Residual Attention Network for Image Classification
CVPR 2017 的文章,是比较早的一篇 Soft Attention 的工作。
Motivation
窃以为这篇文章的动机在于 bring more discriminative feature representation by the attention mechanism,具体地说是通过在 feedforward network structure 中 incorporates the soft attention 来 generate attention-aware features。这些 attention-aware features 质量更好,更有利于分类,因为这些特征 enhances different representations of objects at that location。为了实现这个目的,文章中给出了 Attention Module 的方式。但之间堆叠这些 Attention Module 会产生梯度消失问题,网络不能很深。为了解决这个问题,类似于 Residual Block,文章给出了一种 Attention Residual Learning 方式。因此,本文所提出的 Residual Attention Network 其实就是 Attention Module + Attention Residual Learning。
Model
Residual Attention Network = Attention Module + Attention Residual Learning
这篇文章的 Residual Attention Network 的架构如下
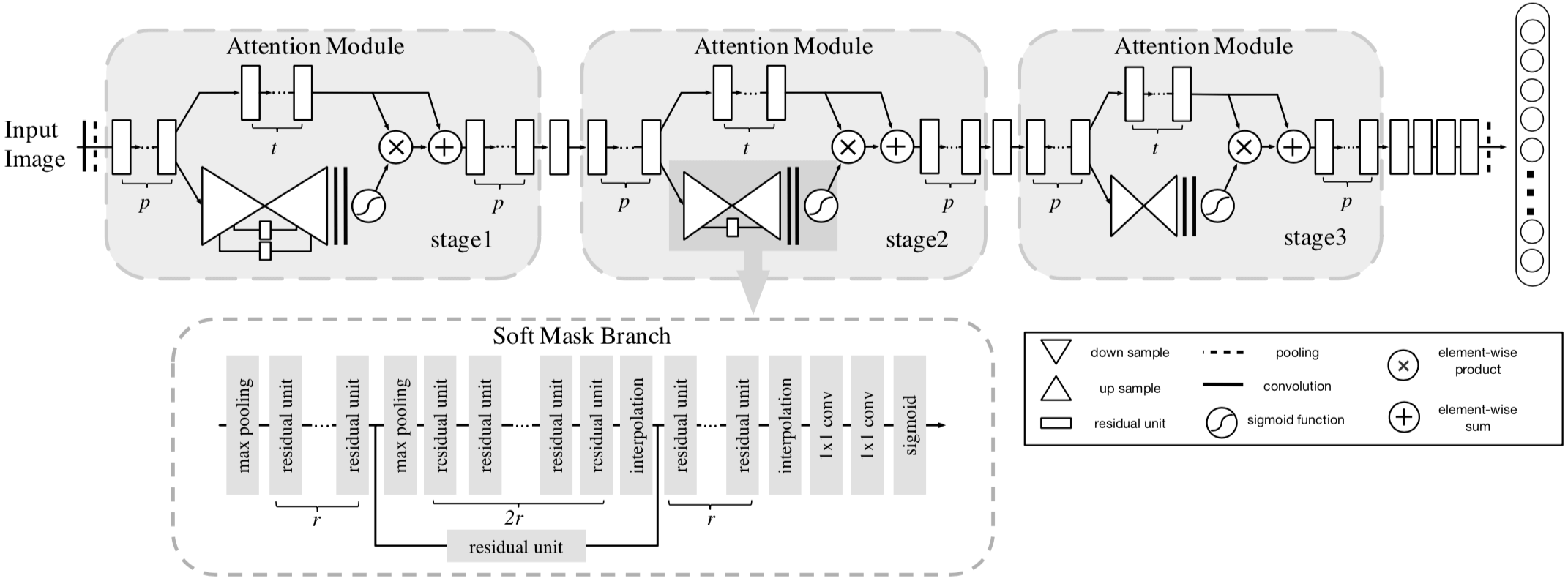
Attention Module
Soft Attention 的方式就是学出一个权重分布,再拿这个权重分布施加在相应的特征之上。在目前我看过的 Attention 的论文里,比如 SENet、BAM、CBAM、DES,这个相应的特征就是计算 Attention 权重的输入。这是因为在 SENet 中,Attention Module 只是一个主要特征抽取模块之外 add-on 的模块,起到的作用是改进已经由主要模块抽取的特征的质量;而在本文中,本文的 Attention Module 是要成为像 Residual Block 那样的基础性模块,是用来抽取特征的,只不过抽取的是 attention-aware features 质量更好。因此,本文的 Attention Module = trunk branch + mask branch。 其中,trunk branch 负责往常的特征抽取,可以是 pre-activation Residual Unit, ResNeXt and Inception 中的任一种 state-of-the-art network structure。至于 Soft Mask Branch,如下图所示,是一个 hourglass 结构,encoder-decoder 结构。
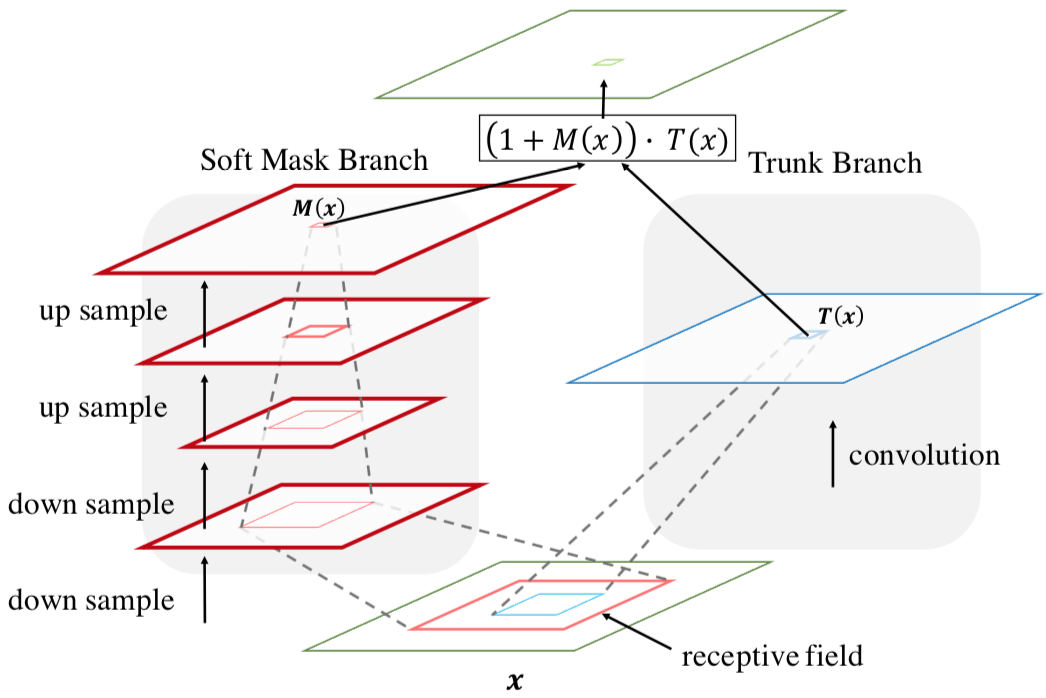
Fig. 2 感觉有点怪,文章并没有提到它。但要注意的是,mask branch 和 trunk branch 的 receptive field 是不同的,至于为何不同,作者也没有讲。
Attention Residual Learning
在给定 trunk branch output $T(x)$ 和 mask branch output $M(x)$,通常按照一般的 Soft Attention 的方式,Attention Module $H$ 的输出会是
$$
H { i , c } ( x ) = M { i , c } ( x ) * T _ { i , c } ( x )
$$
$M(x)$ 的作用是 feature selectors,用来 enhance good features and suppress noises from trunk features. 然而,由于 mask 里的权重位于 0-1 之间,多个 Attention Module 堆叠后(网络变深),梯度就会消失,而网络深度加深是获取最后好性能的一大关键。文章给出了一种 attention residual learning 方式来解决这个问题,也就是把 Attention Module $H$ 的输出变成
$$
H _ { i , c } ( x ) = \left( 1 + M ( x ) \right) \cdot T ( x )
$$
注意,此 Residual 非彼 Residual。在 ResNet 中,Residual Learning 是 $H { i , c } ( x ) = x + F { i , c } ( x )$ 这样的。在同样 Soft Attention 的 BAM 和 CBAM 中也采用了 Residual Learning,但它们的 Residual 也是 ResNet 方式的标准的 Residual Learning 的方式,与本文不同。
Spatial Attention and Channel Attention
Attention 说白了就是一个 0 到 1 的权重,最后只要每个点的数值都在 0-1 之内就行,那这个权重具体怎么算出来呢?这就是公式(4)、(5)、(6)了。这三个公式分别对应着,是既对 Spatial 又对 Channel 做 Attention,还是只对 Channel 施加 Attention,后者只对对 Spatial 施加 Attention。
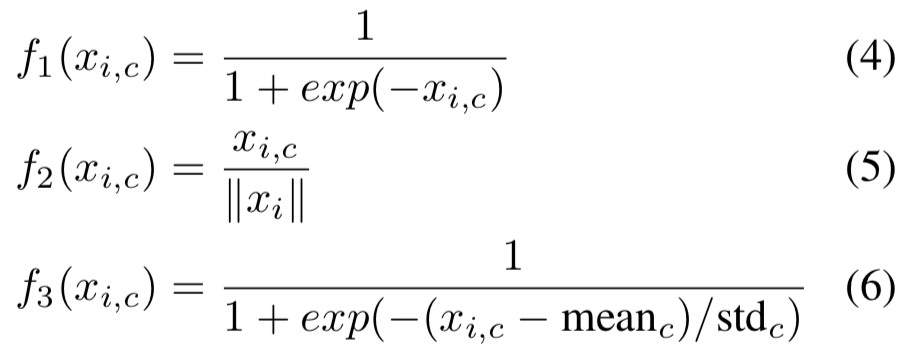
这里有个概念要澄清一下。虽然都叫 Channel Attention,之前在 SENet、BAM、CBAM 中,我们说 Channel Attention 是 Channel-wise Attention,不同 Channel 不同,但同一个 Channel 内的所有 Spatial Position 都是同一个权重;因为做了 Global Average Pooling,这里整个特征的 Channel Attention Weight 是一个 Channel 数的向量。在这篇文章里的 Channel Attention 是说计算某个点(each spatial and channel position )的时候,计算出来的权值仅与该点同个 Channel 上的其他点有关,与 Spatial 点无关;这里整个特征的 Channel Attention Weight 仍然是跟特征向量相同大小的张量,因为没有像 SENet 那样做 Global Average Pooling。
概括一下,在 SENet、BAM、CBAM 中的 Channel Attention 是只有 Channel 维度不一样,Spatial 维度所有点的权重都一样;而本文的 Channel Attention 是只在计算权重也就是归一化的时候考虑了 Channel 维度上的点,而没有考虑 Spatial 权重上的点,因此不同 Spatial 上点的权重还是不同的,因为他们各自 Channel 维度上的向量不同。
例如,公式(5)performs L2 normalization within all channels for each spatial position to remove spatial information. 这个的确是 remove spatial information 了,因为得到的权重只与一个 spatial position 上的所有点之间的相互大小有关,与其他 Spatial Point 无关;但需要一提的是,公式(5)的 channel Attention 得到的还是一个 $H \times W \times C$ 的张量。
最后的效果是 mixed attention,也就是既对 Spatial 又对 Channel 做 Attention 效果最好。这与我们的直觉也是相符的。
Loss
这篇文章没有专门讲 Loss,但既然是分类,一般就是 cross entropy loss 吧。
如果您觉得我的文章对您有所帮助,不妨小额捐助一下,您的鼓励是我长期坚持的动力。
 |
 |
|---|---|