Single-Shot Object Detection with Enriched Semantics
CVPR 2018 的文章。
Motivation
这篇文章的 Motivation 是 SSD 算法对小目标的检测只是利用了浅层的特征,缺少高层语义,如果能让浅层特征能够有更多的语义,就可以改善小目标检测的性能。这篇文章给出了一种做 Semantic Enrichment 的方式。
语义可以简单地看做是数据所对应的现实世界中的事物所代表的概念的含义,以及这些含义之间的关系,是数据在某个领域上的解释和逻辑表示。
这个 Semantic Enrichment 是通过把一个高层语义分割任务最后的 Feature Map 作为 Attention 权重加到 Detection 的 低层特征上去,这种 Semantic Enrichment 具体的操作方式就是 spatial attention mechanism,通过 element-wise multiplication 上 Spatial Attention Weight Map,直接对最底层的 Detection Layer 的 Feature Map(conv4_3)来 suppress or emphasize 用于检测的低层 feature maps。Semantic Enrichment 具体的表现,用 BAM 论文的话来说则是:denoises low-level features such as background texture features at the early stage;focuses on the exact target which is a high-level semantic (Spatial 维度上).
问题在于这个 Attention Map 怎么来的?作者是通过一个 Semantic Segmentation 分支得到的,只不过这里的标注有点粗略,就是把 BBox 里面的所有像素都标注成了那个 BBox 对应的 label。
下图把这种通过 weighted 上 Attention Map 来提高特征语义的思路展示得很清楚,A 是原图;B 应该是低层的 Detection Layer 对应的低层特征,上下两行分别对应的是 狗 对应类别的特征图 和 人 对应类别的特征图,可以看到不管是狗还是人的特征图上,都有大量无关的特征显著存在;C 是两者对应的由 Semantic Segmentation 得来的 Attention weight map;D 就是 B 和 C 做了 element-wise multiplication 之后的结果,可以看到对于每一类的无关特征都被压制的干净了。

Model
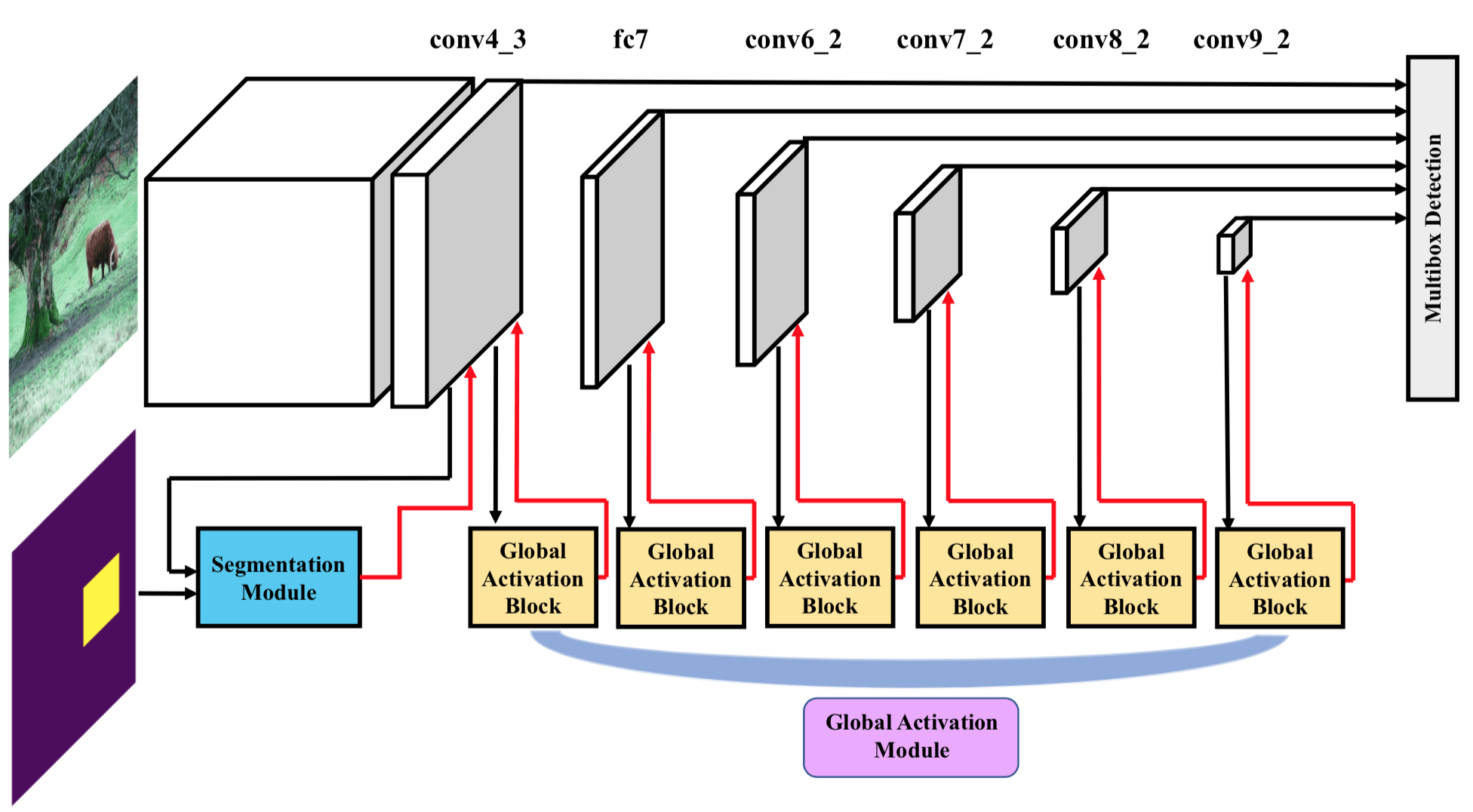
文章的整个网络架构如下图所示,由 Detection Module、Segmentation Module 和 Global Activation Module 三部分组成。其实 Detection Module 就是 SSD,Segmentation Module 就是 FCN(用 dilated convolution 的,为了保持大小不变),Global Activation Module 就是 Squeeze-and-Excitation Block。
使用 SE Block 的目的是不仅仅要在 Spatial 维度上 提升有用的特征并抑制对当前任务用处不大的特征,在 Channel 维度上也这么做。因此这篇论文和 BAM 和 CBAM 一样都是同时做了 Spatial 和 Channel Attention 的文章。文章中的说法是用于提高 high level 的 feature map 的语义信息,我理解的提高 feature map 的语义信息的方式还是通过 attention weight 抑制干扰特征来实现的。 SE Block 的思想是在 Channel 维度上解耦,让某些 channel 就对应某些 image class;这篇文章的思想也是如此,只不过是 channel 对应某些 object class。这篇文章里的 SE Block 也就是 global activate module 的作用是学习 channel 和 object class 的关系,以提高效果。
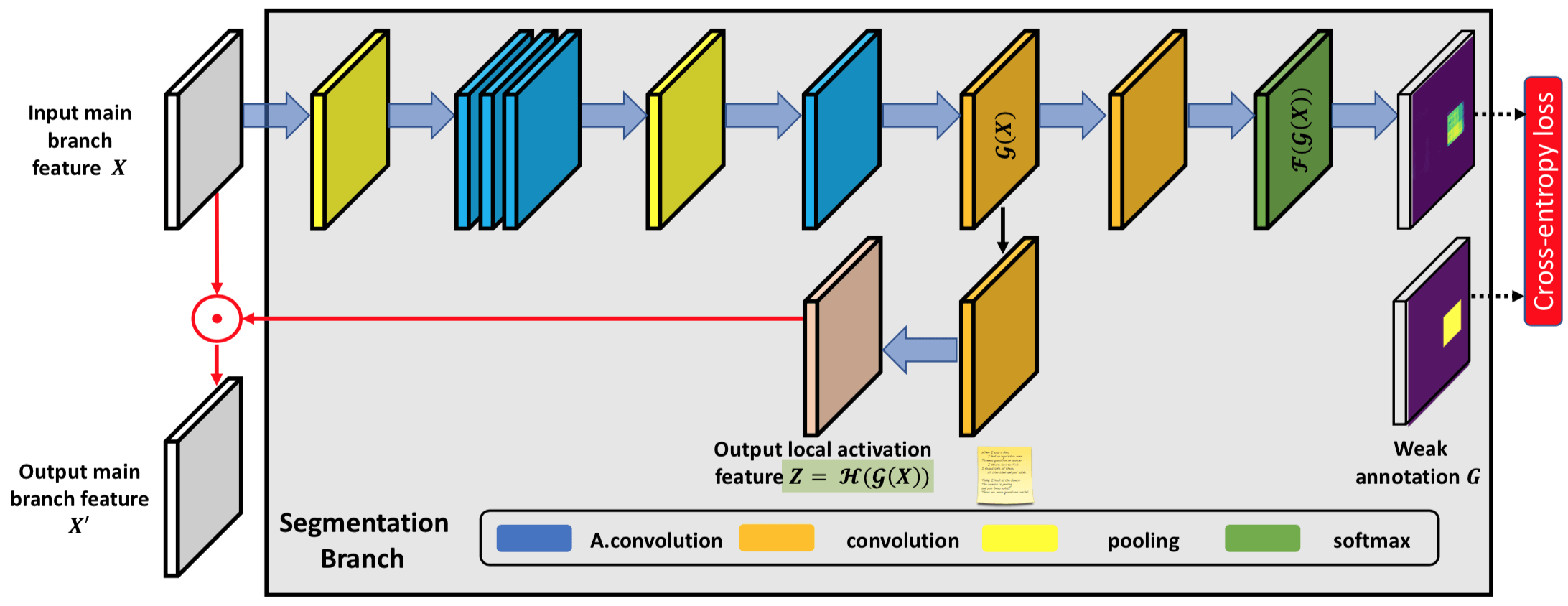
Segmentation branch
需要一提的是,在这篇文章的 Semantic Branch 的 Output 有两个, 这是因为一个 Output 通道数是要等于类别数,这是为了计算 Loss;还有另外一个 Output 是为了生成 Attention Weight,通道数必须和 Detection Branch 的 Feature Maps 通道数一样。
Loss
Loss 就是正常的 Object Detection 和 Semantic Segmentation 的 loss 之和,只不过 Semantic Segmentation 里的 Groundtruth Truth 就是 BBox 的范围,但是计算还是和一般的 Semantic Segmentation 是一样的。
如果您觉得我的文章对您有所帮助,不妨小额捐助一下,您的鼓励是我长期坚持的一大动力。
 |
 |
|---|---|