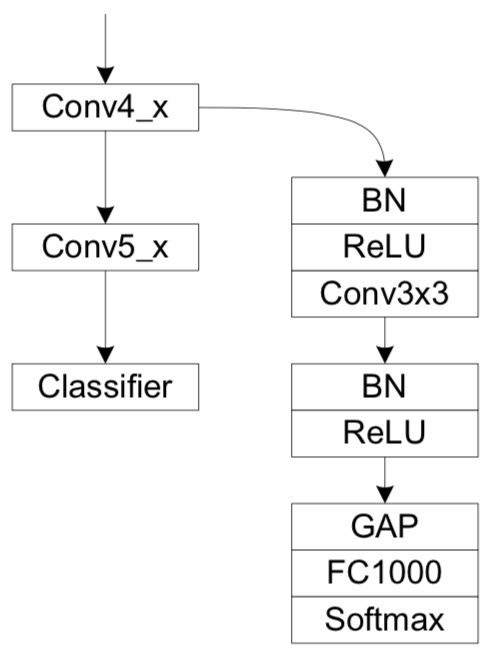
但我很奇怪的是,做了 Global Average Pooling 之后这个分类要分什么,label 是什么?
作者用了串联的两个 RPN 是为了利用 RPN 2 剔除 RPN 1 的虚警吧,但这个有个坏处,RPN 2 的 Feature conv 更多,不利于小目标检测,因此本文采取的策略是 small bounding box 的 Object 用 RPN 1 的结果,medium-large bounding boxes 用 RPN 2 的
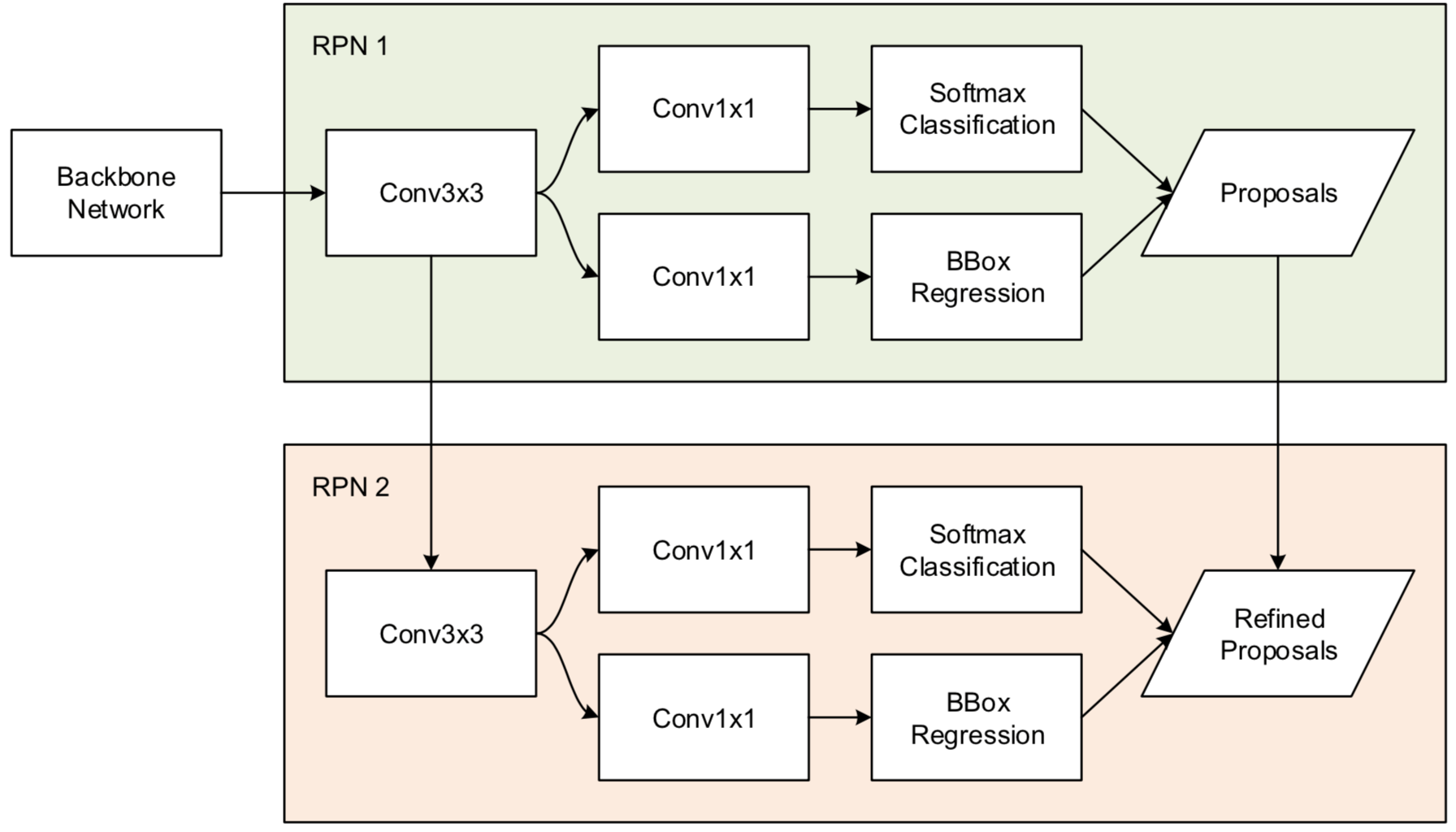
至于 本文 的 Global Context 是怎么用的?an RoI pooling over the entire image is performed to extract global features
use global context features for classification only
这个 global context features 的用法是跟 Attentive Contexts for Object Detection 的一样的,global Average Pooling 的特征和 ROI Pooling 出来的 Local Feature 一起输入最后的Softmax Classification,具体的示意图如下图所示:
[17] Drone-based Object Counting by Spatially Regularized Regional Proposal Network
ICCV 2017
作者的洞察是存在 the spatial layout information (e.g., cars often park regularly),这个可以作为 spatially regularized constraints,把这个引入 Network 就可以提升 localization accuracy.
本文是在 drone-based videos 里面检测,不是 image
以前的工作是 cast car counting as a classification problem
leverage the spatial layout information (e.g., cars often park regularly) and introduce these
作者的 observation 是 exists certain layout patterns for a group of object instances, which can be utilized to improve the object counting accuracy
提出的 spatially regularized loss is a weighting scheme that re-weights the importance scores for different object proposals and encourages region proposals to be placed in correct locations
本文的数据集是 a public PUCPR dataset,出自 P. R. de Almeida, L. S. Oliveira, A. S. Britto, E. J. Silva, and A. L. Koerich. Pklot–a robust dataset for parking lot classification. Expert Syst Appl, 2015.
Object Counting 有两个思路:
- counting by regression method:Regression counters are usually a mapping of the high-dimension image space into non-negative count- ing numbers.
- global regression methods ignore some constraints, such as the fact that people usually walk on the pavement and the size of instances
- counting by detection instance:
Region Proposal 的思路是,Region Proposal 是轻量级的,而后面是 a computationally demanding classifier,所以希望 Region Proposal 产生的是 a tiny subset of possible positions
aerial view car-related datasets 集合如下表所示

数据集的图像和目标具体什么样如下图所示,其中 a, b, c, d, e 分别是 OIRDS [28], VEDAI [20], COWC [18], PUCPR [10], and CARPK

本文的 dataset 可以在 https://lafi.github.io/LPN/ 里面找到
本文数据集的意义是 CARPK dataset provide the first and the largest-scale drone view parking lot dataset in unconstrained scenes
Layout Proposal Networks (LPNs)
Spatially regularized loss
regularized layout structure 被刻画成 Spatially regularized loss
本文的 LPN 和 RPN 一样,takes as input an 3 × 3 windows on last convolutional layer for reducing the representation dimensions, and then feeds features into two sibling 1 × 1 convolutional layers, where one is for localization and the other is for classifying whether the box belongs to foreground or background.
区别只在于 LPN 的 loss function introduces the spatially regularized weights for the predicted boxes at each location.
本文的具体做法是 apply the spatially regularized weights for re-weighting the objective score of each predicted box,问题来了:
- spatially regularized weights 怎么来的?
- 这个 re-weighting 又是怎么实施的?the more similar objects of instances surrounding it, the more possible the predicted boxes are the same category of instances
The weight is obtained by a Gaussian spatial kernel for the center position $c_i$ of predicted box. It will give a rearranged weight according to the $m$ neighbor ground-truth box centers, which are near to the $c_i$.
$N{fg}$ and $N{bg}$ are the normalized terms of the number matching default boxes for foreground and background. default boxes 是 RPN 的输入特征所在的 default box,损失函数 $L{fg}$ 和 $L{bg}$ 就是标准的 cross Entropy
因此,从下面的 Loss Function 看来,其实作者只是在原有 Loss 的基础上,对 Fg 的 Cross Entropy loss 乘上了一个 Gaussian weight。
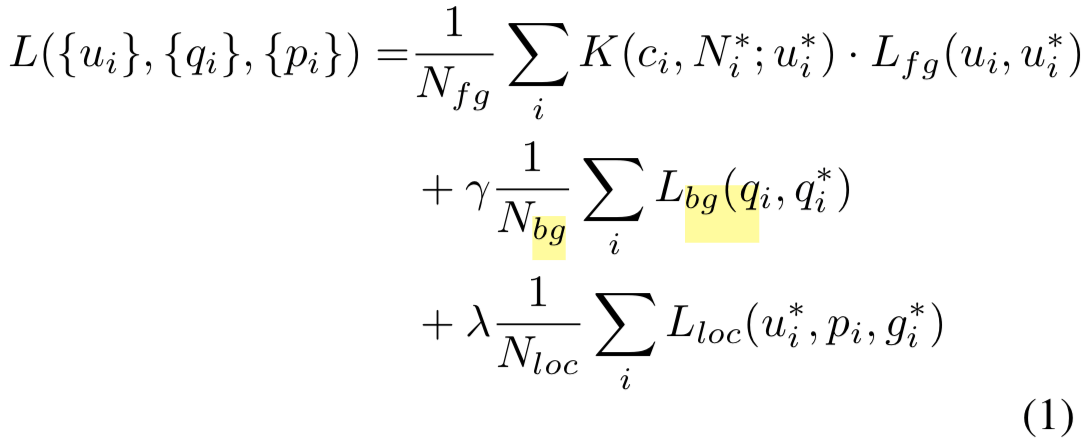
具体 Gaussian weight 的计算方式如下,对于当前的 Region Proposal,它有一个邻域,在这个邻域内所有的 Region Proposal 构成了集合 $N^*_j$,以当前的 Region Proposal 为中心,他们有一个坐标,代入下面的公式即可,根据高斯函数的特性,肯定是相邻的 Region Proposal 越多靠的越近越好,也就是这个是 正确 Region Proposal 的 权重越高
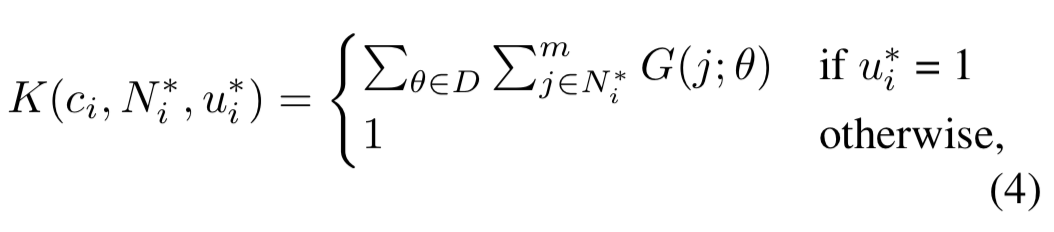
本质上是对每个 Region 的 Loss 根据 Spatial Layout 实现了一个 re-weighted
Focal Loss、Dice Loss 是依赖于 Prediction Score 本身;而本文是依据 Spatial Layout
综上所述,本文的工作其实就是一个 spatially regularized loss
[18] FastMask: Segment Multi-scale Object Candidates in One Shot
CVPR 2017 的 Paper
本文不把 Region Proposal 叫 Region Proposal,叫作 Object Proposal,因为相比 Region Proposal
Object Proposal 是一个 segment proposal framework
因此,由 Object Detection 中的 detect multi-scale objects in one shot,变成了 segment multi-scale objects in one shot
segment proposal algorithms are expected to generate a pixel-wise segment instead of a bounding box for each object
segment proposal inherits from both object proposal and image segmentation, and takes a step further towards simultaneous detection and segmentation,这显然更加 challenging
核心问题还是 how to tackle the scale variances in object appearance
而对付多尺度变化的核心在于 特征是来自于 a highly matched receptive field
a highly matched receptive field is demanded to distin- guish the foreground object from background
once the receptive field of a segment- based proposer is fixed, object scale variance will badly af- fect both segmentation fineness and proposal recall
关于 image pyramid strategy 的做法:the original image is rescaled and fed into a fixed-scale object proposer repeatedly for multi- scale inference,缺点:face a common dilemma: a densely sampled image pyramid becomes the computational bottleneck of the whole framework; nevertheless, reducing the number of the scales of image pyramid leads to performance degradation.
本文选择不用 image Pyramid 的 argument 是 With the observation that the original image has already contained all information of an image pyramid, we argue that using one single image should be enough to capture all multi-scale objects in it.
本文的思路又是 address the scale variances in segment proposal by leveraging the hierarchical feature pyramid
- body:extracting semantic feature maps from original images
- head:decoding segmentation masks from feature maps
neck:recurrently zoom out the feature maps extracted by the body module into feature pyramids, and then feed the feature pyramids into the head module for multi-scale inference
head module are responsible for extracting semantic feature maps from original images and
从本文 Related Works 看,本身 object proposal 就存在 Bbox-based object proposal 和 Segment-based object proposal 两种:
- Bbox-based object proposal:
- EdgeBox、Bing:the edge feature is used to make the prediction for each sliding window
- Proposal generation for object detection using cascaded ranking svms 是用的 gradient
- DeepBox 是 trains a CNN to re-rank the proposals generated by EdgeBox(这是二次加工了)
- MultiBox generates the proposals from convolutional feature maps directly
- region proposal network (RPN) is proposed to handle object candidates in varying scales(RPN 和 MultiBox 的区别是 category-agnostic 与否?)
- Segment-based object proposal
- Selective Search、 MCG、Geodesic:first over-segment image into super pixels and then merge the super pixels in a bottom-up fashion,所以说 SS 虽然被拿去用作 Bbox-based object proposal 但其他他是一个 Segment-based object proposal 方法
- As the state-of-the-arts, DeepMask proposes a body-head structure to decode object masks from CNN feature maps
- SharpMask [21] further adds a backward branch to refine the masks
- 但是 DeepMask 和 SharpMask 都是 rely on an image pyramid during inference, which limits their application in practice(这就是为什么本文叫作 FastMask 的原因了,因为相比之前的快)
Visual attention 的作用:highlight discriminative region inside images and reduce the effects of noisy background,本文也用了 Attention
文章说的 From Multi-shot to One-Shot 是什么意思?难道 Semantic Segmentation 以前不也是 One-Shot 的吗?本文是把基于 Image Pyramid 的都叫做 multi-shot 了吧
说 DeepMask 是 CNN-based multi-shot segment proposal methods 的典型代表
multi-shot paradigm
把 DeepMask 叫作 multi-shot 是因为其中的 Multi-shot inference
DeepMask 两阶段:
- Patch-based training:trained to predict a segmentation mask and a confidence score given a fixed-size image patch,注意着不是 FCN Style 的,而是对给定的 patch 做 Presence Classification 和 Pixel-wise Segmentation
- Multi-shot inference:applies the trained model densely at each location, repeatedly across different scales
其实不管是 DeepMask 还是 FastMask 都最后用了 Sliding Window 我很奇怪,不应该是 FCN 么?
之所以有 Sliding Window 是因为 Object Proposals 的工作范式是:
Given an image patch:
- Generate a segmentation mask
Likelihood of patch being centered on a full object
First, for every (overlapping) patch in an image: Does this patch contain an object? (Object Presence Classification)
- Second, if the answer to the first question is yes for a given patch, then for every pixel in the patch: Is that pixel part of the central object in the patch?(Pixel-wise Classification)
Predicts Segmentation Mask for a given input patch, assigns score of the patch’s objectness
For each training sample:
- RGB input patch (x)
- Binary Mask (m) : +1 or -1
- Patch objectness (y) : +1 or -1
- y = 1; if patch contains object (roughly in the centre) AND object is fully contained in the given scale range
- y = -1; if not; partial presence not graced either. Mask not considered.
其实 Sliding Window 不奇怪,RPN 不也是 Sliding Window 么
Object Proposal 和 Region Proposal 的相似和区别在于:
- 两者都要做 Classification,判断该 Region 里面是否含有 Object
- 如果含有,两者的区别在于 Region Proposal 是做 BBox Regression,Object Proposal 是做 Semantic Segmentation
[19] ParseNet: Looking Wider to See Better
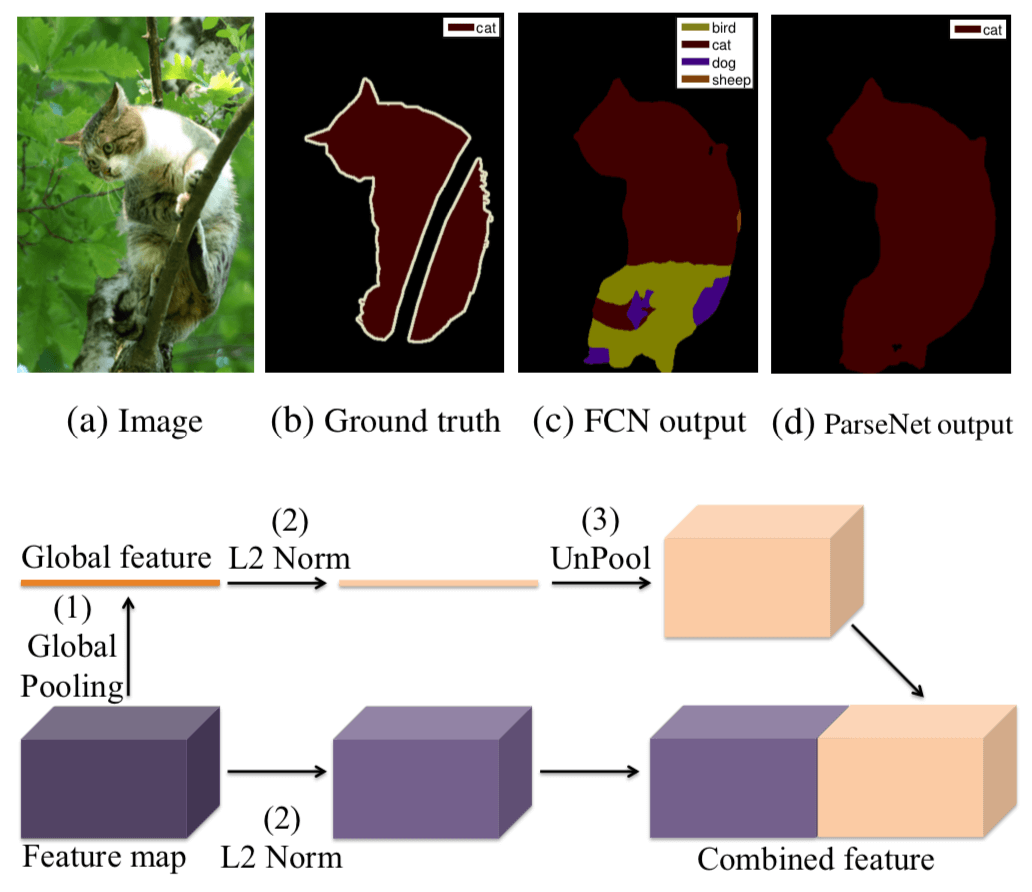
ICLR 2016 的论文,第一作者是 UNC Chapel Hill 的 Liu Wei,也是 SSD 的第一作者。
Motivation
作者觉得 FCN 的缺点是 oblivious to context,FCN disregards global information about an image, thus ignoring potentially useful scene-level information of semantic context 没有利用好 scene-level Information
为了弥补这个缺点,本文通过 adding global context to deep convolutional networks for semantic segmentation,具体的做法 using the average feature for a layer to augment the features at each location
本文具体 adding contextual information 的方式如下图所示:
在 Semantic Segmentation 里面用 CRF 被认为是 introduce global context and structured information into a FCN 的一种方式
而本文的做法是 revisit global context by terms of aggregating local features over the whole image
Ref [20] 表明 concatenating feature from the whole image with features on local patches 这么做,就不需要 apply CRF smoothing afterwards 了,因为 the whole image feature already encodes the smoothness information
[20] A. Lucchi, Y. Li, X. Boix, K. Smith, and P. Fua. Are spatial and global constraints really necessary for segmentation? In ICCV, 2011.
[28, 21] show that simply adding such context features helps in the detection and segmentation tasks. 也证明了一样的事情
但是文章说 However, these approaches use separate (image/patch) net- work to do it, not trained jointly. 这是什么意思?我没看懂
本文具体的做法:directly pool out whole image feature from a feature map of our network and combine it with each individual position
因为 concat 的Feature 可能来自于不同 scale,因此数值的 scale 也不同,所以要做一个 first l2 normalize features from each layer,才可以 concat 起来
adding global feature is a simple and robust method to improve FCN performance by considering contextual information
For tasks such as semantic segmentation, using context information from the whole image can significantly help classifying local patches
enlarge receptive field 的理由是:Although theo- retically, features from higher level layers of a network have very large receptive fields (e.g. fc7 in FCN with VGG has a 404 × 404 pixels receptive field), in practice the size of receptive fields at higher levels is much smaller. As shown in [32], the actual sizes are about 25% of the theoricatical ones at higher levels, thus preventing the model from mak- ing global decisions.
two general standard paradigms of using global context feature with the local feature map:
- early fusion:unpool (replicate) global feature to the same size as of local feature map spatially and then concatenate them, and use the combined feature to learn the classifier
- late fusion:each feature is used to learn its own classifier, followed by merging the two predictions into a single classification score [19, 2]
[19] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. arXiv:1411.4038, 2014.
[2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv:1412.7062, 2014.
作者说 FCN 是 late fusing
With early fusion, we can add extra capacity, nonlinearity or dimensionality reduction (1 × 1 convolution layer), to apply nonlinear transformations to the combined feature(还可以对 fused feature 做进一步的变换,这一点其实在 Deep Reasoning with Multi-scale Context for Salient Object Detection 里被说成了 inference module)
对于 combining the features 的 strategies,Table 7 的结论是 proper l2 normalization works better than a 1 × 1 convolution layer
不做 l2 normalization 的 Naively concatenating 会导致 poor performance 的原因在于 the ”larger” features dominate the ”smaller” ones
本文的贡献应该是两点:
- adding global context to deep convolutional networks for semantic segmentation(感觉不是本文第一个鼓吹,但作者给了一种 early fusion 的方式)
- 为了 fusing 效果好,作者提出了 L2 Normalization,一种简化版的 Batch Normalization
对于为什么 global context 能够起作用的解释:
ParseNet 论文中作者提到的一个好处是使用 global average pooling 的 context 是所有位置共享的,所以可以看做是用 smoothness item。
在 PSPNet 的工作中,作者根据 ADE20K 数据集上存在的一个问题提出了自己的解释 “global average pooling 的 context 其实是编码了图片所在的 scene 的 category 信息,比如说 ADE20K 上的图片其实是属于 300 多个不同的场景类别包括飞机场,洗手间,卧室等等。而如果利用这些 scene 的 category 信息可以帮助更好的做分割任务,因为在卧室洗手间不会出现飞机,从而在一定程度上可以 reduce 一些干扰信息。”。
Fast-OCNet 中
[20] Contextual Priming and Feedback for Faster R-CNN
ECCV 2016
Motivation: 现在的方法都是 bottom-up, feedforward ConvNet frameworks,然而在人类视觉中 top-down information, context and feedback play an important role in doing object detection,因此这篇论文就是要 investigates how we can incorporate top-down information and feedback in the state-of-the-art Faster R-CNN framework
本文工作:
- augment Faster R-CNN with a semantic segmentation network;
- use segmentation for top-down contextual priming;
- use segmentation to provide top-down iterative feedback using two stage training
region proposals 的好处:
- they reduce the search space;
- they reduce false positives by focusing the ‘attention’ in right areas
本文要做的 use top-down information in generating region proposals
top-down context provides the priming in humans(priming 中文翻译成启动效应)
本文的做法是 add segmentation as a complementary task and use it to provide top-down information to guide region proposal generation and object detection
The intuition is that semantic segmentation captures contextual relationships between objects, and will essentially guide the region proposal module to focus attention in the right areas and learn detectors from them
top-down context 和 global Feature 是否等价?
But contextual priming using top-down attention mechanism is only part of the story. In case of humans, the top-down information provides feedback to the whole visual pathway (as early as V1
Therefore, we further explore providing top-down feedback to the entire network in order to modulate feature extraction in all layers. This is accomplished by providing the semantic segmentation output as input to different parts of the network and training another stage of our model. The hypothesis is that equipping the network with this top-down semantic feedback would guide the visual attention of feature extractors to the regions relevant for the task at hand.
This raises an important question: Do ConvNet features already capture the structure that was earlier given by segmentation or does segmentation provide complementary information?(作者问这个问题,大概是想说 RPN 和 Segmentation 给出的信息其实是互补的,这是作者拿 Segmentation 来做 Priming 的动机)
本文的工作之一是 use semantic segmentation to guide/prime the region proposal generation
另一工作是 incorporating top-down feedback in our current object detection architectures
自下而上加工(bottom-up process):又叫数据驱动加工,由刺激的特征决定是否、如何进行加工。
自上而下加工(top-down process):又叫概念驱动加工,是以经验知识为基础进行的加工。(问题是我怎么对经验知识建模?)Bottom-up 是 formation of perceptions based on piecing together lower-level sensory input,data,and stimuli
Top-down 是 formation of perceptions by using higher-level knowledge, beliefs, and contextual information
作者:Chloeeee
链接:https://www.zhihu.com/question/53033702/answer/134225892
auto-context [74] and inference machines [64] 是 attempts earlier at exploiting feedback mechanisms 的做法是 iteratively use predictions from a previous iteration to provide contextual features to the next round of processing 感觉这个跟迭代的方法很像啊
using feedback to learn selective attention [55,69]
[55] Mnih, V., Heess, N., Graves, A., et al.: Recurrent models of visual attention. In: NIPS (2014)
[69] Stollenga, M.F., Masci, J., Gomez, F., Schmidhuber, J.: Deep networks with internal selective attention through feedback connections. In: NIPS (2014)
using top-down iterative feedback to improve at a task at hand [7,25,48]
[7] Carreira, J., Agrawal, P., Fragkiadaki, K., Malik, J.: Human pose estimation with iterative error feedback. arXiv preprint arXiv:1507.06550 (2015)
[25] Gatta, C., Romero, A., van de Veijer, J.: Unrolling loopy top-down semantic feedback in convolutional deep networks. In: CVPR Workshops (2014)
[48] Li, K., Hariharan, B., Malik, J.: Iterative instance segmentation. arXiv preprint arXiv:1511.08498 (2015)
The discussion on using global top-down feedback to contextually prime object recognition is incomplete without relating it to ‘context’ in general, which has a long history in cognitive neuroscience [6,39,40,53,59,60,75,79] and computer vision [16,24,58,62,71–73,81].
[6] Biederman, I.: On the semantics of a glance at a scene (1981)(我去,81 年就开始了)
[16] Divvala, S.K., Hoiem, D., Hays, J.H., Efros, A.A., Hebert, M.: An empirical study of context in object detection. In: CVPR (2009)
[24] Galleguillos, C., Belongie, S.:Context based object categorization: a critical survey. CVIU 114, 712–722 (2010)
[58] Murphy, K., Torralba, A., Freeman, W., et al.: Using the forest to see the trees: a graphical model relating features, objects and scenes. In: NIPS (2003)
[62] Rabinovich, A., Vedaldi, A., Galleguillos, C., Wiewiora, E., Belongie, S.: Objects in context. In: ICCV (2007)
[71] Torralba, A.: Contextual priming for object detection. IJCV 53, 169–191 (2003)
[72] Torralba, A., Murphy, K.P., Freeman, W.T., Rubin, M.A.: Context-based vision
system for place and object recognition. In: ICCV (2003)
[73] Torralba, A., Sinha, P.: Statistical context priming for object detection. In: ICCV (2001)
contextual relationships [6,39]
priming for focusing attention [53,75,79]
importance of scene context [14,40,59,60]
很多论文利用 context 的手段:
- computing local context features by expanding the region [26,56,57,83]
- using other objects (e.g., people) as context [33] and using other regions [30]
在 Contextual Priming 的角度,Faster R-CNN 的贡献:Faster R-CNN is also the first framework that learns where to guide the ‘attention’ of an object detector along with the detector itself.
end-to- end learning of proposal generation and object detection
本文的工作是 top-down contextual feedback mechanisms
ParseNet adds an average pooling layer to incorporate global context
本文 uses segmentation as top-down feedback signal to guide the RPN and FRCN modules of Faster R-CNN 到底是怎么 guide 的?
uses segmentation as top-down feedback signal 跟 Detection with Enriched Semantics 有什么区别?
为什么可以用 Segmentation 的理由:作者认为 a raw semantic segmentation output is a compact signal that captures the desired contextual information such as relationships between objects (Sect.2) along with global structures in the image, and hence is a good representation for top-down feedback
本文方法里面,Detection 用的是 Faster R-CNN,Segmentation 用的是 ParseNet。作者画了 Faster R-CNN 的图,还是蛮清晰的,特别是右侧的简略图
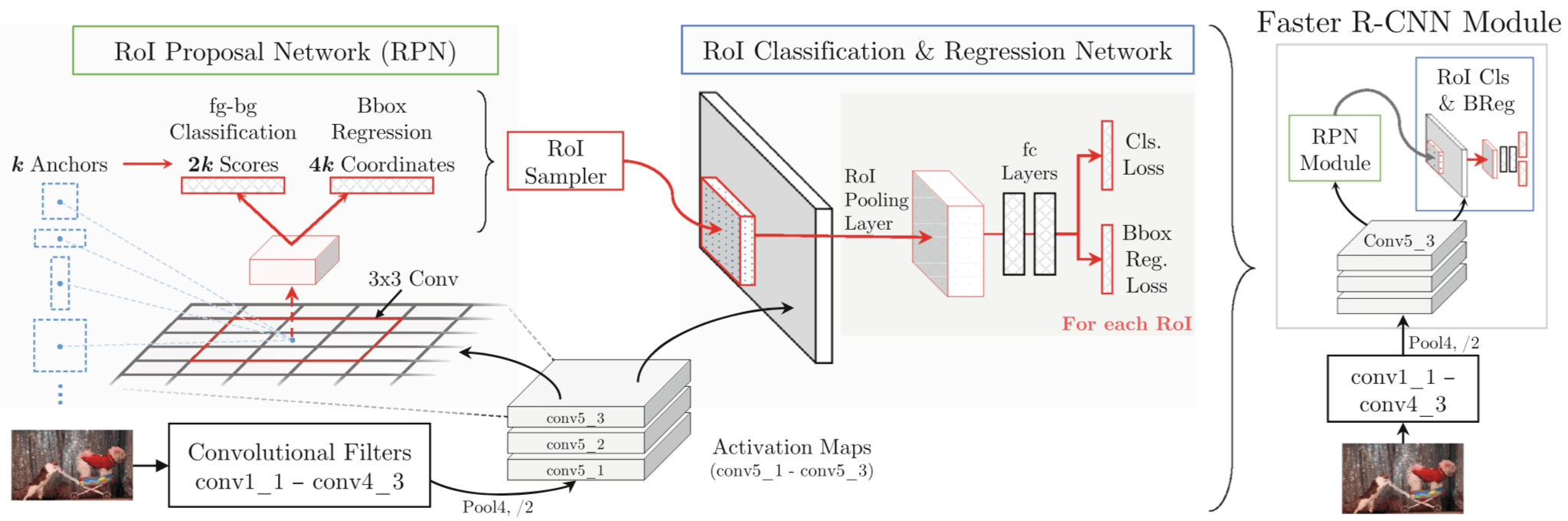
作者又画了 ParseNet 的图,比 ParseNet 原文更直观,只是这里的 fc6, fc7 是 fully Convolutional 吗?感觉很怪啊,一般都是 fully connected
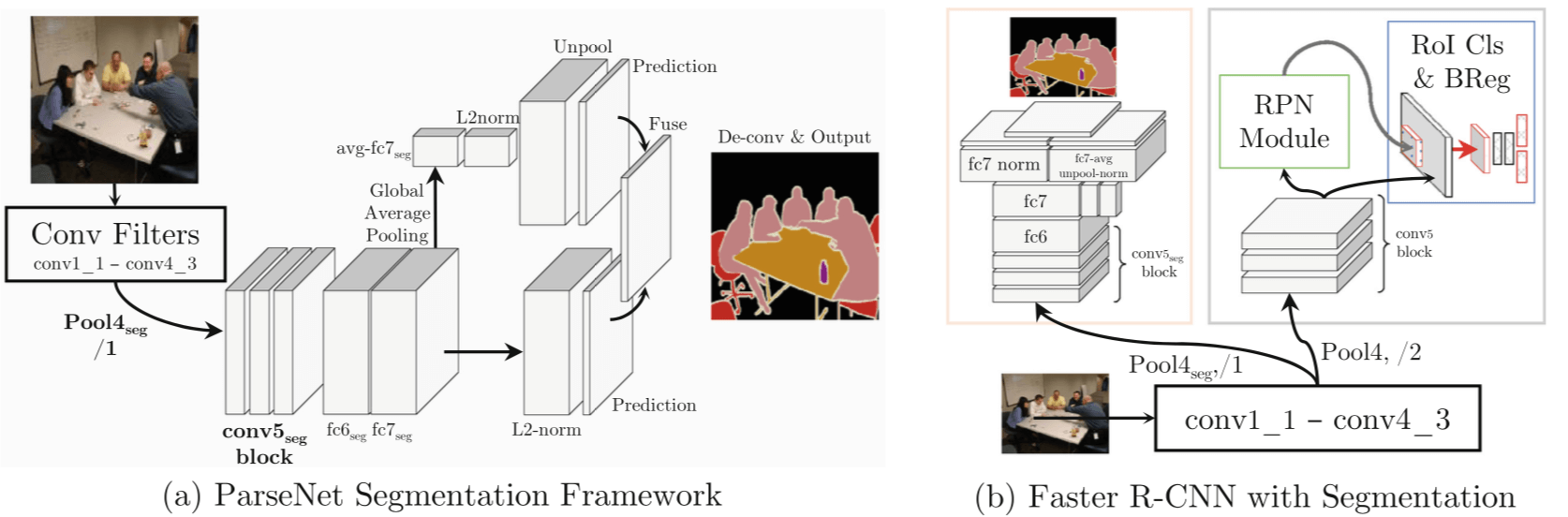
从上图的右图看来,本文的 Faster R-CNN + Segmentation 其实就是增加了一个 Segmentation branch,是一个 multi-task
Segmentation、RPN、Detection 这 3 个模块都要训练
segmentation captures contextual information which will ‘prime’ the region proposal and object detection modules to propose better regions and learn better detectors
the Faster R-CNN modules operate on the conv feature map from the shared network
To contextually prime these modules, their input is modified to be a combination of aforementioned conv features and the segmentation output.
a top-down feedback signal from segmentation ‘primes’ both Faster R-CNN modules 的具体做法如下,下图(a)很好的展示了这个过程
- take the raw segmentation output and append it to the conv4_3 feature
- The conv5 block of filters operate on this new input (‘seg + conv4 3’) and their output is input to the individual Faster R-CNN modules
- append segmentation to the fixed-length feature vector (‘seg + pool5’) before feeding it to fc6
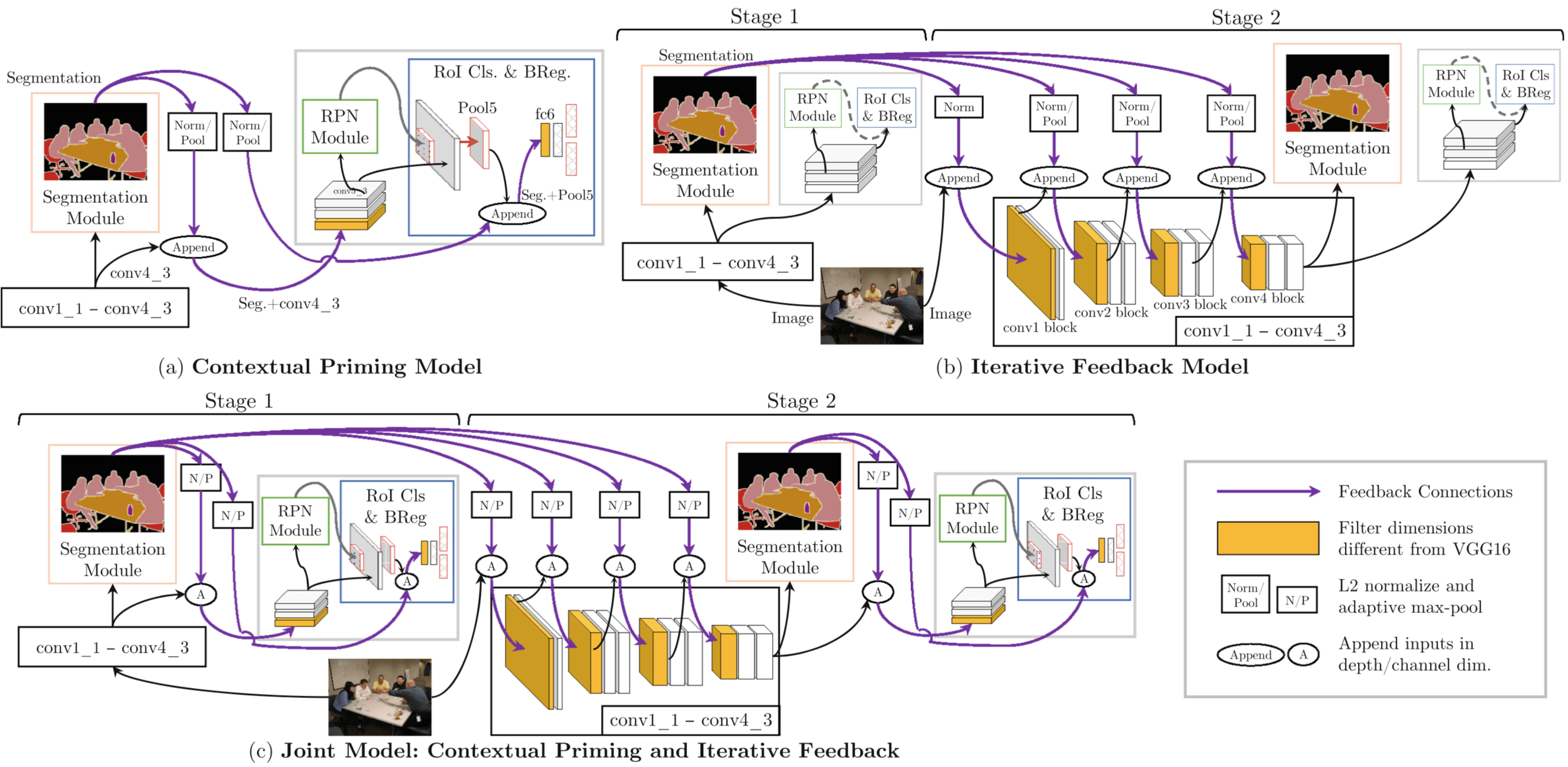
DES 和 本文的不同:DES 是将 Segmentation 的结果作为 权重调制 low-level feature,本文是将结果 concat 到 Low-Level feature 上去
本文的 Top-Down 的知识来自于 另一个任务(Segmentation)
杂记
视觉腹侧通路,负责物体、文字、面孔的识别,即 “是什么”
背侧通路,感知空间关系,即 “在哪里”
双流模型灵感来源于人类视觉皮层中观察到的腹背分解,腹侧流负责识别物体类别,背流同时解释正确抓取所需的几何图形关系
背侧流起始于 V1,通过 V2,进入背内侧区和中颞区(MT,亦称 V5),然后抵达顶下小叶。背侧流常被称为 “空间通路”( Where/How pathway),参与处理物体的空间位置信息以及相关的运动控制,例如眼跳(saccade)和伸取(Reaching)。
腹侧流起始于 V1,依次通过 V2,V4,进入下颞叶(Inferior temporal lobe)。该通路常被称为 “内容通路”( Who/What pathway ),参与物体识别,例如面孔识别。该通路也于长期记忆有关。
To Read List
- CVPR 2018 Learning to Find Good Correspondences
- Quad-Networks: Unsupervised Learning to Rank for Interest Point Detection.
- LIFT: Learned Invariant Feature Transform
- Superpoint: Self-Supervised Interest Point Detection and Description
ORSIm Detector: A Novel Object Detection Framework in Optical Remote Sensing Imagery Using Spatial-Frequency Channel Features
Motivation
Remote Sensing Object Detection 的 challenges
- variabilities in viewpoint
- scaling
- direction(rotation)
- generally small relative to the Ground Sampling Distance (GSD)
- cluttered backgrounds
LF-Net: Learning Local Features from Images
卖点 without the need for human supervision
exploit depth and relative camera pose cues to create a virtual target that the network should achieve on one image, provided the outputs of the network for the other image 没看懂…
use image pairs for which we know the relative pose and corresponding depth maps 什么意思?
warp the keypoints selected in this manner to the other image using the ground truth, guaranteeing a large pool of ground truth matches 是怎么做到的?这里的 warp 是个什么操作
本质上要做的事情是 Establishing correspondences across images
de facto standard 的做法是 sparse methods,find interest points and then match them across images
Superpoint、LIFT 和 Learning to Find Good Correspondences 都需要 hand-crafted detectors to initialize the training process
本文这么厉害,既是 end-to-end,又是 does not require using a hand-crafted detector to generate training data
Typically, feature extraction and matching comprises three stages: finding interest points, estimating their orientation, and creating a descriptor for each
之所以 devise a two-branch setup and create virtual target responses iteratively 的目的是为了 allow training from scratch without hand-crafted priors
LF-Net has two main components.
- The first one is a dense, multi-scale, fully convolutional network that returns keypoint locations, scales, and orientations. It is designed to achieve fast inference time, and to be agnostic to image size.
- The second is a network that outputs local descriptors given patches cropped around the keypoints produced by the first network.
一个是 Detector,另一个是 Descriptor,先 Detector 检测出兴趣点,然后再由 Descriptor 给出 Description,这个和 SuperPoint 不一样,SuperPoint 是并行的,LF-Net 是串行的
standard SIFT still outperforms many modern baselines 的原因在于 their approach still relies on SIFT keypoints for training, and as a result it can not learn where SIFT itself fails. 好的上限不过是 SIFT,却没有学习 SIFT 失败的地方,因此上限就是 SIFT,所以性能肯定差于 SIFT
作者放出了 tensorflow 的代码:https://github.com/vcg-uvic/lf-net-release
A Tutorial on Spectral Clustering
by Ulrike von Luxburg
G = (V, E) 还有 数据点 x,和相似度 s,
问题:
- v 和 x 有什么区别?
- e 和 s 有什么区别?
- 还有 W 和 E、S 有什么区别?
- W 来源于哪里?
similarity graph
主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
The goal when constructing similarity graphs is to model the local neighborhood relationships between the data points
可见 similarity matrix 和 similarity graph 是两回事
weighted adjacency matrix 也不是 similarity matrix
谱聚类方法其核心是构造拉普拉斯矩阵对其求特征值,取最小特征值对应特征向量为聚类向量。
与主成分分析方法相比,谱聚类方法似乎是一个相反的操作。本篇文章便是为了说明谱聚类方法与主成分分析法的相同点与不同点。
在几何上理解,谱聚类方法是将类别看做数据,数据看做维度的对应方法。
与主成分分析方法相比,谱聚类方法中的拉普拉斯矩阵即代表主成分分析方法中的协方差矩阵,拉普拉斯矩阵的特征向量代表类别的主成分方向。
在主成分分析方法中,主成分方向代表大多数数据共同具有的特征方向。比如,第一主成分往往代表所有数据共同具有的最显著的特征方向。
而在谱聚类中,由于维度是由数据构成的,真实的数据是类,故特征方向代表所有类共同具有的数据方向,即体现出了不同类在数据上的共性。故拉普拉斯矩阵大的特征值对应的特征向量代表了不同类共有的数据的方向。一般各个维度上是小数,代表了各数据在该类上的可能性。
故对于谱聚类来说,特征值小的方向代表了各类独有的数据方向。故谱聚类选取的是小特征值对应的特征向量。
整体看来,谱聚类方法是知道了拉普拉斯矩阵,求特征向量,从而逼近原有数据的方法。与主成分分析方法相比是部分相反的
求出拉普拉斯矩阵对应的前 k 个最小的特征值,得到对应的特征向量组成的矩阵 V 后,用 V 来给样本在低维度上进行聚类,相比 k-means 直接对样本聚类会更快
Normalized spectral clustering according to Ng, Jordan, and Weiss (2002) 中的 $U \in \mathbb { R } ^ { n \times k }$ 像是对原始的 the normalized Laplacian 做了降维,降维后每个点的特征只有 k 维了
W 叫作 邻接矩阵
邻接矩阵 的 基本思想是,距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,不过这仅仅是定性,我们需要定量的权重值。一般来说,我们可以通过样本点距离度量的相似矩阵S 来获得邻接矩阵W。
邻接矩阵W 是由 相似矩阵S 得来的,但不是严格相等,比如构建邻接矩阵W 的方法有三类。ϵ- 邻近法,K 邻近法和全连接法,对于 ϵ- 邻近法 就是 小于 ϵ 的 s_ij 才保留,否则为 0,K 近邻则是在 K 个近邻内保留,否则为 0
无向图切图 是在 W 上的啊,那计算 L 干嘛?
谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如 K-Means 很难做到
由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
BA-Net: Dense Bundle Adjustment Network
solve the structure-from-motion (SfM) problem via feature-metric bundle adjustment (BA)
看来要做的是 structure-from-motion,通过 bundle adjustment 来做
可能要看一下这篇 Handa et al. (2016) solve the camera motion by a network from a pair of images with known depth.
这个 3D scene point coordinates 是谁的 coordinates?为什么跟 images 和 camera poses 的数量不一致?
这个 normalized homogeneous pixel coordinate 是哪里来的?
LM 算法我看到下面这个网页:https://zhuanlan.zhihu.com/p/42415718
里面的 h 就是 论文里面的 $ \delta \mathcal{X}$
BA-Net 做了什么?explicitly enforces multi-view geometry constraints in terms of feature-metric error
propose the photometric BA algorithm to eliminate feature matching and directly minimizes the photometric error (pixel intensity difference) of aligned pixels
看来本文走得不是 稀疏特征点抽取的路线
两点:
- $x^T A x$ 相当于 多维正太分布的指数,也就是 马氏距离
- graph Laplacian 为什么叫 Laplacian,因为 D - W 操作其实相当于图像增强领域的 Laplacian Operator,
$$
\begin{array} { | c | c | c | } \hline 0 & { - 1 } & { 0 } \ \hline - 1 & { 4 } & { - 1 } \ \hline 0 & { - 1 } & { 0 } \ \hline \end{array}
$$
都是周围所有邻接之和减去周围
学习与记忆(一): 海马功能在陈述性记忆形成中的作用
海马的旧称叫做 Cornu Ammonis,意为太阳神阿蒙之角,现在仍沿用其缩写 “CA” 指代海马结构的不同部分。海马结构主要包括齿状回(dentate gyrus,DG)、 CA3、CA1 和 下托 (subiculum)四个结构。
后来研究者们发现,启动效应与新皮层(Neocortex)关联;程序性记忆与纹状体(Striatum)有关;联想记忆中的情绪应答(emotional responses)与杏仁核(Amygdala)有关,骨骼肌运动记忆与小脑(Cerebellum)有关;非联想记忆则与反射(Reflexes)有关。
“我眼中的世界”:联合皮层区的认知加工
顶叶皮层包括了一条很重要的信息加工流。
我们知道,视觉的信息加工有背侧和腹侧两条加工流。腹侧加工 “是什么”,而背侧加工 “在哪里”。背侧这条加工流就是从枕叶的初级视觉皮层流向顶叶,因此,顶叶联合皮层具有定位和运动知觉(location and movement perception)的功能。另外,它也与注意(attention)有关。
前面我们讨论到,视觉信息的加工有背侧 “在哪里” 和腹侧 “是什么” 两条加工流。实际上,顶叶和颞叶也各有一条回到枕叶的通路。
研究者们首先发现,枕叶初级视觉神经元的反应受到注意的调节。前文也提到,这个注意调节的热点在顶叶,并且还有偏侧化。用心理学的话来说,认知不仅是自下而上组织的,它也受到自上而下的调节。
语义分割江湖的那些事儿 —— 从旷视说起
FCN 前期阶段,研究重点主要是解决 “网络逐渐衰减的特征尺寸和需要原图尺寸的预测之间的矛盾”,换言之,就是如何解决网络不断 downsample 造成的信息损失
- 希望保存或者恢复信息的 unpool、deconv 等方法
- 进行结构预测的各种花式 CRF 方法
“大道之争” 之中,碰撞出了两个最重要的设计:U-shape Structure 和 Dilation Conv,据此形成当下语义分割领域网络设计最常见的两大派系:
- U-shape 联盟以 RefineNet、GCN、DFN 等算法为代表;
- Dilation 联盟以 PSPNet、Deeplab、ParseNet 系列方法为代表;
随着 Base Model 性能不断提升,语义分割任务的主要矛盾也逐渐渐演变为 “如何更有效地利用 context”;这中间又是一番腥风血雨,我们今天介绍的 3 位主角也在其中贡献了一份力量。