论文
[1] Non-local Neural Networks
Self-Attention 的代表作,按照 Self-attention 自注意力,就是 feature map 间的自主学习,分配权重 这个定义,的确 non-local neural networks 是算 Self-attention 的
首先对输入的 feature map X 进行线性映射(说白了就是 111 卷积,来压缩通道数),然后得到θ,Φ,g 特征
通过 reshape 操作,强行合并上述的三个特征除通道数外的维度(其实就是对每个像素点都拉成向量,但是还保留 Channel 数,也就是变成 THW C 这样的矩阵),然后对θ,Φ进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系)(跟协方差的区别是协方差要求做中心化,而这个没有,也就是说这个就是一个自相关系数矩阵,最后这个自相关系数矩阵的大小会是 THW THW)
然后对自相关特征 以列 or 以行(具体看矩阵 g 的形式而定) 进行 Softmax 操作,得到 0~1 的 weights,这里就是我们需要的 Self-attention 系数(每个像素都有一个 THW 的 weight 向量)
最后将 attention 系数,对应乘回特征矩阵 g 中,然后再上扩 channel 数,与原输入 feature map X 残差一下,完整的 bottleneck (怎么乘回去?g 是 THW * C,是的,就是 一个像素,有一个 THW 的 Attention 系数,分别跟 THW 像素相乘,得到后的加权平均值就是 这个像素位置最终的相应,就跟 NLM 一模一样,只不过这里的范围就是 THW 而不只是一个 search window,输入是 THW $\times $ C,mask 计算出来是 THW $\times $ THW,最后的输出是 THW $\times $ C 和输入一样大),这里的 Attention 就是与本像素特征相似度高的 特征 权重大,是这么体现出来的;在卷积里面本来计算一个输出的数值就会用到所有输入的channe,只不过因为 卷积是 sparse 的原因,Spatial 上很多都没有用到,而 non-local 计算 mask 则是 Spatial 和 channel 上都用到了
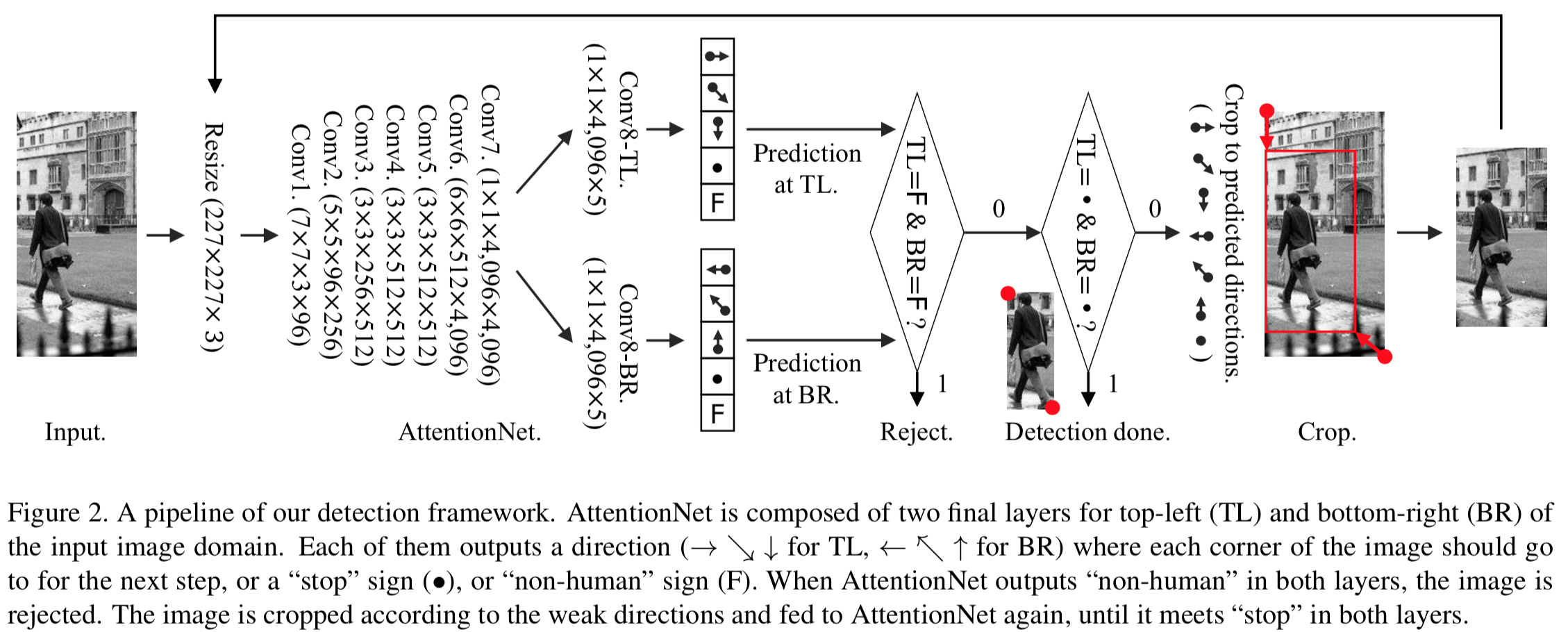
[2] AttentionNet: Aggregating Weak Directions for Accurate Object Detection
最大的贡献应该在于 提出了一条 不同于主流的 Detection based on Region Proposal Classification 的方式,抛弃了 Region Proposal - Classification - Bounding Box Regression - Non-maximum Suppression 这种范式,本文提出的方式是 Object Detection by Aggregating Weak Directions,将 object existence estimation 和 bounding box optimization 集成到了 a single convolutional network 之中
具体的检测方式如下图所示
[3] Attention to Scale: Scale-aware Semantic Image Segmentation
论文把 目前利用 multi-scale features 的策略概括为两种:
- 一种叫作 skip-net, combines features from the intermediate layers of FCNs
- 另一种叫作 share-net, resizes the input image to several scales and passes each through a shared deep network
这篇论文的 Motivation 就在于,之前 share-net 计算出来的最后的特征图往往就是通过 average pooling 或者 max pooling 融合的,而本文则是想对这些不同 scale 下的 features map 做一个 加权平均,得到最后融合的 feature map。
那么这个 权重 是怎么计算出来的呢?这篇文章里面的 Attention Model 也就是权重计算机制也是一个 FCN,这样才能够输出同样 dense 的 weight map,跟做分割的 FCN share 前面的若干层。
具体模型图如下图所示
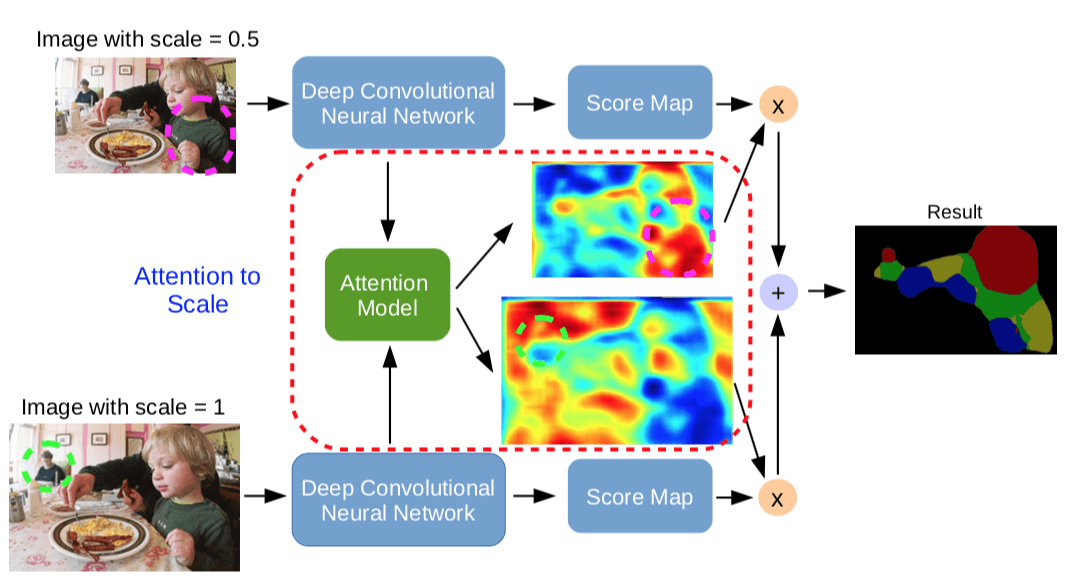
这篇文章给我最大的感觉就是 这也能 train 的动么?负责计算 score map 和 weight map 的两个分支有什么区别? 可以保证各自履行各自的职责?
[4] Squeeze-and-Excitation Networks
convolution operator 作为 CNN 的核心,其实是一个 Information combination,作用是 construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer,在局部感受野上,将空间上(spatial)的信息和特征维度上(channel-wise)的信息进行聚合的信息聚合体
之前的工作主要关注 spatial relationship,以期增强 spatial encodings 的质量,具体的例子就是 Inception 家族的架构,通过在一层中加入 multi-scale 的滤波器来提升特征的表示能力;Inside-Outside 网络中考虑了空间中的上下文信息;Spatial transformer networks 将 Attention 机制引入到空间维度上
本文的 Motivation 很自然,既然特征有 spatial relationship 和 channel relationship,而增强 spatial relationship 可以取得良好的效果,那么去增强 channel relationship 也应该能获得良好的效果。
本文的工作是提出了一个 “Squeeze-and-Excitation” (SE) block 这样一个新的 architectural unit,关注 channel relationship 而不是像之前工作那样关注 spatial relationship,SE block 的作用是 adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels
SE block 是一个新的 architectural unit,跟 Batch Normalization、convolution operator 一样是网络的一个组件。
SE block 做的活叫作 feature recalibration,特征重校准,learn to use global information to selectively emphasise informative features and suppress less useful ones,这就是典型的 Attention 模块,就是通过学习的方式来自动获取到每个特征通道的重要程度(这就是 Attention 的 weight),然后依照这个重要程度(weight)去提升有用的特征并抑制对当前任务用处不大的特征
盗一下 PPT 上的图:
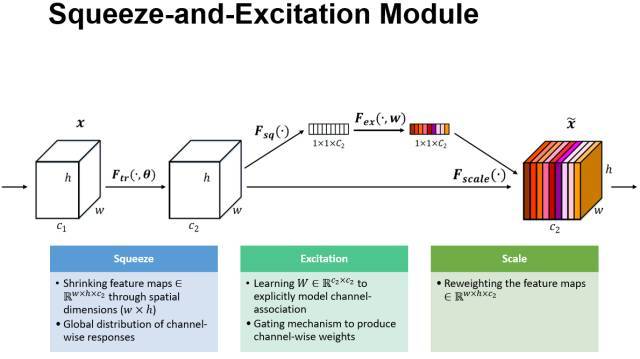
具体的流程就是 先 global pooling 得到 channel 长度的向量,然后通过 FC 和 sigmoid 出权重。
本质上 SE Block 就是一个 Attention Module,计算的是 Channel-wise weight,Squeeze-Excitation 这两个操作负责计算 Channel-wise weight,最后的 Reweight 操作就是把 Channel-wise weight 与 feature map 点乘,这个乘上各自 weight 的过程,论文里面就叫 对原始特征的重标定。
知乎上 Greg Huang 提的问题如下,让我也思考了一阵
请假一下,按理说普通网络顶层接的卷积或全连接层应该会自动挑选、组合底层的特征啊,为什么还要明确让网络加权一遍?
网络自己决定的权重是通用的,通过网络输出 attention 权重是根据当前图片决定的。 by 王峰,这句话我没看懂
区别就是….attention 的 weight 是 data dependent …conv 的权重是训练完之后就固定了 by Alan Huang
我个人的理解是,虽然 SE Block 的操作顺序是 output_feature = attention_weight (conv_filter input_feature),但因为卷积是线性运算,有结合律,也等于 output_feature = (attention_weight conv_filter) input_feature,就相当于最后的 conv_filter 的权重实现了根据 data 的自适应。由此也就有了 网络自己决定的权重是通用的,通过网络输出 attention 权重是根据当前图片决定的。
为什么拿 SE Block 做 Attention 效果会好?
大网络 channel 维度有很多冗余,se 操作能起到很强的正则化作用,防止过拟合,有助于抽出更好的特征 by Wheatley
注意到这个加权利用到了全局信息,而在传统的 CNN 只有到最后才综合全局信息。 by ling wei
SE 和 NIN 的关系
NIN 和 SE 其实都是对卷积层 map 在 channel 这个纬度的非线性变换,区别是 NIN 的输入是局部 patch,而 SE 的输入是全局 map。这两种结构具备一定的互补性。
NIN 和 SE 其实都是对卷积层 map 在 channel 这个纬度的非线性变换 这一点可以理解;为什么说 NIN 的输入是局部 patch 这一点不理解
SE 可以看做是 1*1 的卷积重新调整权重的特殊情况,如:输入 m 通道的特征输出也是 m 通道, $1 \times 1$ 的卷积相当于是 $m \times m$ 的矩阵系数;而特征重标定只是 $m \times m$ 的矩阵系数的一个特例:对角矩阵。 by 侯凯
私以为,其实是 reweight 操作,也就是特征重标定,可以看成 $1 \times 1$ 的卷积的特殊情况,$m \times m$ 的矩阵系数的一个特例:对角矩阵;但并不是整个 SE Block,除了 reweight 外,SE Block 还有 Squeeze-and-Excitation 操作,有 Global Average Pooling,还带有 bottleneck 的两层 FC,而 $1 \times 1$ 的卷积的矩阵系数是固定的,而 SE Block 的 reweight 操作的矩阵系数则来源于前面 Squeeze-and-Excitation 操作 data-dependent 的输出。
[5] BAM: Bottleneck Attention Module
BMVC 2018
Motivation
SENet 只对 Channel 维度上做了 Attention,忽略了 Spatial 维度,只告诉了网络应该关注哪些 channel 的特征(what),没告诉网络应该关注哪些区域的特征(where),BAM 就是显式地对 Channel 和 Spatial 两个维度做 Attention,explicitly learn ‘what’ and ‘where’ to focus on.
BAM is a self-contained adaptive module that dynamically suppress or emphasize feature maps through attention mechanism
为什么 BAM 效果会好?用论文中的话来说,BAM denoises low-level features such as background texture features at the early stage. BAM then gradually focuses on the exact target which is a high-level semantic.
Architecture
具体的结构如下图所示,这是一个 a residual learning scheme
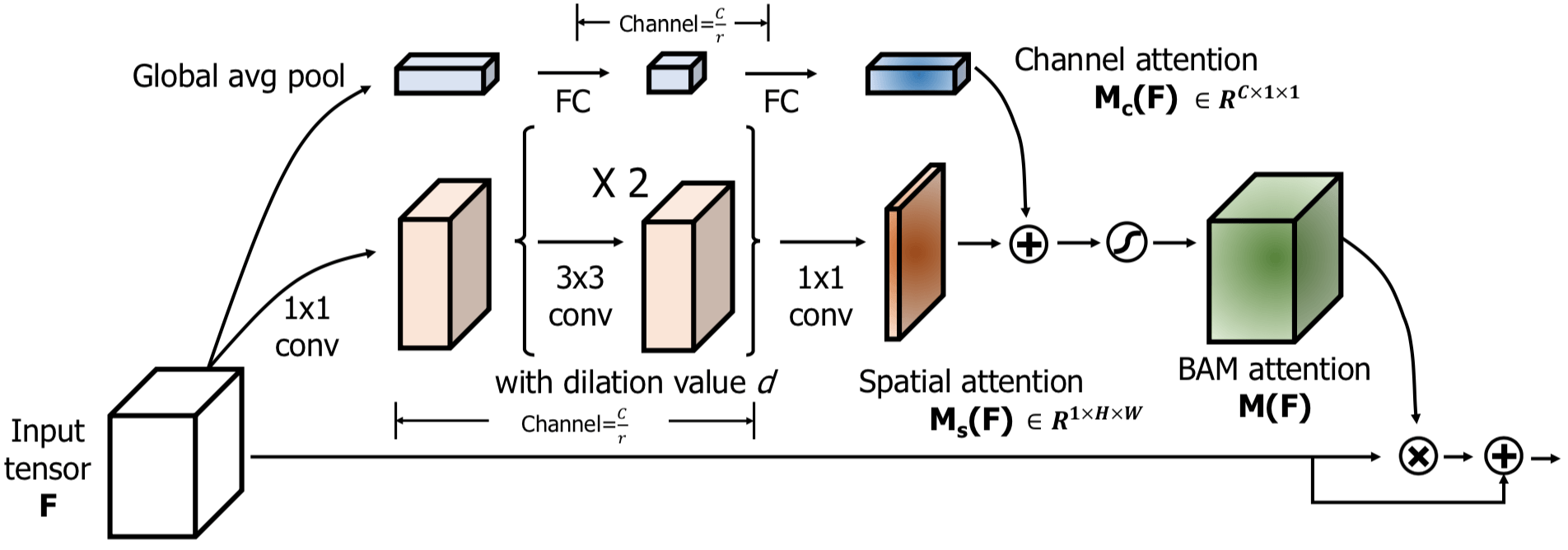
the channel attention $M_c(F)$ 是 长度为 C 的向量;the spatial attention $M_s(F)$ 是 $H \times W$ 的矩阵;最终的 attention map $M(F)$ 计算方式如下。显然两者尺寸不匹配,是没法直接相加的,因此在相加前彼此都要做 broadcasting,变成 $C \times H \times W$ 的张量后再相加
$$ M(F) = \sigma (M_c(F) + M_s(F))$$
Channel attention branch 基本跟 SE Block 一样,最后有一个 BN
Spatial attention branch 先用 $1 \times 1$ 卷积将通道数变成原来的 1/r,然后再两个 $3 \times 3$ 的 dilated conv,最后再是一个 $1 \times 1$ 卷积将通道数变成 1。
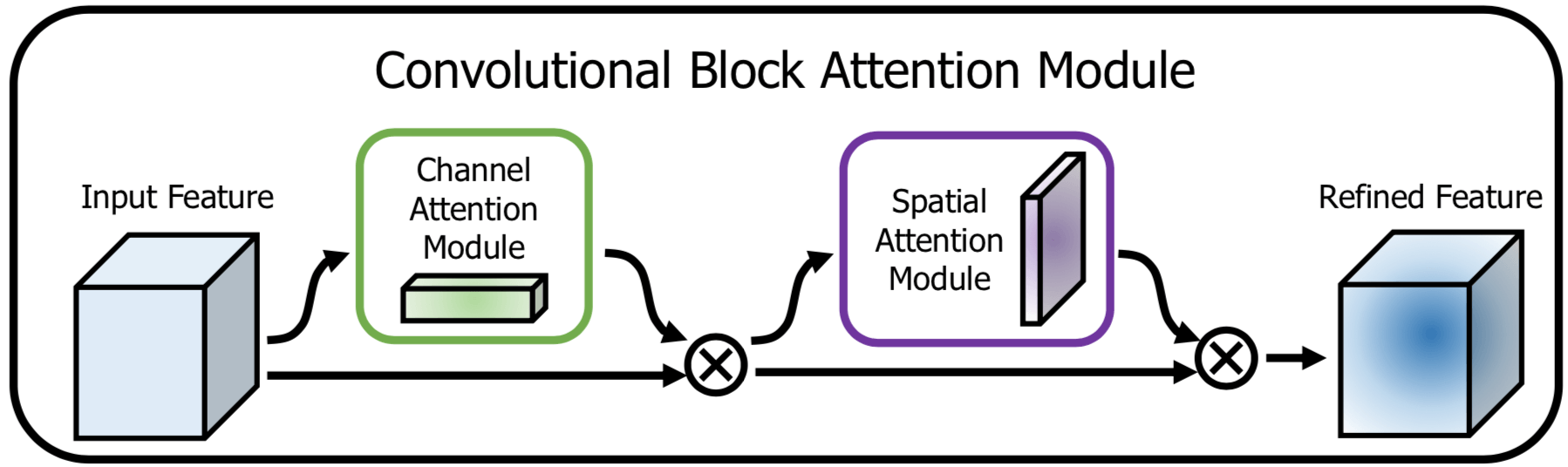
[6] CBAM: Convolutional Block Attention Module
ECCV 2018,这篇还是 KAIST 的论文,作者和 BAM: Bottleneck Attention Module 那篇一模一样,只是一二作者顺序换了一下。第一作者 Sanghyun Woo 还是个硕士生,导师是最后一个作者 In So Kweon。
ECCV 2018 的 Submission Deadline 是 Mar 14, 2018;BMVC 2018 的 deadline 是 7 May 2018,基本是同时的。
Attention 干的事情就是 adaptive feature refinement。
为什么用了 Attention 效果会好?Attention not only tells where to focus, it also improves the representation of interests.
Attention 机制通过 focusing on important features and suppressing unnecessary ones 来 提高网络的表示能力
CBAM 和 BAM 的不同
BAM 中 Channel 和 Spatial 两个 sub-modules 是并行的,而 CBAM 中这两个是串行的(sequentially apply channel and spatial attention modules)。具体方式如下
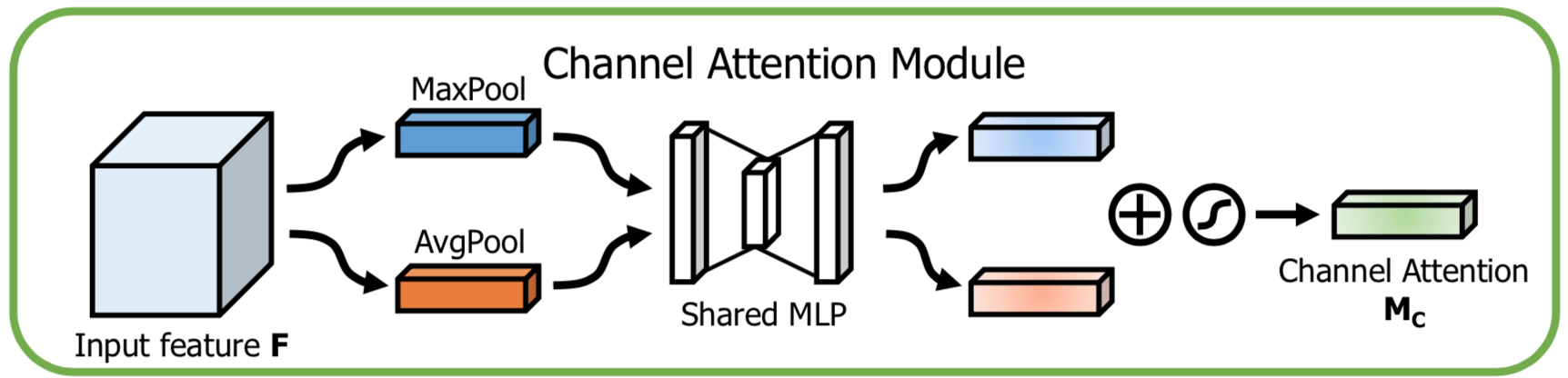
BAM follow 了 SENet,在 Channel attention module 内做 aggregating spatial information 用得还是 Global Average Pooling;CBAM 同时用了 Global Average Pooling 和 Global Maximum Pooling,因为 max-pooling gathers another important clue about distinctive object features to infer finer channel-wise attention. 那么 Global Average Feature 和 Global Maximum Feature 是怎么融合的呢?两者是在通过了 Shared MLP 模块后才将得到的 Feature 相加起来,下面的示意图把这个过程展示得很清楚了
公式也非常清楚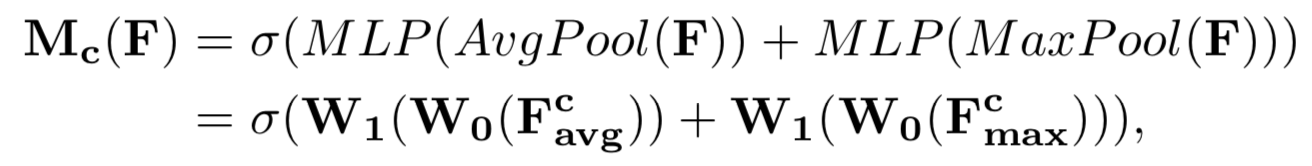
在 BAM 中,Spatial attention module 内 Channel 维度的变换(最终压缩成 1 维)是通过 1*1 卷积核实现的;在 CBAM 中,是直接对 Channel 维度做 Average Pooling 和 Maximum Pooling,各自得到 $1 \times H \times W$ 的 feature map,然后再 concatenate 起来,这就是 $2 \times H \times W$ 的 feature map,然后再通过一个标准的卷积变换到最终的 $1 \times H \times W$ 的 feature map,具体公式如下
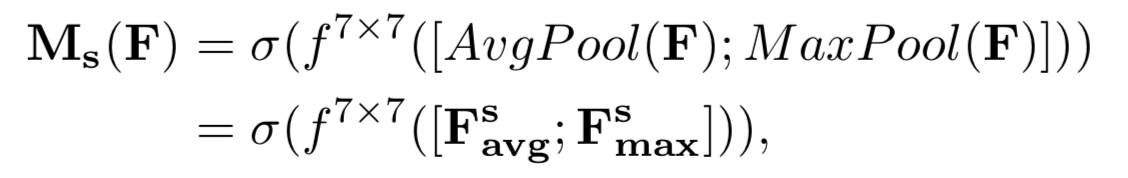
说白了 BAM 就是 parallel manner,CBAM 是 sequential manner,作者在论文里说了 sequential arrangement 效果更好。
Considering this, two modules can be placed in a parallel or sequential manner. We found that the sequential arrangement gives a better result than a parallel arrangement.
[7] Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks
NIPS 2018,作者就是 SENet 的作者。
Convolution operator 是一个 local operator,SENet 成功的地方就是通过 Squeeze 操作(实际用 Global Average Pooling 实现,本质上是一个轻量级的 context aggregator),可以让网络在早期就能够有 Global 信息的指导。用论文中的话来讲,这个思路叫作 capturing contextual long-range feature interactions,也就是 context exploitation。
为什么要追求 context exploitation?因为更大的 context 有助于 resolving local ambiguities。
与 SENet 由 Squeeze-Excitation 两个操作组成一样,GENet 也是由以下两个操作组成,且功能类似:
- a gather operator, which aggregates contextual information across large neighbourhoods of each feature map;
- an excite operator, which modulates the feature maps by conditioning on the aggregates
作者是受 bag-of-visual-words 的成功启发的,bag-of-visual-words 就是一个 从 local descriptors 中 pooling information 来构建一个 global image representation 的成功典范,从 local 到 global;与 bag-of-visual-words 类似,Convolutional operator 抽取的也是一个 local descriptor,而我们同样需要比 local 更大范围的 contextual 信息的指导。
与 SENet、BAM、CBAM 的关系
SENet 是只对 channel 做权重;GENet、BAM、CBAM 都是对 Spatial 和 channel 做权重(也就是整个 feature map tensor 的每个点);其中,SENet 是 GENet 的特殊情况,当 selection operator 的范围是整个 feature map 的时候,形式就和 SENet 一样的,是对一个 channel 里的所有点都施加一样的权重。具体的来说,SENet 是 GENet 的 gather operator 是 不含参数的 global average pooling 操作,excite operator 是一个 全连接层时候的特殊情况。
Spatial Attention Module 里,SENet 因为没有对 Spatial Axis 做 Attention 所以跟其他三个都不同;BAM 和 CBAM 是分成 Spatial Axis 和 Channel Axis 两个维度来,对于 Spatial Attention 算出来的权重,这个 Spatial location 的所有 channel 上的都一样,所以最后 Spatial Attention Weight 和 Channel Attention Weight 融合还有一个 broadcasting 的过程;而在 GENet 中是对 3D feature tensor 逐个 pixel 计算过去的,Spatial 和 Channel 并没有分开,反映在Channel 和 Spatial 上的每个 pixel 都会被依次遍历;因为 context patch 是 2D 的,即使是同一个 Spatial location,不同 Channel 上的 Spatial weight 也是不同的。
[8] 高分辨率遥感影像目标分类与识别研究进展
地球信息学报,2015 年 9 月
作者理解下的高分辨率遥感影像目标分类与识别的 pipeline / sub-module:
- 图像预处理,广义的遥感影像预处理包括图像的滤波、降噪、增强、定位、校正、配准、融合及特征的提取和降维等过程;狭义的预处理一般指降噪、增强、特征提取和降维等处理过程(狭义相比广义少了定位、校正、配准、融合这些,看得出来一个是 real-world 要走的流程,一个是给只有 ML 背景、没有遥感背景的人的流程)。
- 目标检测:对场景内目标是否存在进行检测
- 场景分类:是学习和发现图像与场景语义内容标签的一个映射过程;场景通常包含多个目标, 场景分类也是图像理解的关键课题;属于整体的图像理解的研究范畴
- 目标分类:目标一般是在图像分割后的切片
- 目标识别:在已知目标种类的情况,标识出目标的具体型号;目标分类将目标归为一种已知的物体类型,而目标 识别则要进一步根据目标特征进行区分。(在这篇文章的语境里,目标识别是类似于细粒度分类,乃至 re-identification 的概念)
作者理解下的本质
- 目标特征提取的本质是把信息冗余的高维度原始图像信息投影到有利于分类和识别的低维特征空间中
- 目标识别的本质是一个由原始数据模式空间或特征空间到高层对象或类别语义的映射过程。
- 高分辨率遥感影像目标分类与识别的本质是现实世界的地物对象的时空认知,通过对图像感知和解译,再现和提取地物的现实信息过程
各 sub-module 亟待解决的问题
- 图像预处理:需要描述能力强、易于分类识别的图像特征;统计特征、纹理和边缘特征普遍 存在计算量大,特征分布稀疏,特征维度偏高等特点;而变换和滤波特征又存在表示能力不强,语义不明确等问题
- 遥感影像目标检测研究存在的主要问题是目标检测针对性较强,缺乏通用和鲁棒性目标检测模型和算法。
- 场景分类:中层语义场景分类在一定程度上缓解语义鸿 沟的问题,但对场景尺度变化、传感器拍摄角度和时间的差异、语义对象组合变化往往缺乏有效措 施。
- 目标分类:全局特征往往鲁棒性不强,局部特征缺乏空间描述,二者都存在较大的局限性。急需研究新颖的、描述能力强,计算复杂度低的特征来描述和表示目标的语义。需要进一步利用目标对象的视觉认知层次性,综合考虑对象的稀疏 表示、语义主题特性,以及目标之间的空间语义,设计目标的认知分类模型,提升算法识别率和鲁棒性。
- 目标识别:目标识别目前存在的主要问题,是遥感影像目标背景复杂、图像分辨率不同,特征表现出的差异较大。对于可见光和红外影像要有效消除复杂背景信息对识别的干扰;对 SAR 和 SAS 图像则需进一步寻求准确、稳健的特征描述,综合考虑目标轮廓和 遮挡阴影,对目标进行分割和姿态估计。
当前研究存在的主要问题 & 未来发展方向
问题
- 在复杂背景容易造成目标检测虚警率过高问题,视觉显著性的利用是目标检测重要手段。
- 遥感影像目标识别的核心是建立图像低层特征和高层语义对应关系。几乎所有目标识别算法都是以自低向上的视觉数据驱动算法,而自顶向下的任务驱动在目标识别所起的重要性不容忽视。
方向
- 建立多尺度的高分辨率遥感影像场景认知 模型,以满足 TCR 系统的性能需求
- 实现面向对象的多层次高分辨率影像目标 识别处理,以提升遥感影像的“像元-对象-特征-目标-场景”复杂语义映射的精度问题(这里的对象,在这个语境下有点类似于超像素的意思)
- 利用并行计算机制,建立快速高效的分类 识别算法,以适应遥感影像大数据提供快速检测、 分类和识别任务
神经计算在低级视觉研究取得一定成果,但在 高级视觉和神经推理研究,以及高级视觉对中、低 级视觉的反馈影响方面尚缺完善的模型。遥感影 像内含大量语义信息,缺乏复杂图像结构的分析和 表示,以及综合整体认知和局部分析的神经推理框 架。仅靠现有神经计算技术无法整体实现图像理 解的表示、存储、认知、学习、推理和理解等过程,必 须和高层次的认知计算结合才能有效解决 TCR 问题。
遥感影像的地学属性具备复杂的不确定性的 层次语义,遥感影像所反映地学的对象信息不完 备。现有的认知架构存在片面性和不完整性,尚缺 乏针对遥感影像 TCR 的认知模型。因此,考虑地学 信息深层次规律、不完备的遥感影像信息和人类认 知特性,建立合理的遥感影像认知计算模型,是实 现遥感影像智能信息处理的一个挑战。
由于遥感影像智能解译涉及的认知 模型的复杂性、图像理解存在的困难和计算的复杂 度,针对高分辨率遥感影像 TCR 研究,需构造适应 多层次的场景认知模型,以适应系统功能需求;设 计面向对象的多尺度的识别处理算法,以提升算法 精度;需大幅度提升处理速度,以适应遥感影像大 数据的任务实时性。进一步利用低层的神经计算 机制和高层的认知计算架构,研究适应高分辨率遥 感影像 TCR 问题的媒体神经认知计算(Multi-me- dia Neural and Cognitive Computing,MNCC)模型, 构建并行的 MNCC 模型的遥感影像的 TCR 算法, 具有重要理论意义和应用价值。
(这一部分可以作为写 funding 的材料)
其他
- 在复杂环境中,基于恒虚警率的目标检测方法虚警率过高不利于实时的应用。
- 利用图像分割剔除干扰,是目标检测急需解决的问题,如舰船检测的海陆分割精度低会严重引起漏检(由此可见,图像分割可以作为目标检测的先前环节)
- 在遥感领域,图像分类指的是像元级的地物属性分类,也就是语义分割。不要把图像分类理解成是场景分类。
- 一般而言,一个场景是由多个目标组成,在语义特征上,场景语义要比目标语义复杂。但如果从 场景的粗分类角度,其算法往往比目标分类简单, 故可利用粗粒度的场景分类初步确定目标环境,然后进一步实现目标分类和识别。(场景分类可以看作是目标检测的预处理步骤,或者大范围可能含有目标的 Region Proposal)
- 在复杂背景容易造成目标检测虚警率过高问题,视觉显著性的利用是目标检测重要手段。
- 遥感影像目标识别的核心是建立图像低层特征和高层语义对应关系。几乎所有目标识别算 法都是以自低向上的视觉数据驱动算法,而自顶向下的任务驱动在目标识别所起的重要性不容忽视。
- 中层特征是对低层特征的一种聚集和整合,其本质是利用统计分布建立特征与类别的联系。全局的低层特征往往无法反映局部对象,考虑局部低层特征描述、多局部特征融合及集成学习可提高场景分类的识别率。视觉词袋(Bag of Visual Words,BoVW)模 型的场景分类 ,是目 前广泛采用的中层语义算法。BoVW 模型无需分析场景具体目标组 成,根据场景低层特征统计特性建立视觉单词,然 后利用图像的视觉单词分布来表达图像场景信息[14]。 考虑视词的空间共生关系和上下文关系,将有助于提升场景结构语义的解释。但目前 BoVW 模型的 视词数量设置多少为宜尚无定论,且生成对象也往 往与训练样本有较大相关度,而这是影响算法鲁棒 性的重要因素。(原来对低层特征的加工得到的就是中层特征)
- 红外图像属于目标的热辐射,受红外系统固有特性的影像,红外图像一般存在对比度低、目标边 缘模糊和图像信噪比低等特点。常用灰度特征、分 形特征和 LBP 纹理特征进行目标识别[34]。红外图 像在特征提取前,一般需进行图像增强处理。
- 光学图像具备目标清晰、目标纹理和形状边 缘
- SAR 图像往往包含大量的相干斑噪声,且方 向性强,对于 ROI 存在稀疏性的强散射中心
- 和 SAR 类似,合成孔径声纳(Synthetic Aperture Sonar,SAS) 图像目标识别常用几何特征 进行处理。针对 SAR 和 SAS 图像的对比度低、分辨 率低、噪声和杂波的存在问题
[9] 视觉认知计算模型综述
发表在模式识别与人工智能 2013年第 10 卷。第一作者黄凯奇是大牛,第二作者谭铁牛是院士。
为什么要从视觉认知的角度去研究和设计计算机视觉算法
- 因为人类视觉系统大大超过了当前最优秀的基于统计学习等传统方法的视觉系统
- 大量的数据是非结构化数据,计算机很难理解,而人类认知很容易
什么是视觉认知计算模型?
视觉认知计算模型可称为可计算的视觉认知模型,其目的是在人和计算机之间构建桥梁, 让计算机能完成人类大脑所完成的一些工作
视觉认知计算模型就是通过对人类视觉认知机理的了解,完成视觉机理的数学建模并通过计算机得到实现,从而实现高效、鲁棒的智 能大脑系统
视觉认知的计算模型应满足模拟人类认知特性的要求同时还强调可计算性
关键词是 视觉认知机理 和 数学建模(也就是可计算性)
视觉认知计算、视觉计算理论、计算机视觉
视觉计算理论
视觉计算模型
计算模型
生物视觉机制
视觉计算理论
生物视觉机制新的发现 -> 促进视觉计算理论的发展 -> 产生新的视觉计算模型
计算机视觉:让计算机来模拟人类的视觉机理
机制、理论、模型的 区别?
基于生物视觉机制的视觉认知计算模型
根据视觉信息处理从人眼到人脑这一处理过程把目前的模型大致分为外周脑模型、脑皮层模型及知觉层模型
外周脑模型
外周脑模型主要是模拟视觉信息在视网膜(Retina) 上的运行机理 及 视网膜和皮层之间的信息处理进行建模
视网膜会对亮度、颜色、形状、运动等信息进行初步感知和处理
根据对视网膜机理的研究结果,一些视觉理论 和模型被提出来:
- 基于视网膜中的视杆和视锥细 胞的特性,两种最为常见颜色视觉模型(三刺激模 型和对立色模型) 被提出
- Weber 等 发现,眼睛对光强的响应是非线性的,并且在一定范围内,物体的亮度和背景的差别的比值是相对不变的,这使得视网膜细胞对外界光强具有较好的自适应特性. 根据这一特性,图像的单色对数模型和彩色对数模型被提出来
- 人眼对于对比度敏感而不是对于绝对亮度敏感的特性也被用于建立对比度模型实现对目标的检测
- 19 世纪马赫发现视觉侧抑制效应(Lateral Inhibition),并提出有关视网膜神经 元相互作用原理. 在视觉信号的预处理和传输阶段, 侧抑制原理被认为起着关键性的作用,基于这一原理的模型常被用于图像增强
- Land 在颜色 恒常性基础上提出模拟人类亮度和颜色感知的视觉 模型———Retinex 模型
脑皮层模型
脑皮层是视觉信息处理的中心区域,其主要工 作由视觉皮层( Visual Cortex) 来完成. 人类的视觉皮 层包括初级视皮层(V1)及纹外皮层(V2 ~ V5 等).
- Rodieck 等在 1965 年进一步指 出这不同感受野的直径方向上的截面对光信号的响 应曲线都具有高斯分布的性质,彼此方向相反. 他们 采用两个高斯函数的差来表示这种特性,称为高斯差分模型(Difference of Gaussians, DOG)
- 1980 年 Daugman 使用二维 Gabor 函数模拟视皮层 中细胞感受野的空间性
- Lowe 根据大脑皮层 中下颞叶皮质( Inferior Temporal, IT) 对于视觉刺激 响应的特性,提出一种面向物体识别的旋转和尺度 不变的计算模型( Scale Invariant Feature Transform, SIFT)
- Poggio 等[26] 在 1999 年首次建立完整的视觉处 理模型 HMAX(Hierarchical Model and X), 这是一 个从生物学的角度上模拟的多层次模型.
知觉层模型
视知觉是更为高层的视觉机理的描述,涉及到的现象更为复杂,如错觉现象,图像的二义性等,难 以解释
- 格式塔学派,强调人的视觉系统具有在对 景物中的物体一无所知的情况下从景物的图像中得到相对的聚集( Grouping) 和结构的能力,这种能力被称为感知组织
- Gibson 提出的生态知觉理论,他 试图解决总体的视知觉问题,在这一理论中,Gibson 认为知觉不是对视网膜上降采样图像的解释,而是 通过光学排列和流动直接和真实的体验. 基于这一 理论,光流模型(Optical Flow)被用于提出描述图像 灰度模式的表面运动,即获取运动场. 这一模型因为不需要预先知道场景的信息同时能获取丰富的运动 和结构等信息,使得光流在计算机视觉、图像处理等 得到较多应用
基于视觉计算理论的视觉认知计算模型
视觉计算理论,是从计算机信息处理去描述视觉形成过程。
- Marr 提出了视觉计算理论,从计算理论、计算算法、计算机制三个层次对视觉信息处理任务进行研究和区分,并对视觉任务中的表象描述定义为一个三维重建的过程。(PS:看到这一点,我还是蛮激动的,给了我更多去了解三维重建的动力。)
- 1987 年 Biederman 在 Marr 理论的基础上提出成分识别理论 (Recognition by Component Theory). 该理论认为通过把复杂对象的结构拆分为简单的部件形状,就可进行视觉识别.(启发了 词袋模型)
- 1980 年 Treisman 和 Gelade 等提出特征整合理论( Feature Integration), 认为视觉处理是一个以自下而上的加工为主要特征的、具有局部交互作用的过程(启发了 视觉注意机制模型)
- Chen 等提出另一种和 Marr 视觉计算理论不同的拓扑理论,他们发现对大范围拓扑特征感知早于局部几何特性的感知
好的视觉认知计算模型应具备的能力
- 学习能力
- 自主学习能力,海量的图像、视频数据绝大多数是没有标 签的,大量进行标注也是不太现实的. 从大量的没有 标签的图像数据中自动挖掘知识,无疑有着重要意义
- 长期的增量学习能力(Life-Long Incremental Learning). 在系统 已学习到大量知识的情况下,对新数据能以一种经 济的方式对整个现有模型进行相应的更新,以适应不断变化的外部环境。
- 高容量的表达能力,人脑的记忆容量估计在 1TB ~ 2. 5PB 左右;在现今大数据时代,要有效 的建模海量的视觉数据,模型具有高容量是必不可 少的
- 快速推断能力:人眼能在非常短的时间内完 成人脸的定位、识别. 几乎所有依赖视觉的生物都具 有类似的能力[53] . 视觉认知计算模型在学习到大量 视觉概念、知识之后,也应能对复杂视觉场景进行快 速的目标检测、识别等.
- 多任务信息共享能力. 人类视觉系统在处理视觉任务时,不仅快速而且同时完成多个任务,这表明视觉系统在完成不同任务时具有共享信息的能力,也就是在获取一些共性信息之后,能同时完成多个任务。从系统一体化来讲,希望最终能实现一套类似人类视觉系统的视觉认知计算模型,同时完成检测、分类、识别、分割等多种任务. 在这种情况下,用于分类的关于猫的信息与用于检测的猫的信息共享,无疑是既自然而又经济的.
[10] 光学遥感图像舰船目标检测与识别综述
卫星图像分辨率
- 法 国 SPOT-5 卫星全色图像星下点分辨率为 2.5 米, 重访周期为 1 ∼ 4 天
- 美国 IKONOS 卫星全色图像星下点分辨率为 1 米, 重访周期为 3 天
- 美国 Quickbird 卫星全色图像星下点分辨率为 0.6 米, 重 访周期为 1 ∼ 3.5 天
- 美国 GeoEye-1 卫星全色影像 星下点分辨率为 0.41 米, 重访周期为 2 ∼ 3 天
- 美国 WorldView-2 卫星全色影像星下点分辨率为 0.46 米, 重访周期为 1.1 ∼ 3.7 天
- 美国最先进的军用 间谍卫星已经可以获取0.05米分辨率的高清图像
为什么人工解译不好
面对如此海量的遥感图像数据, 单纯依靠人工目视判读来获取舰船目标信息的传统方式, 由于效率低、主观性强、成本高、信息获取周期长等缺陷, 已远远不能满足现代社会对高效信息的需求. 如何 快速准确地从海量遥感数据中自动提取和识别出舰 船目标已成为当前迫切需要解决的难题.(可以作为 funding 的素材)
为什么有了 SAR 还要研究光学?
SAR 的优点是可全天时、全天候成像
虽然易受光照和云雾等因素影响, 但是光学图像直观易理解, 空间分辨率通常比较高, 在有光照和晴朗天气条件下, 图像内容丰富, 目标结构特征明显, 在海域舰船侦察尤其是舰船识别方面具有 SAR 图像不能比拟的优势, 是 SAR 图像进行海洋目标监 视的重要补充(军事领域讲究可靠性,因为 SAR 全天时、全天候,而光学会受光照和云雾影响,因此注定了 光学只能是 重要补充)
基于光学卫星遥感图像的舰船目标检测与识别的主要特点
- 图像数据量大: 随着卫星数量的增多、重访 周期的缩短、图像分辨率的提高, 遥感图像数据量越 来越大, 数据量每天以 TB 级的速度增长, 且随着新 卫星的升空, 数据量还将会不断增加;
- 图像受天气、光照、海况、成像传感器参数等 多种因素影响: 图像获取时间、天气状况 (晴天、多 云等)、光照、海浪大小、成像视角、图像空间分辨 率, 以及船舶行驶速度、船舶颜色、船舶材料、尾迹 等不同, 舰船目标在光学图像中表现出来的特征也 有所变化;
- 舰船目标为人造刚体目标, 或行驶在海面上, 或停靠在港口码头, 且靠岸舰船通常与码头岸线平行;
- 除航母外, 为了适航, 舰船多呈轴对称结构, 且一般为舰首较尖的狭长形状; 不同的舰船由于其用途不同, 外形结构也相应地有所差异.
现在的舰船检测思路
为了快速准确地提取舰船目标, 目前的舰船检测方法通常采取由粗到精的策略, 首先从大幅图像中快速提取出候选区域, 利用反映舰船目标的最为 明显且计算量小的一些特征, 确定出舰船目标可能存在的区域; 然后再利用精细特征对候选区域进一步确认分析, 去除虚警, 找出真实的舰船目标.
海陆背景
海陆背景下的检测要比纯海洋背景复杂,需要做海陆分离,然后提取离岸舰船和靠岸舰船
发展趋势
1) 基于不同源图像融合的舰船检测识别
利用单一传感器获取目标图像, 在某些方面优 势突出, 但在另一些方面存在劣势, 如,
- SAR 图像中运动舰船形成的尾迹明显且不受天气影响, 但分辨率较低;
- 红外图像中运动舰船呈现较亮的灰度且对云层也有一定的穿透作用, 与 SAR 图像类似, 其图像分辨率也不高;
- 光学图像易受天气影响但分辨率高, 在天气晴朗无云时舰船目标的细节特征丰富.
通过融合不同图像源来检测和识别舰船目标, 充分利用不同数据间的优势互补信息, 并通过多源数据间的冗余信息增强目标检测的可靠性, 不失为 一种有效的途径. 在多种图像源融合利用过程中, 可考虑利用SAR图像全天候、红外图像对运动目标敏感的特性检测舰船, 而利用光学图像分辨率高、目标结构清晰、细节丰富等优点, 对 SAR 图像和红外图 像检测出的舰船目标候选区域进一步确认和鉴别.
2) 多分辨率分析—中低分辨率图像的舰船检测引导高分辨率图像的舰船识别
中低分辨率卫星图像具有覆盖范围广、观测周 期短等优点, 数据量相对较小, 而高分辨率图像中目标清晰细节丰富, 但数据量庞大, 直接从高分辨率图 像中检测目标耗时相当多, 且易受其他目标和复杂 背景的干扰, 因此从中低分辨率遥感图像着手进行舰船检测, 进而引导高分辨率图像的舰船识别, 是实现大范围区域内舰船目标快速普查与舰船目标区域重点详查的有效途径.(这个是系统级的多分辨率,而不是算法级的多分辨率)
3) 视觉注意机制的有效运用
用于表征舰船目标的特征很多, 但不同特征对于舰船目标的显著程度和用于检测识别时所需的运行时间是有差别的. 人类视觉系统在大幅海域背景光学卫星图像中检测识别舰船目标时, 可以将人的注意力快速聚焦于舰船疑似目标, 这一过程对舰船的多种特征进行了不同层次和优先级的利用和综合. 借鉴人类视觉系统检测识别目标的过程, 优先使用区分能力强且耗时短的特征进行粗筛选, 而区分能 力相对较弱但耗时较长的特征用于后续的目标分析中, 实现不同特征的有效综合利用, 既保证舰船检测识别的精度又兼顾到时间效率.(这段话背后的思路还是 由下到上,cascade )
存在问题、难点
1) 舰船目标特征提取与表示
图像分辨率不同, 舰船表现出来的特征也有较大差异. 在中低分辨率光学图像中, 舰船的整体形状特征较为明显, 但不同的舰船其形状特征差异可能很大. 在高分辨率图像中, 舰船的结构细节清晰可见, 然而不同种类和型号的舰船, 其结构特征也是复杂多变[2] .(多分辨率下的特征表示)
舰船检测和识别的任务不同, 需要提取的舰船 特征有所不同. 对于舰船检测而言, 主要是提取可明 显区别于其他类型目标的、舰船所共有的特征, 然而 由于舰船类型多样,其类内特征各异,再加上阴影、 并排停放、码头毗连、周围背景复杂等多种因素, 使 得舰船特征的选取成为非常困难的工作; 对于舰船 识别而言, 则需要提取适于区分不同类型或型号的 舰船特征.(特征的判别性、鲁棒性)
舰船的灰度特征在光学遥感图像中表现出不均 匀的特性, 不仅不同舰船目标可能呈现黑、白截然不 同的极性, 即使在同一舰船目标上, 舰船的不同部位 由于材料、结构等的不同, 其灰度也可能有很大的差 异. 此外, 不同传感器、成像时间、成像视角、光照 变化、气象、海况、舰船运动特性以及舰船并排停靠 等对舰船目标在光学遥感图像中表现出来的特性也 有影响. 因此, 舰船目标特征的选择与稳定提取仍是 舰船目标检测与识别中的难点问题.(如何应对 类内差异、如何应对外界干扰,要对光照、视角等鲁棒)
2) 港口内靠岸舰船检测
对于靠岸舰船而言, 一是舰船与港口区域的灰度、纹理特征没有明显差异, 区分性不好, 且舰船与码头相连, 加上舰船并排停放、阴影与遮挡的干扰, 难以提取到完整的舰船轮廓, 单纯依靠图像分析的方法检测舰船难度很大; 二是靠岸舰船的并排停放、阴影造成的舰船自遮挡、互遮挡、阴影与舰船毗连, 舰船密集排列于码头周围时, 依靠码头先验地理信 息的方法也很难奏效.(看来靠岸舰船检测是很难的一块)
3) 具有高度适应性的舰船检测方法
目前的舰船检测算法往往对于特定图像或特定环境条件可以取得较好的结果. 然而, 实际成像情况复杂多样, 天气状况、气候条件、太阳角度、成像视角、海面状况、高光反射、舰船运动特性等多种因素的影响, 使得光学遥感图像难免存在海浪、舰船尾迹、云雾、阴影等干扰. 研究具有高度适应能力、实用化的舰船提取方法, 是光学遥感图像舰船提取尚需解决的难点问题.
4) 海量遥感图像的舰船目标快速、准确提取
随着卫星的不断升空、图像分辨率的不断提高 和卫星重访周期的不断缩短, 光学卫星遥感图像数 据量越来越庞大, 且相对于幅员辽阔的海域而言, 舰船目标稀疏, 如何从海量的光学遥感图像中快速、准确地检测到舰船目标仍是一项具有挑战性的任务
5) 舰船目标分类识别
自然环境 (天气、气象、海况等)、成像参数 (传感器参数、成像视角)、舰船目标 (运动特性、靠岸、 舰船紧邻) 等多种因素的影响, 往往会导致光学遥感图像中舰船目标存在阴影、遮挡、轮廓不完整、畸变、尾迹等, 而且不同分辨率图像中舰船目标反映出的特征也有差异, 为舰船的分类识别带来很多困难.
[11] 受脑认知和神经科学启发的人工智能
作者是 郑南宁 院士,《网信军民融合》2017 年 11 月刊
无论是深度学习还是其它方法,解决的都是单一问题,而人类大脑是一个多问题求解的结构。(研究受脑认知和神经科学启发的人工智能的动机就和视觉认知计算模型中受生物视觉机制启发的那个一样),希望能够得到从脑认知和神经科学中得到构造健壮的人工智能的启示。
直觉推理、认知推理和因果模型是构建健壮的人工智能必须考虑的基本因素。那么如何来构造一个具体的系统?构造机器人需要三个基本要素:1、对环境中的所有对象进行特征识别,并且进行长期记忆;2、理出对象间的关系,并对它们相互间的作用进行描述;3、基于想象力的行为模型,人在进行具体行动之前,会想象其带来的后果,但机器就需要分析物体之间的各种关系。
这三种要素是让机器像人一样理解物理世界的基础。具有想象力的人工智能,就需要:1、行动之前预想到结果;2、构造一个位置模型;3、给出环境模型,提取有用信息;4、规划想象行为,最大化任务效果。
这就是朱松纯在正本清源那篇文章里面讲得预测动作的结果
深度学习是从机器学习发展来的,要构造一个学习机器,关键是在不同区域、不同任务下,怎么去构造一个成本函数(所以核心是在 cost function 上)
我们要回答出三点:1、大脑是如何实现优化的;2、脑网络的监督训练信号从哪里来;3、在不同的神经功能研究区域中,存在什么样的有效连接的约束和优化。
[12] 联合显著性特征与卷积神经网络的遥感影像舰船检测
2018 年 12 月的 中国图象图形学报
海洋背景下舰船目标检测的关键在于利用舰船 与海洋背景在影像上的差异,从大区域影像中快速 提取疑似舰船目标,然后根据舰船与其他干扰因素 ( 云雾、海浪、小型海岛、陆地等) 的特征进行判断, 去 除 虚 警 ,识 别 出 真 正 的 舰 船。(也就是 粗检测阶段 + 舰船识别阶 段)
本文方法包含舰船粗检测和舰船识别两个主要 阶段( 如图 1 所示) 。粗检测阶段,根据频率域显著性检测(就是 Hou Xiaodi 的频谱残差法,或者 相位谱PFT)能够有效抑制大面积云雾等复杂海面背景干 扰的特点,采用多分辨率显著图融合的方式,对得到 的显著性检测结果再采用对数变换、形态学闭运算 以及图像分割算法提取疑似舰船目标的兴趣区域, 根据先验知识排除部分误检测区域。在舰船识别阶 段,构建少量样本,利用迁移学习的思想训练卷积神 经网络模型,并对所有兴趣区域进行分类判断,最终 实现舰船目标的确认与舰船类型的识别。
多分辨率显著图融合指的是 对同一幅遥感图像,采用缩放成分辨率计算显著图,这是因为
由于图像视觉显著性特征具有尺度相关性,即 图像中视觉显著性特征与图像分辨率及尺度密切相 关,同一物体在不同尺度和范围下具有不同的显著 性特征,在任何尺度下具有不变的显著性特征的物 体是不存在的,不考虑尺度因素的显著性特征是没 有意义的。常规自然图像中目标一般较大,显著性 检测采用图像大小通常为 64 × 64 像素,这一大小符合人眼视觉感知机制,能够取得较好的检测效果
高分辨率下的影像相位谱显著性检测具有抑制云雾干扰的特点,影像分辨率越高,云层抑制效果越好(Comments: 因为在高分辨率下云层很大,是缓变的背景,不突出,也就不是显著目标了),但同时舰船连续性越弱( Comments: 是指舰船会段成离散的显著点吧,这是因为舰船的灰度特征在光学遥感图像中表现出不均 匀的特性, 即使同一舰船目标上, 舰船的不同部位 由于材料、结构等的不同, 其灰度也可能有很大的差 异)。因此为了更好地检测出遥感影像上的海面显著目标,充分利用不同尺度下的显著性检测结果,本文采取多尺度显著特征融合的方式,对不同分辨率的显著图设置不同的权重: 高分辨影像设置较大的权重,这样可以保证显著性检测结果的中心定位在舰船目标位置; 低分辨率影像采用较小的权重,这样可以扩大船体周边的显著范围
得到显著图后要 灰度形态学闭运算( Comments: 和前面的多分辨率融合一样,都是为了船是一个整体 ),还要再做 阈值分割( Comments: 这其实是对 是否是 Proposal 区域的一个 binary Classification)
兴趣区域选取 是 对阈值化的显著图进行八邻域连通区标记,分离所有独立目标区域,计算这些区域的外接矩形
[13] 遥感图像中飞机的改进 YOLOv3 实时检测算法
光电工程 18 年 12 期
更改了 YOLO v3 的网络结构,一是仿照 DenseNet 增加了 Dense 连接,而是 增加了一个较浅 Layer 的 output 为了检测小目标
[14] Attention Networks for Weakly Supervised Object Localization
BMVC 2016,我喜欢看 BMVC 的论文,目前为止读得每一篇都通俗易懂,排版也是我喜欢的方式。
我还是第一次知道 University of Manitoba 这个学校,Manitoba 是加拿大的一个省,在美国明尼苏达北面相邻。
Weakly Supervised Object Localization 我已经很熟悉了,这篇文章是怎么用 Attention Networks 来做的呢?
算法流程如下:
- 先用 edge box 实现 Region Proposal
- 用 attention network 计算每个 Region Proposal 的 Attention score
- 将所有 Region Proposal 的 feature 和 相应的 Attention score 相乘并求和得到 a whole-image feature vector(这是因为 WSL 只有 image-level annotation,所以最终的 loss function 是基于 image-level labels 的)
- 通过 image-level loss function 训练好,在做测试的时候,Attention score 最高的那个 Region 就认为是 Object
其实本质上就是一个根据 Region Attention/Saliency Score 来做目标检测的,只不过这里的 Attention/Saliency 是学来的,而且是 WSL 方式学来的。
因为假设了 the highest attention score 的 Region Proposal 就是 Object,可以看到这个方法只能适用于每张图像只有一个同类目标的情形,这是个缺点。
不管怎么样,这篇文章展示了一个怎么用 Attention 来做目标检测的。
[15] Weakly- and Semi-Supervised Panoptic Segmentation
“Thing” classes are weakly-supervised with bounding boxes, and “stuff” with image-level tags
thing: 有 finite extent makes it possible to annotate tight, well-defined bounding boxes around them
stuff: are amorphous regions of homogeneous or repetitive textures;因为他们有 ambiguous boundaries and no well-defined shape,所以 they are not appropriate to annotate with bounding boxes
Since “stuff” classes are not countable, we assume that all pixels of a stuff category belong to the same, single instance.
many popular instance segmentation algorithms which are based on object detection architectures are not suitable for this task; Instance Segmentation 算法框架依赖于 Object Detection,是合理的,我感觉 Instance Segmentation 就是 Object Detection 后再做个细化处理,Object Detection 的框架肯定是没法处理 stuff 的
在先前 利用 image-level label 的 Semantic Segmentation 方法中,效果最好的方法们用的都是 Saliency Prior。因为图像中的显著部分是 “thing” classes in popular saliency datasets,显然对于 segmenting stuff 类,Saliency prior 是没有帮助的。
Weakly Supervised 的 问题在于 怎么利用 Weak Annotation 来实现我的目的。这就有两个思路的分叉:
- 一个是 Weak Annotation 也是 Accurate Label,只不过是上一个 level 的 Label 例如 image-level Annotation 之于 ,Loss Function 直接建立在上一层 Level 的 Label 上,那么 WSL 的工作就在于怎么用上一个 Level 的 Label 来指导下一层 Level 的工作(这个思路经常被 WSL Object Detection 用,也是 MIL 的范式);
- 另外一条思路是虽然没有下一层 Level 的 Groundtruth,但我可以用 Weak Annotation 猜一个 Groundtruth 出来,后面的工作就在于怎么在迭代中不停提高我猜的 Groundtruth 的准确率(这个思路经常被 WSL Semantic Segmentation 用),这个范式是 Expectation-Maximization (EM) 范式, which alternates between predicting pixel labels and optimizing DCNNs parameters – Highlighted Dec 31, 2018
由此可见,Groundtruth Estimation 的质量对最终结果的影响很大。
本文整体的思路是 在 Semantic Segmentation 的基础上(对 Stuff 的分割已经做好了),利用 Object Detector 的输出作为 cue 来将 Semantic Segmentation 中的 things partitioned into an instance segmentation
用论文中的话来说就是 This network consists of a se- mantic segmentation subnetwork, followed by an instance subnetwork which partitions the initial semantic segmentation into an instance segmentation with the aid of object detections, as shown in Fig. 5.
在 Training 的时候,Object 是有 BBox Annotation 的,可是在 Testing 的时候怎么办?
这篇论文里并没有交代 Object detection 怎么被训练的?我猜是用训练了一个独立的 WSL Object Detection 网络,然后在 Test 的时候被用来给出 Object cue。
[16] Decoupled Spatial Neural Attention for Weakly Supervised Semantic Segmentation
introducing efficient localization cues 极大提高了 WSL Semantic Segmentation 的性能
什么是 localization cues?
weakly supervised semantic segmentation 最成功的 pipeline 是
- first estimate pseudo-annotations for the training images based on localization cues
- then utilize the pseudo-annotations as the ground-truth to train the segmentation DCNNs
显然 the quality of pseudo-annotations 会影响最后分割的性能,本文也是沿用这个 pipeline,并且重点关注 提高 the quality of pseudo-annotations
top-down neural saliency 用来产生 pseudo-annotations for semantic segmentation 的缺点:top-down neural saliency is good at identifying the most discriminative regions of the objects instead of the whole extent of the objects(也就是显著区域不等于整个 Object,很可能只是部分)
本文就是想将 Attention 领域的 the spatial neural attention mechanism 作为 pseudo- annotation generation pipeline
estimate pseudo-annotations 的策略
- Simple-to-Complex (STC) strategy:assume that the pseudo-annotations of simple images (e.g., web images) can be accurately estimated by saliency detection or co-segmentation;Then the segmentation models trained on the simple images are utilized to generate pseudo-annotations for the complex images;The methods in this category usually require a large amount of external data which consequently increase the data and computation load.
- region-mining based methods:rely on region-mining methods to generate discriminative regions as localization seeds;Since such localization seeds mainly sparsely lie in the discriminate parts instead of the whole extent of the objects, which is far from the ground-truth annotation, many works try to alleviate this problem by expanding the localization seeds to the size of objects.(region-mining based methods 是 弱监督语义分割方法里常用的用来产生 pseudo-Annotation 的方法)
To generate high-quality pseudo-annotations, the first category focuses on the quality of training data while the second category focuses on post-processing the localization seeds
用 Spatial Attention 来做 pseudo-annotation 的动机
Spatial neural attention is a mechanism to assign different weights to different feature spatial regions depending on their feature content. It automatically predicts the weighted heat map to enhance the relevant features and block the irrele- vant features during the training process for specific tasks. Intuitively, such weighted heat map could be applied to our purpose of pseudo-annotation generation.
怎么产生针对每个 class 的 Attention map?
就是公式(6)和公式(8),权重是 class-specific 的,出来的 Attention map 自然也是
Expansive Attention map 和 discriminative Attention map
discriminative Attention map 顾名思义,就是 identify discriminative part 的,这也是 WSL Object Detection / semantic segmentation 里面比较常见的,往往没法 Detect 到整个 Object,只能是 discriminative part
之所以叫 Expansive Attention map,我想是因为 只有 discriminative part 扩展 一下才是 Object,所以目的是 identify Object 的才叫做 expansive Attention map 吧
[17] 人工智能时代测绘遥感技术的发展机遇与挑战
武 汉 大 学 学 报 · 信 息 科 学 版,2018 年 12 月
人工智能的6个研究方向:
- 机器视觉 ,包 括 三 维 重 建 、模 式 识 别 、图 像 理 解 等 ;
- 语言理解与交流,包括语音识别、合成,人机对话交 流,机器翻译等;
- 机器人学,包括机械、控制、设 计 、运 动 规 划 、任 务 规 划 等 ;
- 认知与推理 ,包 含 各 种物理和社会常识的认知与推理;
- 博弈与伦理, 包 括 多 代 理 人 (agents)的 交 互 、对 抗 与 合 作 ,机 器 人与社会融合等;
- 机器学习,包括各种统计的建 模、分析工具和计算方法等。
认知与推理是智能体需要具备的基本能力,它可以是简单的认知与推理,也可以是复杂的高级的认知与推理,认知与推理过程可以是计算机算法驱动,也可以是已有 规则或者知识的直接驱动
机器学习是一个增加 智能体知识、提高智能体认知与推理水平的过程
博弈与伦理则是更高级的智能,它不仅涉及到智 能体与智能体之间的协同,还涉及到人与智能体 之间的协同与融合。
遥感与计算机视觉的关系:
测绘遥感是一个 与人工智能密切相关的学科领域。摄影测量与遥 感和机器视觉有许多概念、原理、理论、方法与技 术上的重叠,它们都是用来感知环境的技术;其区别是摄影测量与遥感主要是感知地球和自然环境,而机器视觉主要是感知智能体关注的目标和环境,但是它们在数学和物理上的原理基本相同。
机器视觉或者称计算机视觉,是一门研究用 摄影机和电脑代替人眼对目标进行识别、跟踪和 测量等的学科。
广义上,计算机视觉包括图像处 理、目标重建与识别、景物分析、图像理解等内容。
狭义上,计算机视觉通常是通过对采集的图片或视频进行处理以获得相应场景的三维信息,即三维重建。
Marr 认识到复杂的神经和心理过程可用直接的数学计算表达,并提出三维重建的计算视觉理论。他在1982年发表的《视觉:从计算的视角研究人的视觉信息表达与处理》[2 ] 中 详 细 分 析 了 二 维 图 像的表达 、立体图像的对应和重建、算法以及硬件的实现,是计算机视觉的开山之作(这个过程的表达方式可以是通过模拟生物视觉机制用数学公式表达生物机制,也可以直接用数学推导得到,比如 3D 重建里的很多算法就是通过数学推理、而非通过模拟生物机制)
与计算机视觉相似,摄影测量学是一门利用光学像片研究被摄物体的形状、位置、大小、特性 及相互位置关系的学科,简而言之,摄影测量学是 以摄影为工具,以测量为目的。
仅几何而言,两门学科具有同样的理论基础,即小孔成像和双目视觉原理。
但在应用和技术细节上,两者存在区别。如数字摄影测量主要用于相对静态的地形地物测绘,使用航空和航天平台,所用的相机通常为专业量测相机;而计算机视觉主要以普通相机、手动和车载移动平台为主,用于运动目标的实时重建与识别,应用领域包括人脸识别、机器人和无人驾驶车等大众应用领域。
在技术方法上,如相机检校, 摄影测量一般布设有高精度三维检校场,而计算 机视觉常采用二维平面棋盘。在空中三角测量方 面,摄影测量一般用严密的光束法区域网平差,而 在计算机视觉中一般称为从运动恢复结构 (structure from motion,SfM )[8],除 了 用 全 局 的 光束法平差,也采用一些非全局解法,如增量式的 局 部 平 差 、滤 波 [9 ] 等 ;这 些 差 异 源 于 摄 影 测 量 需 要 更高的测量精度
摄影测量的两个主要任务是目标几何定位和属性的提取,包括从二维像片重建三维几何以及 地物要素分类。
对于三维重建中的关键技术———密集匹配,深度学习已经取 得很好的应用效果。如在KITTI等标准数据 集 [18 ] 上 ,前 10 名 的 方 法 都 是 深 度 学 习 方 法 (我会用到密集匹配吗?用到的话,也应该考虑用深度学习方法)
摄影测量从静态走向动态 与实时,并将与计算机视觉深度融合(最近大牛们开始做视频遥感)
[18] 光学遥感影像智能化处理研究进展
光学遥感影像具有“三高”的特点:
- 高 空间分辨率,如QuickBird,IKONOS,中国高分 系列遥感卫星;
- 高光谱分辨率,如Hyperion, A VIRIS,HYDICE,和ROSIS;
- 高时间分辨 率,如MODIS(Web,2016)。
传 统的遥感影像处理方法难以满足对遥感影像处理 质量、效率的要求,具体体现在
依赖数据的先验分布,算法缺乏自组织、 自学习能力。在监督的遥感影像处理方法中(如基 于wrapper的特征选择方法,监督分类法),遥感影 像处理结果的优劣受限于遥感数据的先验分布假设。如果遥感数据的分布满足算法的假设条件, 则能够取得满意的遥感影像处理结果。但由于现 实中遥感数据的复杂特性,特定的数据分布类型 往往难以满足,因此,该类算法不具有很好的泛 化能力,缺乏对数据的鲁棒性。(这点的确是这样,深有感触)
为什么要做波段选择?高光谱遥感影像的每个像素可以表示一个高 维向量,由于波段间的高度相关性,高光谱数据 存在大量的数据冗余。因此,选择具有可分性的波段子集是高光谱遥感影像数据预处理的一项重 要步骤,能够极大提高高光谱遥感影像的分类精 度。
高光谱遥感影像混合像元分解的目的是提取组成混合像元的成分(端元提取),及他们各自所占的比例(丰度反演)。
[19] 从摄影测量到计算机视觉
摄影测量的 4 大板块:
- 理论基础:光学成像的物理法则是小孔成像,对应的几何原理是透视变换
- 成像设备
- 载体:狭义上的摄 影测量一般指航空摄影测量成熟的飞行平台是 重要的组成部分
- 测量法和测量工具
计算机视觉可简单概括为“用计算机代替人眼,从图片中重建和解译世界”
1972年,第一颗 Landsat卫星 升空,标志着遥感学科的建立。
在摄影测量已经解 决大部分几何问题的前提下,遥感的工作重点就集 中 在 “解 译 ”上 。 解 译 是 回 答 “是 什 么 ”和 “为 什 么 ” 的 问 题
在语义上,摄影测量中的研究内容就是采用智能方法为各行业提供专题图。摄影测量的应用 特性使得它并不关心诸如特征描述、上下文关系 等 中 间 结 果 。 这 种 端 到 端 的 模 式 (end-to-end)特 别适用深度学习方法。目前,深度学习已经被广 泛用于遥感图像的分类、识别、检索和提取。与在 几何方面的欠佳表现不同,在语义上基本全面碾 压了传统的方法。
深 度 学 习 是 “表 示 学 习 (representation learning)”[16]的 一 种 。 表 示 学 习 的 最 大 特 点 是 不 需要设计人工特征。它指计算机根据一套通用规 则自动地学习出从输入到输出的最优特征表示的 方法。
其他
1. Difference between target and object
根据 Target vs Object - What’s the difference?,target 有两个跟武器有关的解释,一个是作为 Noun 的 A kind of small shield or buckler, used as a defensive weapon in war,另一个是作为 Verb 的 To aim something, especially a weapon, at (a target)。而 Object 则是指 A thing that has physical existence。
从上面可以看出,在中文语境中 target 和 Object 虽然都翻译成了 目标,但 target 指军事领域的目标,而 Object 则通常指普世、通用的目标。
2. 将夜
小人物的生存和奋斗,人设里主人公始终就是将军府门房的儿子,而不是将军的儿子。
从各个被主角干翻的角色来看,即使身居高位也应该平等待人,谦虚待人,而不该轻慢、骄傲、嗔怒,如果这里面还夹杂着自私、贪婪和怀疑那就更加丑陋了。
3. 辨识 和 识别的区别
辨识 的英文是 identification,识别的英文是 recognition。
identification 是 A particular instance of identifying something.
识别则是 an awareness that something observed has been observed before。
这个可能有点含糊,具体的例子是 The identification of a sound is specific to a unique event while the recognition refers to a class of events.
Object identification in object models means that every object instance has a unique, unchanging identity. Object identification is often referred to as an OID.
也就是说一个是 instance level,而且这个 instance 要有一个唯一的 identity,一个是 class level。
检测 是 检测到 车辆;辨识 是区分 是 坦克 还是 面包车? 识别是看 什么型号的坦克?
To Do List
Multiple object recognition with visual attention
Recurrent Models of Visual Attention
Look and Think Twice: Capturing Top-Down Visual Attention with Feedback Convolutional Neural Networks
ICCV 2015
Spatial Transformer Network
adaptively generates hyper-parameters of affine transformations using input feature so that target area feature maps are well aligned finally
可以看做是 a hard attention upon the feature maps
Deformable Convolutional Network
deformable convolution where pooling offsets are dynamically generated from input features, so that only the relevant features are pooled for convolutions
Weakly Supervised Local Attention Network for Fine-Grained Visual Classification
Fine-Grained Visual Classification (FGVC) 的难点:
- High intra-class variances. Objects that belong to the same category usually present significantly different poses and viewpoints;
- Low inter-class variances. Objects that belong to different categories may be very similar apart from some minor differences, e.g. color style of a bird’s head can usually determine its category;
- Expensive human annotation results in limited training data. Labeling fine-grained categories require specialized knowledge and a large amount of annotation time.
为什么要关注 local?
In fine-grained visual classification task, objects usually share similar geometric structure but present different part distribution and variant local features. Therefore, localizing and extracting discriminative local features play a crucial role in obtaining accurate performance.
To distinguish fine-grained categories that have very similar features, we must focus on the feature representation of the local parts. Therefore, the key process is locating discriminative object parts.
为什么叫 weakly supervised?
FGVC 分为两类,一类用 image-level annotation,另一类用 location-level annotation。只用 image-level annotation 自然就是 WSL。
Holistic, Instance-level Human Parsing
又是我喜闻乐见的 BMVC, 2017,Weakly- and Semi-Supervised Panoptic Segmentation 作者 李淇竹 的前一篇 Paper,是 Philip Torr 的博士生。
Object parsing 的概念是 the segmentation of an object into semantic parts,可以看到 Object parsing 和 Semantic Segmentation 不一样,Semantic Segmentation 是会对所有像素做 label,而Object Parsing 只会去 label Object(Background 不管什么都会被 label 成 Background 这一类,而不是 天空、道路 这些不同的类),对于 Object,会将其分为不同的 parts。
本文是 segments human parts at an instance level,注意是 human part
如果您觉得我的文章对您有所帮助,不妨小额捐助一下,您的鼓励是我长期坚持的一大动力。
 |
 |
|---|---|