[1] Learning Scene Gist with Convolutional Neural Networks to Improve Object Recognition
IEEE Information Sciences and Systems - CISS 2018 的论文,作者都是哈佛的。
本文的主旨就是要 incorporating contextual gist 吧,关键在于如何 incorporate,如何形成 Contextual gist?
作者首先给了为什么 incorporating contextual gist 的原因,因为人类视觉是这样的,人类就是 foveate on an object and incorporate information from the periphery to aid in recognition.(从之前我对 periphery vision - foveated vision 的理解是先后关系,这里似乎在暗示是并行的关系)
什么是 image gist?从文中看,从一个 scene 中,Observers 可以快速抽取的全局信息。这里的关键词是 global 和 rapidly 吧,满足两者才是 gist。生物上的证据是 In a few hundred milliseconds, observers reliably ascertain summary scene information, even if specific objects are not recognizable。
primate visual system 的 prominent feature 是 eccentricity-dependent sampling, with a high-resolution foveal region and a lower resolution periphery
- The periphery has a decaying density of cells as function of distance from the fovea, and allows for faster approximate perception.
- low-resolution peripheral information provides an initial approximation of the scene gist.
During scene understanding, peripheral information can be used to propose regions of interest for active sampling, and the eyes can then quickly foveate on these regions for high-resolution interpretation. The interplay between foveal and peripheral information may enable faster recognition of objects within a scene with a significantly reduced number of cells. 但事实上,本文的 GistNet 作者并没有利用 peripheral information 来 propose regions of interest for active sampling,而是将其作为特征和 foveated vision 的特征一道来最后分类。
作者怎么描述 Faster R-CNN、Mask R-CNN 这类方法:mirror elements of active sampling via sequential foveation by creating region proposals on the image, followed by object recognition in each region. (是 sequential foveation,对于 Sliding Window 其实也是这样)
- Region Proposal 相较 Sliding window 的优点:Those region proposals cut down on the cost of having to perform classifications on the entire image.
- Region Proposal 相较 Gist 的缺点:Yet, these models lack critical components of contextual information provided by interactions between the fovea and the periphery which are characteristic of human vision:
- a low resolution and rapid peripheral system
- interactions between the periphery and foveal information
- global sharing of information learned across foveations.
- Using global features from the scene gist may reduce the need for additional region proposals, aiding recognition of all objects within the same scene and enforcing all objects in a scene to be influenced by the same prior during inference.
本文跟其他也利用 context 的文章不同在于,其他文章 focus on high-resolution contextual information, semantic context, and object co-occurrences
而本文是在 deep learning based Object Detection 中利用 low-resolution and global gist-like features
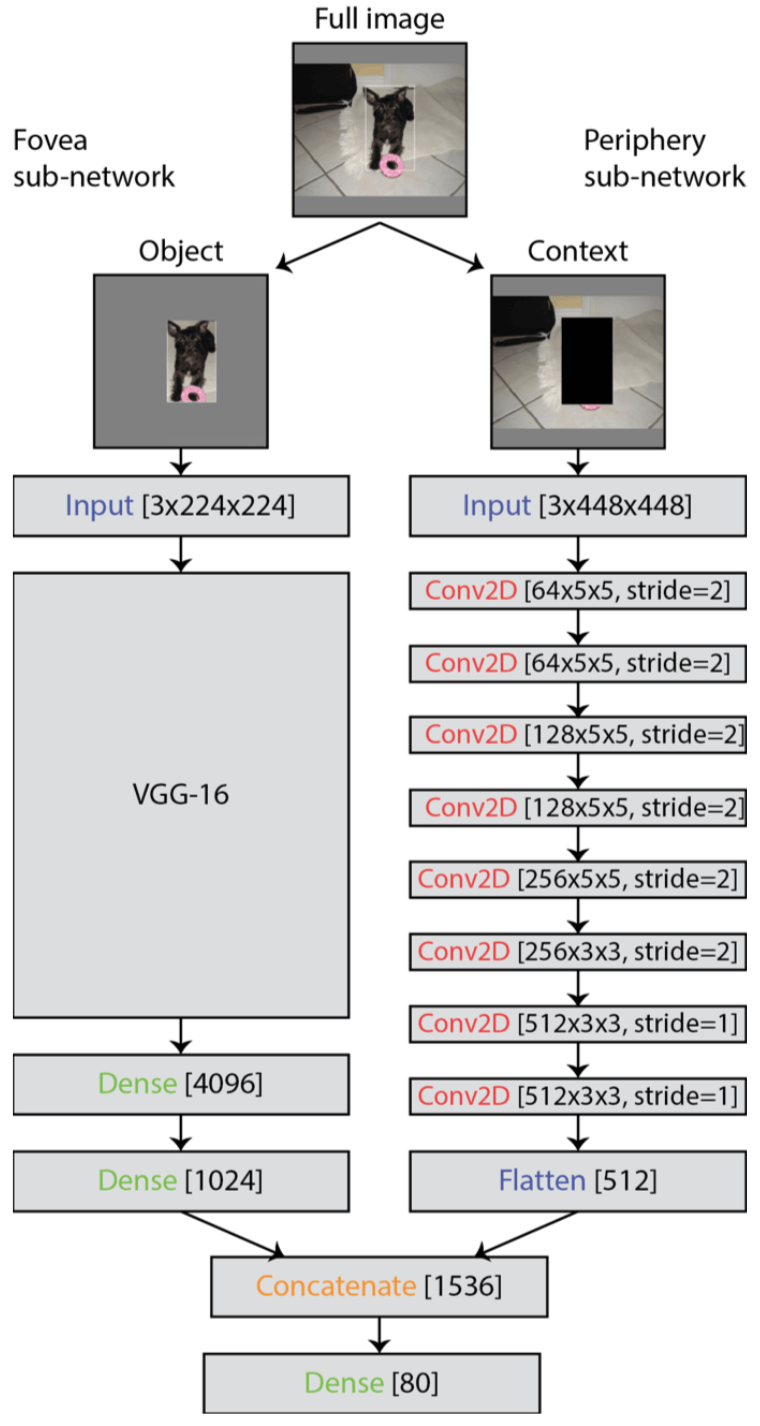
本文提出的网络叫 GistNet,具体如下图所示。看到图还是蛮失望的,这个 a low resolution and rapid peripheral system 由右侧的网络分支构成,所谓的 a low resolution 我想大概体现在 larger kernel size,和最后的 feature vector 长度小于 foveated 分支的 feature vector(刚好是 1/2)吧。
待读
- Zhu, C., et al., CMS-RCNN: contextual multi-scale region-based CNN for unconstrained face detection. Deep Learning for Biometrics, 2017: p. 57-79.
- Chen, X. and A. Gupta, Spatial memory for context reasoning in object detection. arXiv, 2017: p. 1704.04224.
问题
怎么理解?While some approaches utilize information from the entire scene to propose regions of interest, the task of interpreting a particular region or object is still performed independently of other objects and features in the image. 这句话的意思是,虽然有用 Scene Information 来做 Region Proposal 的,但是在 post-Classification 阶段,Region Classification 还是仅仅依赖了局部特征,而作者在本文里做的是把 Global Feature 和 Local Feature 一起作为 Object Feature。
作者要 demonstrate that a scene’s ‘gist’ can significantly contribute to how well humans can recognize objects. 这个跟 gist 那篇论文有什么区别?gist 是用来做 Region Proposal,而本文的 gist Feature 也是作为 Object Feature 的一部分(像是 ParseNet,Attentive Contexts for Object Detection 里面那样)
怎么理解 use a biologically inspired two-part convolutional neural network (‘GistNet’) that models the fovea and periphery to provide a proof-of-principle demonstration that computational object recognition can significantly benefit from the gist of the scene as contextual information. 其实就是描述了一下图 2
[2] POL-LWIR Vehicle Detection: Convolutional Neural Networks Meet Polarised Infrared Sensors
论文就验证了用极化的红外数据 比 仅仅用 intensity 的红外数据效果更好
对比了 Faster R-CNN 和 SSD,前者效果更好
[3] Multi-Channel CNN-based Object Detection for Enhanced Situation Awareness
作者认为 Object Detection is critical for automatic military operations 的难点在于:the object presence is hard to detect due to the indistinguishable appearance and dramatic changes of object’s size which is determined by the distance to the detection sensors
即使 Faster R-CNN 这些方法对于自然图像效果已经不错了,但是对于 the indistinguishable appearance and dramatic changes of object’s size 的 military objects,效果还是不好,所以不能直接照搬。
作者的解决方式是 fusing multi-channel CNNs,combine spatial, temporal and thermal information by generating a three-channel image, and they will be fused as CNN feature maps in an unsupervised manner ??? 什么是无监督?
有一个 ATR Dataset,https://www.dsiac.org/resources/research-materials/cds-dvds-databases/atr-algorithm-development-image-database
207 GB of MWIR imagery, 106 GB of visible imagery
[4] CNN-based thermal infrared person detection by domain adaptation
与一般自然图像目标检测不同的是,person detection 的关键问题也是目标太小,a key aspect and difference is often the relatively small size of the object with regard to the whole image
The KAIST dataset can be considered the current state-of-the-art dataset dataset for thermal person detection under challenging conditions.
作者的做法是:
- In the first step, transform the thermal image data in a way that it is shifted closer to the visible domain
- Then in the second step, the detector model is adjusted to further reduce the remaining gap.
[5] Image Captioning with Semantic Attention
CVPR 2016 的文章。
Image Captioning 是 Computer Vision 和 Natural Language Processing 结合的领域
Top-down Approach:start from a gist of an image and convert it into words;更细致地讲是 Top-down approaches are the “modern” ones, which formulate image captioning as a machine translation problem. Instead of translating between different languages, these approaches translate from a visual representation to a language counterpart. The visual representation comes from a convolutional neural network which is often pretrained for image classification on large-scale datasets [18]. Translation is accomplished through recurrent neural networks based language models.
Bottom-up Approach:come up with words describing various aspects of an image
and then combine them;更细致地讲是 Bottom-up approaches are the “classical” ones, which start with visual concepts, objects, attributes, words and phrases, and combine them into sentences using language models.
本文提出的是 a model of semantic attention, 作用是 learns to selectively
attend to semantic concept proposals and fuse them into hidden states and outputs of recurrent neural networks.
image captioning 的定义是:Automatically generating a natural language description of an image
这是 image understanding 的典型代表啊,比 image classification and object detection 要求更高
One of the limitations of the top-down paradigm is that it is hard to attend to fine details which may be important in terms of describing the image.(这个 details 和语义的矛盾,在 Semantic Segmentation 和 Object Detection 里面也存在)
feedback 是 the key to combine top-down and bottom-up information.
作者对 Visual Attention 的描述是 a feedback process that selectively maps a representation from the early stages in the visual cortex into a more central non-topographic representation that contains the properties of only particular regions or objects in the scene.
作者对 image captioning 中 semantic attention 的定义是 the ability to provide a detailed, coherent description of semantically important objects that are needed exactly when they are needed.
本文的 semantic attention model 的具体性质是:
- able to attend to a semantically important concept or region of interest in an image,
- able to weight the relative strength of attention paid on multiple concepts,
- able to switch attention among concepts dynamically according to task status
[6] Comparative Studies of Passive Imaging in Terahertz and Mid-Wavelength Infrared Ranges for Object Detection
这篇文章比较了 太赫兹 和 中波红外 用于检测隐藏物体(比如衣服遮掩下的刀枪)。结论的话,一言以蔽之,太赫兹可以将隐藏物体可视化出来,而中波红外不行。
红外的波长是在 0.7 μm and 30 μm (430 THz down to 10 THz) ,其中中波红外是 3 μm to 8 μm (100 down to 37.5 THz). 太赫兹是 0.1 THz to 10 THz (wavelengths from 3 mm to 30 μm),也就是说 太赫兹其实和红外刚好是邻居,太赫兹是在频率更低、波长更长的一侧。
穿透衣服的能力,太赫兹高,而中波红外低。
[7] Priming Neural Networks
CVPRW 2018, Oral @ MBCC Workshop
最后一个作者 John K. Tsotsos 的个人主页值得探索一下。
PrimingNN
本文叫作 Priming Neural Networks,意图提出 a mechanism to mimic the process of priming,实质上由于作者认为 Visual priming 就是 an effect of top-down signaling in the visual system triggered by the said cue,所以本文其实本质上也是一个试图模拟 Top-Down 的 Attention 方法,就像 DES。模型方法如下所示:

与 DES 不同的是:
- 这里的 top-down feedback 是影响每一个 layer 的
- DES 里面的 cue 是通过 Weakly Supervised Semantic Segmentation 完成的,而本文好像是给定的 cue 表达(比如含有的类别?cue 是在 label 之外额外的信息)
- DES 是生成一个 Pixel-wise weight map,而 PrimingNN 是 Channel-wise 的 weight vector
Top-down Attention 是什么?
本文这里刻画的是 an effect of top-down signaling in the visual system triggered by the said cue
另一种表述是,Priming / Top-down Attention 是 a modulatory, cue dependent effect on layers of features within a network
Top-down Attention 有什么作用?
本文这里强调的作用是:对于人眼,在知道了 cue 之后可以发现之前 near unnoticeable 的目标;对于计算模型,可以帮助发现纯粹 Bottom-Up 会忽略的小目标,(关键在于给定 cue)
从下图中可以看出,Priming 的一大好处是可以发现许多 small Object,如果不做 priming,这些 small Object 是会被 baseline 给忽略掉的;从左到右分别是input image, ground-truth, baseline segmentation(DeepLab), primed network

怎么建模 Top-down Attention?
本文给出的 Priming 框架是这样的,感觉这里的 Priming 基本就等于 Top-Down Attention 了。是的,按照文章的说法, 也就是说,Visual Priming 就是一个在给定 cue 之后的 Top-down signaling。
- A cue about some target in the image is given by and external source or some form of feedback.
- The process of priming involves affecting each layer of computation of the network by modulating representations along the path.
cue 的来源
cue 是 top-down signaling 的来源,首先第一步是怎么刻画 cue?在这里,cue 是给定的,比如 a binary encoding of them presence of some target(s) (e.g, objects),注意的是,cue 是在 label 之外的信息。这里作者似乎是直接给的,而 DES 里那样是从弱监督语义分割来的。弱监督还是利用的 label 的信息,并没有信息的增益,顶多是相对于 Object Detection 分支,语义分割也许会弥补上一些 Object Detection 分支疏漏的信息。
不过直接给 label 之外的 cue,对于很多场景还是比较难实现的。
cue 的表征
需要有一个 mechanism 来 transforms an external cue about the presence of a certain class in an image (e.g., “person”) to a modulatory signal that affects all layers of the network.
具体这个 mechanism 的实现方式,本文是在原先网络的基础上,增加了一个 add a parallel branch $N_p$。The role of $N_p$ is to transform an external cue $h \in R^n$ to modulatory signals which affect all or some of the layers of $N$.
cue 的调制
Top-down feedback 在本文中的表现就是对 neural network layers 的调制,特别是对低层的 layers 的。
作者认为之前 Priming 的工作没有研究 the explicit role of category cues to prime the visual hierarchy for object detection and segmentation,也就是没有给出具体的调制方式?但 Shrivastava2016ContextualPA 这篇文章是 16 年的,在本文之前啊,作者说 Shrivastava2016ContextualPA 是 append directly the semantic segmentation predictions to the visual hierarchy,回去看了下论文,的确是 append 的方式,而本文是 Residual Multiplication。
$L_i$ 是网络的某一层,$x_i \in R^{c_i \times h_i \times wi}$,所以 $x{ij}$ 就是 $x{i}$ 的第 j 个特征平面,有 $x{ij} \in R^{times h_i \times w_i}$
$$
\hat{x}{i j}=\alpha{i j} \cdot x{i j}+x{i j}
$$
上面这个 Attention 方式跟 BAM: Bottleneck Attention Module 这篇论文里的方式是一样的,看来用 Residual Formulation + an additive model 这种是共识了,论文里也说了试过很多方式,还是这种效果最好。
本文中的 $\alpha_i$ 就是 Attention 模块的参数啦,论文这里用的是一个线性变换,而在一般的 Attention 模块中,都是一个 Squeeze-and-Excitation 结构。
$$
\alpha{i}=W{i} * h
$$
Overview 和 Related Works
作者说有 3 种 detection strategies:
- free viewing:没有 cue 的情况下
- priming:a modification to the computation performed when viewing the scene with the cue in mind(注意,这是在计算阶段)priming often highly increases the chance of detecting the cued object.
- pruning:a modification to the decision process after all the computation is finished(注意,这是在决策阶段)When the task is to detect objects, this can mean retaining all detections match the cue, even very low confidence ones and discarding all others.
我感觉现在主流的方法就是走得这个路线:Viewing the image for an unlimited amount of time and pruning the results is less effective,这里的 pruning 可以是 NMS 这种操作
priming 和 pruning 的差别在于,pruning 只是对于 forward 的 decision 做删减,而 priming 则是 allows the cue to affect the visual process from early layers,就是因为调制了 early layers,所以 priming 才可以 allowing detection where it was previously unlikely to occur in free-viewing conditions。
关于 free viewing,priming,pruning,下图表述的很形象:

Look and Think Twice: Capturing Top-Down Visual Attention with Feedback Convolutional Neural Networks
2015 年的 CVPR,期刊版本是 TPAMI 的 Feedback Convolutional Neural Network for Visual Localization and Segmentation。这是一篇非常棒的论文,解答了自我开始看 Attention 的论文以来一直存在的一个问题,即 Top-down Attention 中 cue 的来源问题。cue 是 Top-dwon Attention 信息流的来源,可以是“这里有只猫”这样的提示,也可以是“船在水上”这样的上下文先验。
在之前的 Zhang2018SingleShotOD、Shrivastava2016ContextualPA 这两篇论文中,这个 Top-down 的 cue 是通过语义分割分支来给出的;在 Rosenfeld2018PrimingNN 中则是给出了 Groundtruth Category 作为 Cue。
Cue 和 Label 不一样,虽然都含有关于 Task 的信息,Label 只有在 Training 的时候才 available 的,而 Cue 则是在 Inference 的时候也是 Available 的。
我第一次看这篇论文的时候没有看明白,现在明白了,这个 feedback layer 其实就是一个 Attention Weight Cube(Saliency Map)。本文本质上上一个 Weakly Supervised Saliency Detection。
之所以叫作 Look and Think Twice 是因为本文的 Image Classification 是 Two-stage 的,是 Image Re-Classification with Attention。
具体算法过程如下:
- Resize image to size 224∗224, run CNN model and predict top 5 class labels.
- For each of the top 5 class labels, compute object localization box with feedback model.
- Crop image patch for each of 5 bounding boxes from original image and resize to 224 ∗ 224. Pre- dict top 5 labels again.
- Given the total 25 labels and the corresponding confidences, rank them and pick the top 5 as final solution.
第一次做 Forward 得到 Image Classification 的结果(Top-5 Category),然后针对每一个 Category,做一次 Feedback,就可以得到相应的 Region,然后再把这个 Region resize 后作为输入再做一次 Forward,就可以看是不是正确的 Category,而且有一个 Score。
所以本文的关键是怎么用一次 Feedback 产生显著性图,而这里的 Feedback 会有点误导,以为是 BP 那样的,其实 Feedback 就是在给定输入和网络权重后,优化 $z$
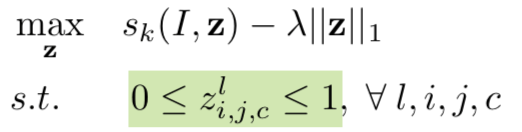
z 可以依据公式(6)用 SGD 求出
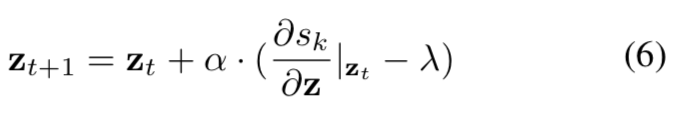
关键就是 z 为什么可以对应着 Category dependent 的显著性图?
如果这图像被认作是 panda,那应该只有 panda 在的部分特征被激活,而其他无关区域应该都是不被激活的。
神经网络里的 attention 机制是(非常)松散地基于人类的视觉注意机制。人类的视觉注意机制已经被充分地研究过了,而且提出了多个不同的模型,所有的模型归根结底都是按照 “高分辨率” 聚焦在图片的某个特定区域并以 “低分辨率” 感知图像的周边区域的模式,然后不断地调整聚焦点。
其实它和我们的直觉恰恰相反。人类的注意力是节省计算资源的。当专注于一件事时,我们能忽略其它事情。(现在的 Attention 反而是增加成本)
作者把现有的 CNN 叫作 feedforward deep convolutional neural networks,这应该说的是做 Inference 的时候,只有 Forward,没有 feedback;而人的视觉 human visual cortex,通常会有比 feedforward 更多的 feedback connections,这就是本文的 Motivation,introduce the background of feedbacks in the human visual cortex,develop a computational feedback mechanism in deep neural networks
具体表现在除了 feedforward inference 之外,还有引入了一个 a feedback loop 来 infer the activation status of hidden layer neurons according to the “goal” of the network
人类视觉还存在一个由上到下任务驱动的注意力机制,在搜索物体的时候,接受来自 由上到下的 刺激,并在反馈回路里压制不相干的神经元。这里其实有个 re-search 的过程,这也是为什么会叫 looking and thinking twice 的原因
偏向注意竞争模型 (Biased competition of selection attention) 可以很好地解释这个过程。该模型的第一个也是最基本的假设就是,同时呈现的多个物体会竞争视觉皮层的神经表征。落在神经元同一接受野 (receptive field) 的多个刺激并不是以独立的方式得到加工的,它们会相互抑制。多个视觉皮层都出现了这种抑制交互,包括 V2, V4, MT, MST 和 IT。出处
“偏好竞争模型”(biased competition model)。根据这个模型,在任何给定的时间,大脑中都有大量的感官信息或认知表征是活跃的,但是大脑的计算资源只能加工有限数量的表征。因此,各种表征总是在争夺神经资源。在这个竞争环境中,注意作为一种选择机制,它可以有偏好地选择某些信息,使其得到更精细的加工。出处 (那是什么决定了 有些表征争夺神经资源成功了,有些失败了? passes the high-level semantic information down to the low- level perception, controls the selectivity of neuron activations in an extra loop in addition to the feedforward process. This results in the “Top-Down” attention in human cognition,这就是 top-down 机制,但究竟什么是 top-down 机制,还不够清楚)
这里说的反馈,不是指在 Training 时候的反馈,而是 Train 好之后权重都固定下来之后做 Inference 的时候,目前的前馈网络就只有一个简单的前馈,而在人脑里,即使是在做 Inference 的时候,高位皮层对低位皮层还是有调节作用的,那就不是一个简单的 Forward 了
怎么看待目标检测?
目前的 Object detection and localization 用的都是 treating detection / localization as a searching process with clear “goals.” 这个范式。
为了实现 searching,要么用 Sliding window,要么用 Region Proposal,然而这么做既 computational intensive 又是 naturally bottom-up: selecting candidate regions, performing feed-forward classification and making decisions.
问题
本文的工作/贡献是提出了一个 Feedback Convolutional Neural Network,这个究竟是什么?为什么可以实现 selectivity by jointly reasoning outputs of class nodes and activations of hidden layer neurons during the feedback loop.
本文网络的 Inference 有两阶段:
- during the feedforward stage, the proposed networks perform inference from input images in a bottom-up manner as traditional Convolutional Networks
- while in feedback loops, it sets up high-level semantic labels, (e.g., outputs of class nodes) as the “goal” in visual search to infer the activation status of hidden layer neurons.
怎么理解论文说的 feedback networks add extra flexibility to Convolutional Networks, to help in capturing visual attention and improving feature detection.
Inspired by Deformable Part-Based Models (DPMs) [8] that characterize middle level part locations as latent variables and search for them during object detection, we utilize a simple yet efficient method to optimize image compositions and assign neuron activations given “goals” in visual search.
作者认为 Deconvolutional Nerual Networks 也是 formulate the feedback as a reconstruction process within the training stage.
Biased Competition Theory 里面的 feedback or “Top-Down” attention 的?passes the high-level semantic information down to the low- level perception, controls the selectivity of neuron activations in an extra loop in addition to the feedforward process.
作者认为 Feedback、visualization of CNN 和 object localization 这三者很像,目的都是 project the high-level semantic information back to image representations.
visualization of CNN 是 shows semantically meaningful salient object regions and helps understand working mechanism of CNNs.(这的确跟 Localization 很像,因为你要先决定要展示的区域)
Object detection and localization 可以被认作是 a searching process with clear “goals.”
这个 “searching” 的刻画方式要么是 sliding window,要么是 region proposals,但是这两个方式都是 computational intensive and naturally bottom-up: selecting candidate regions, performing feedforward classification and making decisions.
既然 CNN 可视化出来都是有意义的区域,那么这个 detection / localization 就可以通过 utilizing the saliency maps generated in feedback visualizations 来实现,这里有 feedback 什么事?这里的 feedback 指的是 the gradient of each class node with respect to image 吧?
这样一来,问题就成了 how to obtain semantically meaningful salience maps with high quality for each concept?这是这篇文章的 the ultimate goal
我想,本文的关键在于作者 reinterpret behaviors of ReLU and Max-Pooling layers as a set of binary activation variables z ∈ {0, 1} instead of the max() operation
behaviors of ReLU and Max-Pooling could be formulated as y = z ◦ x, where ◦ is the element wise product (Hadamard product)
y = z ∗ x, where ∗ is the convolution operator and z is a set of convolutional filters except that they are location variant.
在这种解释下,ReLU and Max-Pooling layers 可以被视为 “gates” controlled by input x, the network selects information during feedforward phases in a bottom-up manner, and eliminates signals with minor contributions in making decisions.
把这些看做是 gates 之后,一个可行的提高特征判别性的方法就是,turn off those gates that provide irrelevant information when targeting at particular semantic labels,而这个“关门”行为就是 biased competition theory 中的 selectivity,这个“关门”行为也是实现 top-down attention 的方式
作者是在 relu 后面加了一层 feedback layer,这个 layer 就是一群 binary neuron activation variables
所以本文其实是 ReLU 和 feedback layer 一起构成的 a hybrid control unit,ReLU 负责 Bottom-Up,feedback layer 负责 Top-Down
Bottom-Up Inherent the selectivity from ReLU layers, and the dominant features will be passed to upper layers;
Top-Down Controlled by Feedback Layers, which propagate the high-level semantics and global information back to image representations. Only those gates related with particular target neurons are activated.
这篇文章就跟之前看的 PrimingNN,DES 很不一样了,之前的文章都是通过点乘上 Weight Map 的方式,而
- Zhang2018SingleShotOD: Single-Shot Object Detection with Enriched Semantics
- Shrivastava2016ContextualPA: Contextual Priming and Feedback for Faster R-CNN
- Rosenfeld2018PrimingNN: Priming Neural Networks
Exemplar-Driven Top-Down Saliency Detection via Deep Association
2016 CVPR
Bottom-up visual saliency is stimulus-driven, and thus sensitive to the most interesting and conspicuous regions in the scene.
Top-down visual saliency, on the other hand, is knowledge-driven and involves high-level visual tasks, such as intentionally looking for a specific object.
bottom-up saliency detection 是 task-free nature,can only capture the most salient object(s) in the scene.
top-down saliency aims to locate all the intended objects in the scene, which can help reduce the search space for object detection.(top-down 才可以减少 search space)
learn the “knowledge” that guides top-down saliency detection, from a set of categorized training data
knowledge 可以来自于 memory,比如 locating salient objects in the scene using knowledge from training data,也可以来自于 object association,比如 locating objects in the scene using known or unknown exemplars
Comparison of Infrared and Visible Imagery for Object Tracking: Toward Trackers with Superior IR Performance
2015 CVPRW
不同于可见光图像,IR 有自己的特点,这个特点来源于成像方式的不同:
- 可见光图像是物体反射光成像,而红外(非 NIR)是物体直接的黑体辐射成像,温度以及大气窗口才是决定辐射强度的关键,由于是物体自身温度决定的,因此 IR 图像相比可见光通常很少有纹理。灰度变化也相对平缓(对于人这样均匀分布热量的),对于飞机这种不一样,引擎那边会很亮。
但也有好处:its bright spots that correspond to the heat sources make it easy to correlate in between frames
还有一个缺点是:the edge responses in an IR image are typically more noisy and hence background clutter strongly conceals the target features that are already not very strong in the IR image.
in the visible image, the contours of the target can be easily segmented
作者观察到的是:feature based discriminative tracking approaches 用到 IR Imagery 上会有一个很大性能损失,而 template based simpler correlators 对于从 visible band 到 Infrared band 的转变到时不怎么敏感
根本问题是 scarcity of discriminative features
Meeting
https://zhuanlan.zhihu.com/p/51514687
把 ResNet 理解成 PDE
这是 ResNet,写成如下式
Single-Shot Refinement Neural Network for Object Detection
two-stage approach (e.g., Faster R-CNN) 的优点是 achieving the highest accuracy
one-stage approach (e.g., SSD) 的优点是 high efficiency
作者的想法是 To inherit the merits of both while overcoming their disadvantages
RefineDet 由两部分构成
- the anchor refinement module:这个 module 的目的是
- filter out negative anchors to reduce search space for the classifier
- coarsely adjust the locations and sizes of anchors to pro- vide better initialization for the subsequent regressor.
- the object detection module:这个 module 的目的是
- takes the refined anchors as the input from the former to further improve the regression accuracy and predict multi-class label
此外作者还设计了 a transfer connection block to transfer the features in the anchor refinement module to predict locations, sizes and class la- bels of objects in the object detection modul
文章认为 One-Stage Method 不如 Two-Stage Method 的原因在于 class imbalance problem
一些在 One-Stage Method 中来处理 class imbalance problem 的相关工作:
- Kong et al. [23] use the objectness prior con- straint on convolutional feature maps to significantly reduce the search space of objects
Two-Stage Method 相比 One-Stage Method 的优势:
- using two-stage structure with sampling heuristics to handle class imbalance
- using two-step cascade to regress the object box parameters
- using two-stage features to describe the objects