论文
[1] 时空异常探测方法研究综述
什么是异常
异常探测旨在从海量数据中挖掘不符合普适性规律、表现出“与众不同”特性的数据或模式
“异 常 ”亦 称 为 离 群 点 、孤 立 点(所以说 abnormal 和 outlier 是一回事)
- 1980 年 ,Hawkins给出异常的本质性定义,即“严重偏离其他对象 的观测数据,以至于令人怀疑它是由不同机制产生 的 ”
- 1994 年 ,Barnet t 等 进 一 步 从 统 计 学 的 角 度 给出“异常是指与数据集中其余数据分布不一致的观测数据或观测数据子集”
- 2003 年 ,Shekhar 等[6]考虑到空间数据的特性,将传统异常在空间数据中进行了扩展,并将空间异常定义为“专题属性与 其邻近空间实体显著不同,而在整体数据范围内差 异 可 能 不 明 显 的 空 间 实 体 ”
- 2006 年 ,Cheng 等 在 空 间异常的基础上,从空间域进一步扩展到时空域,给 出时空异常的定义,即“专题属性值严重偏离其时间 或(和)空间邻近域内参考实体的时空实体”
现有方法的局限性:
- 现有异常探测方法普遍不适用于高维数据的异常探测;
- 很多方法需要先验知识的指导,自适应能力差;
- 缺乏对异常探测结果的有效性评价。
时空异常探测的具体例子:在 气象方面,预测台风路径突然变化的原因对提前发 出疏散指令起到至关重要的作用;预测某个地区不 寻常的降水行为将有助于对突如其来的洪涝灾害等 极端事件做好充分准备
时空点事件中的异常主要包括离群和热点两类。其中,时空离群指那些不属于任何时空簇的孤 立点事件以及仅包含少量时空点事件的小簇;时空热点指那些局部聚集程度显著偏大的簇
传统异常探测方法
- 基于统计的方法。该方法的基本思想是根 据数据集的特性先假定一个数据分布的概率模型, 然后根据模型的不一致性确定异常。该 类方法的优点是建立在成熟的统计学理论基础上, 异常含义明确;其缺陷是数据集的概率模型一般未 知,估计时难免出现误差甚至背离现实的错误。
- 基于距离的方法。该方法的基本思想是以 对象间距离的大小检测异常,将那些没有足够邻居的对象识别为异常。
- 基于密度的方法。为了探测数据集中的局 部 异 常 实 体 ,Breunig 等 [14 ] 在 基 于 距 离 探 测 方 法 的 基础上引入局部密度的概念,提出一种基于密度的 探测方法———LOF算法(图2a)。借助实体的局部可达密度定义局部异常度,异常度与局部密度成反比,将异常度较大的实体识别为异常。
- 基于角度的方法。该方法通过度量实体与其邻域内其 他实体所构成的角度定义异常度,角度越大,异常度 越 小 , 反 之 异 常 度 越 大;然而,当数据呈线性分布时,基于角度的方法难以准 确探测异常
- 基于聚类的方法。该方法的基本思想是将 异常探测过程转换成聚类过程。聚类的目的在于将 数据集划分为若干簇,并且簇内实体间距离尽可能 小,簇间实体间距离尽可能大,将聚类后那些不隶属于任何簇的实体识别为异常
[2] 弱监督深层神经网络遥感图像目标检测模型
中国科学: 信息科学 2018年
使用全卷积网络提取遥感图像中可能存在待检测目标的候选区域(用 FCN 来做 Region Proposal,说是避免了对图像 的穷举搜索,但感觉很怪,因为 Semantic Segmentation 需要 pixel-wise 的 Annotation,其实是比 BBox 更高的要求,感觉有点倒置,但这里的 Semantic Segmentation 也是用 WSL 的,从而避免了 Annotation 比 Detection 更高这一点)
FCN模型负责把待检测图像转化为粗分割图像,可能含有飞机的区域在粗分割图像中 会被高亮标记. 然后使用滑动窗口方法在标记区域提取出候选区域. CNN 模型用于对所有候选区域进 行特征提取和分类. 分类的输出是二值的, 即是否是含有整个目标的区域.
用图像级标签替换像素级标签完成 FCN 模型的训练
怎么用 WSL 来做 语义分割?
在进行训练时, 把飞机样本图像中的所有像素点的标签置为 1, 把背景样本图像中 的所有像素点的标签置为 0, 即获得 FCN 模型需要的像素级标签. 也就是在获取 FCN 训练样本时, 既不用把表示飞机的像素区别开来, 也不需要使用矩形框定位飞机的位置, 只需要按照图像的内容为 所有像素打上统一标签即可.
使用FCN模型和滑动窗口方法来实现候选区域的提取
待检测图像输入训练好的 FCN 模型 后, 得到的是一幅粗分割图, 其中可能包含飞机的区域被置为 1, 可能是背景的区域被置为 0. 这种类似于显著性检测的机制为目标区域的选取提供了先验信息, 可以避免在原图像中的穷尽搜索.(但是还是要在 粗分割的目标区域内 穷尽搜索吗?)
怎么确定候选区域?
在粗分割结果图上使用滑动窗口进行候选区域的选取. 滑窗的大小固定为 60, 步长为 15, 区域选 取的阈值为 0.65, 即只有一个窗口中 65% 以上的像素点的值都为 1 时该窗口才能被确定为是候选区 域。(这些参数是实验调出来的,其实就是 穷尽搜索)
在 WS-DNN 模型中, CNN 模型的作用是实现对候选区域的特征提取和分类, 即判定候选区域中 是否含有飞机 (含飞机为 1, 背景为 0).
Tamura 等[43]则从人类对纹理的视觉感知心理学角度,提出了度量纹理的 6 种属性:粗糙度(coarseness)、对比度(contrast)、方向度(directionality)、 线 像度(linelikeness)、规整度(regularity)和粗略度(roughness)等
[3] 人工智能的回顾与展望
来自 “双清论坛”专题:人工智能基础理论及应用
我理解的人工智能就是 理解人类认知并建立可计算认知模型
从对大脑观测理解中,抽取对人工智能有启 发性的内容,为脑启发计算或生物计算带来启示,是 目前脑科学与人工智能交叉一个活跃方向(也就是说建立的可计算认知模型是在模仿大脑工作原理的基础上)
深度学习
深度学习的基本动机
与 依赖于人工经验、通过手工构建的特征不同,深度学习一般从标注数据出发,通过误差后向传播进行参 数调整以实现端到端的区别性特征学习。深度学习的基本动机在于构建多层网络来学习隐含在数据内部的模式,从而从数据中可直接学习更具区别力、更泛化的特征而非手工定义。
深度学习的不足
深度学习依赖于标注数据,缺乏逻辑推理和对因果关系的表达能力,很难处理具有复杂时空关联性的任务
这一犹如“黑盒子”式的学习模型存在过 度依赖于标注数据,难以有效利用逻辑、先验和知识 等信息,适应环境变化能力不足、在对抗环境下易于 被攻击、结果可解释差等不足。
为了弥补上述不足, 一些研究开始重视在深度学习过程中引入先验知识或更加重视中间特征层,以建立更具解释性的深度学习模型。
类脑计算
人类大脑具有感知、识别、学习、联想、记忆和 推理等功能,并非全部用符号计算形式来实现。
至今我们对人类认知功能如何从 复杂动态(时空演变)的大脑神经结构中产生,依然
没有形成较为完整的认识。
类脑计算最根本挑战是人类大脑信息处理和认知功能深刻的复杂性。
深度学习中引入记忆机制
神经记忆的特征主要表现在 如下四个方面:
- 分布式表达和存储
- 输入信息与被检索记忆信息在内容上具有关联性
- 对记忆信息的存储和检索具有动态性
- 记忆与信息处理过程紧密结合
如何在深度学习模型中引入注意力机制和外在记忆体结构,从而更高效挖掘数据中感兴趣信息和利用外来信息,是当前人工智能研究的热点。
这一方面代表性工作是在针对序列数据学习的循环神经网络(Recurrent Neural Network,RNN)中引入“短时记忆”,如LSTM和GRU等模型。其思路在于当前时刻状态的输出会受到过往若干时刻状态的影响,这样学习模型具备了“注意力”机制。注意力模型在机器翻译、语音识别和图文生成等领域取得了成功,这一学习输入序列数据和输出序列数据之中若干单元之间相互影响的注意力机制也被称为“内在记忆”。
在端到端深度学习中引入注意力机制和外在记忆体结构,可有效利用当前输入数据数据之外的数据和知识,克服了仅依赖于输入数据进行驱动学习的不足,在零样本学习等方面表现出一定的优势。
智能制造
如何学习处理不完备小样本数据中所包含碎片化隐性知识,以解决难以表征生产情境、难以计算生产、控制 和决策中复杂信息的关键技术问题
重点资助方向
- 脑启发的视觉处理计算架构。借鉴视觉通道特别是视网膜的信息处理能力,以及大脑神经连接的网络化结构,设计和研究新型的视觉计算模型和处理架构。这种架构的组成单元包括从帧驱动到事件驱动的信息获取单元(智能计算前移)、注意力选择/事件驱动的信息获取方式、时空动态的信息编码、网络化分布式的动态信息处理、结合长时和短时记忆功能的网络结构,以及条件要素的约束和引导的有效控制。实现大脑结构网络、功能网络和有效 网络在视觉处理架构不同层次的映射。
- 复杂场景自动理解。研究从属性、物体到场景的跨层次关系发现与相应视觉知识的表示和推理方法;研究对场景的层次化识别及与之相关的类别与属性自动发现方法; 研究具有触类旁通能力的识别与学习方法;建立视觉对象的时空特征与语言表达之间的对齐,进而和计算语言学相结合,实现从感知到认知的无缝转换。
显然,我学习的方向应该是 复杂场景自动理解。
什么是双清论坛?
“双清论坛” 是国家自然科学基金委员会为推动创新文化建设、营造良好创新环境而举办的学术性研讨会。旨在立足于科学基金资助工作,集中研讨科学前沿或国家发展战略需求的深层次科学问题、学科交叉与综合的重大基础科学问题、发展与完善科学基金制的重大政策与管理问题。定名为 “双清论坛”,一是因为国家自然科学基金委地处双清路;二是,“双” 的含义是指 “科学与民主”,“清” 的含义是 “正本清源”,即通过倡导科学的精神,弘扬民主的作风,汇聚专家学者的智慧,从而为科学基金资助与管理政策提供决策依据。
因为基金委在双清路,基金委办的论坛就叫双清论坛了。
[4] 人工智能中的推理:进展与挑战
什么是推理?
推理是进行思维模拟的基本形式之一,是从一个或几个已知的判断(前提)推出新判断(结论)的过程。
推理是从一般到个别、一般到一般、个别到一般、个别到个别的过程。
一般可将推理分为:
- 演绎(deductive)推理
- 归纳(inductive)推理
- 类比(analogy)推理
- 假设性(presumptive或abduction)推理
- 因果(causality)推理
- 综合(synthesis)推理
推理起源于人类尝试拥有从个别、具体事物中抽象概括出一般、普遍道理的思考能力,如亚里士多德提出和建立的“演绎三段论(syllogisms)”。(由此看出,三段论那种是演绎推理)
因果推理
图灵奖获得者 Pearl 将因果推理分成 3 个由下而上的层次:
- 关联(association): 直接可从数据中计算得到的统计相关;
- 介入(intervention):无法直接从观测数据就能得到关系,如“某个商品涨价会产生什么结果”这个问题不仅与新价格有关,而且会与客户购买行为、用户收入等等因素相关;
- 反事实(counterfactual):某个事情已经发生了,则在相同环境中,这个事情不发生会带来怎样的新结果
记忆驱动的推理
智能行为多依赖于记忆系统,研究发现人类记忆有感觉记忆(sensor memory)、工作记忆(working memory)和长期记忆(long-term memory)[3-5]。为了应对各种认知任务,大脑要在短时间内保存和处理各种感兴趣信息,完成这个过程的大脑系统就是“工作记忆”。工作记忆是形成语言理解、学习与记忆、推理和计划等复杂认知能力的基础。
在工作记忆区域中,当前输入信息(由感觉记忆加工的当前数据)以及非当前输入信息(从长期记忆中唤醒的历史信息,如已有知识和过往经验)一起发生作用。也就是说,人脑在进行感知和认知时,不仅要对当前数据进行处理,还需要调动大脑中存储的相关信息。因此,注意力与记忆在人的认知理解过程中扮演了重要的角色,特别是对于文本、语音与视频等序列数据的知识获取与推理过程至关重要。
人脑在理解当前场景和环境时,有效利用了与当前输入数据相关的信息,这些信息存储在外部记忆体(externalmemory)中
记忆驱动推理反映了人脑智能活动,要重点进行如下研究:
- 感知记忆、工作记忆和长期记忆中逻辑、描述、事实型知识的表示方法,从离散符号到分布式向量表达,为深度神经推理打下基础;
- 自上而下预测反馈与自底向上注意力相互结合方法,刻画短期记忆、工作记忆和长期记忆之间的交互机制,建立可计算推理手段;
- 场景理解目标驱动下记忆激活、自更新和自调整机制,实现知识自适应学习与推理。
后面两个应该是我要关注的重点。
什么是逻辑学派
逻辑学派主张用形式化方法来描述客观世界, 其认为任何推理是基于已有逻辑化知识而展开,如 一阶逻辑和谓词逻辑及定义在其上的推理演算。
逻辑学派在发展推理过程中始终围绕着如何从 已知命题/谓词出发推导出正确性结论这一核心。
逻辑派学者通过命题或一阶谓词来表示客观世 界 中 简 单 概 念
什么是知识工程学派
知识工程学派通过语义网络来表示更为丰富概念与知识,以刻画实体之间以及实体与属性之间所存在的关联关系。早期的知识图谱几乎依赖于专家知识而构建,即知识图谱 中的实体、属性与关系完全由专家人工构造,如 WordNet[1]和 CyC[2]等 。
大数据时代,基于数据驱动的机器推理方法来进行知识图谱构建逐渐成为国际知识图谱研究的主 要方向
基于符号规则推导或数据驱动计算的知识图谱推理方法各有优劣,前者解释性强而泛化能力弱、后者黑盒操作难以利用已有知识和先验。因此,需要加强如下内容研究:
- 有机结合规则引导与数据驱动方法、
- 面向资源匮乏特定领域的知识推理、
- 人在回路 的知识推理模型。
从 前者解释性强而泛化能力弱、后者黑盒操作难以利用已有知识和先验、有机结合规则引导与数据驱动方法、面向资源匮乏特定领域的知识推理 这些 CV 的模型里面也都是这样的,这就是 规则 VS 数据驱动的区别。
[5] 人工智能的未来 – 神经科学启发的类脑计算综述
知乎专栏文章链接:https://zhuanlan.zhihu.com/p/35416350
Neurobiology and Computational Neuroscience
模拟脑需要在神经生物学(Neurobiology)和计算神经学(Computational Neuroscience)基础上实现。
- 神经生物学侧重研究神经元和突触等脑组织的生物学机理;
- 计算神经学主要通过生物学机理对神经元以及神经突触等结构进行数学建模,并在模拟环境仿真以求其特征与生物脑相近。
一个是 认识生物机理;一个是发展计算模型。
人脑强大但低功耗
人类大脑是一个极度优化的系统,它的工作耗能仅为 25 瓦特,神经元的数量却在 10 的 11 次方(一千亿,100 billion)的数量级上,并且这其中的突触也达到了每个神经元有 10000 个。这样庞大的网络却有如此低的能耗,这是使得人类大脑在复杂问题的处理有绝对优势。
三代人工神经网络
早期的类脑计算(Brian-like Computing)也可以狭义的称为神经计算(Neural Computation),将神经元和突触模型作为基础,把这些模型用在许多现实中的识别任务,从而发挥模拟人脑功能
- 感知机(perceptron)是第一代神经网络
- 多层感知机(Multi-layer Perceptron,MLP)是第二代神经网络
- 脉冲神经网络(Spiking Neural Network,SNN)是第三代神经网络
感知机 和 多层感知机仅保留了神经网络结构,而极大简化了网络中的神经元模型
实际上生物神经元对信息的处理是以脉冲形式出现的生物电信号
脉冲神经网络(Spiking Neural Network,SNN)由 W.Maass 在 1997 年首次提出,其底层用脉冲函数模仿生物点信号作为神经元之间的信息传递方式
SNN 的优点是具有更多的生物解释性,一方面可以作为计算神经学对生物脑现象模拟的基础工具;另一方面,由于其信息用脉冲传递的特点,SNN 结构更容易在硬件上实现,如 FPGA 等片上系统(on-chip system)。但是,脉冲函数不可导,因此 SNN 不能直接应用梯度法进行训练,对 SNN 的学习算法一直是近年来主要的研究问题。
SNN 的神经元模型总体上来说是一类以微分方程构成的模型,带有时间属性。可以理解为传统的神经元只是当前时刻的输入与权重的加权和,SNN 的神经元则是在一定宽度的时间窗内的输入与权重的加权和。
类脑计算的研究趋势
- 首先是基础的生物脑中的神经元,突触及记忆,注意等机制的建模;
- 第二,基于生物机制建模的神经网络学习算法以及在模式识别等机器学习任务中的应用;
- 最后,基于生物激励的算法和神经网络的硬件系统研究。
[6] 史忠植:人工智能 第十二章 类脑智能
课程 PPT 链接 http://www.intsci.ac.cn/shizz/ai.html
“中国脑计划”的名称为“脑科学与类脑科学研究” 主要有两个研究方向:
- 以探索大脑秘密、攻克大脑疾病为导向的脑科学研究(脑认知与脑医学)
- 以建立 发展人工智能技术为导向的类脑研究(脑认知与类脑计算)
多模态脑影像技术是归在脑认知与脑医学下面的
[7] 李德毅院士:从脑认知到人工智能
链接:http://www.199it.com/archives/397624.html
从功能上逼近脑
如果每一个模块解决一个特定问题,然后千千万万个这样的模块集成起来,是否就能从功能上逼近人脑?
记忆认知
脑认知的核心是记忆,不是计算。人类的记忆力强,记忆量大,就是所谓的聪明。(那看论文多,也就是学术水平好,是不是这个道理)
记忆不是简单的存储,有一定的取舍,记忆是计算、简约、抽象
记忆可以分为三大块:瞬间记忆、工作记忆和长期记忆
记忆不是简单的储存,其伴随一定的取舍,而取舍就是通过计算进行简化和抽象的过程,记忆和计算总是同时发生的。通常,时间越长所丢失的信息就越多。记忆常常也存在联想和搜索,而模糊信息的联想与搜索恰恰也都是计算。所以无论语言记忆还是图像记忆,他们本质上都是统计记忆,越是长期的、大量的和反复的,就越难以遗忘。这里就类似于模型的训练,大量数据的训练的模型可以获得一个稳定、鲁棒的系统。少量数据训练的模型总是存在偏差,系统随着新数据的加入而变得不够稳定
重新认识卷积(利用卷积表达认知和记忆)
在卷积神经网络里,可以把卷积想象成一种混合信息的手段。想象一下装满信息的两个桶(一个桶是信号,另一个桶是卷积核),我们把它们倒入一个桶中并且通过某种规则搅拌搅拌。也就是说卷积是一种混合两种信息的流程。
李院士认为卷积之所以这么重要,不仅在于其能抽取图像特征,更重要的是卷积能度量记忆。记忆的可度量性才是对科研和工程最重要的,其表达形式正是已有认知和遗忘的卷积。

如上方程式表达,对于整体认知,遗忘和认知的乘积代表着某一时刻将遗忘这一效果加载到认知中。随时间的流逝,遗忘效果不停地加载到认知上,即每一个时间步认知和遗忘都会乘积一次。并且认知函数 f(x) 对整个记忆 h(t) 的贡献应该是随时间增大而减少的,这一点正好体现在卷积的特性中,即 g(t-τ) 函数中。因此 f(x)×g(t-τ) 的积分便是记忆的累积量。
下面这一组方程将感觉记忆、工作记忆和长期记忆进行了形式化表达

记忆包括识记、保持、再认和重现四个过程。也就是最开始由感觉记忆函数学习,但这个时候遗忘的速率是比较快的,随后工作记忆函数采用更慢一点的遗忘速率保持记忆,并在几次循环后达到长期记忆。
蒲慕明院士的报告,实验证明反向传播模式可能真的存在于生物机制中
记忆很重要,是因为在记忆使用一些机制后,其就可成为 Zero-shot 学习,或者是 One-shot 学习,这两种学习对没见过的数据也能处理。
交互认知
脑认知的一个重要特点是脑不同区域不同粒度的认知可以往返跳跃、并行处理。大脑皮质中形成的知识积累(粗粒度)和海马体中当前学习和思维的问题(中粒度),以及视觉神经中残留的感觉和观察(细粒度)可同时发生交互与关联,反映在不同尺度空间的灵活转换。
脑认知的另一个重要特点是脑通过感知和外部世界交互,通过视觉、听觉、触觉、嗅觉、味觉五感, 单模态或者多模态地交互,在交互过程中和其他自然人、机器人、外部世界互动,尤其是理解自然人的表情、心理、意愿、动机等,相互启发、学习, 交互的结果使得认知更准确,自己更聪明。如果没有这种交互,自身难以获得这样的认知。(感觉是在暗示 多模态学习 和 强化学习)
再讲一个知识点,脑的自定位和自导航,我们把它叫做 iSLAM。人不断的把外部世界放在自己的坐标系做影射,这个很重要,人脑里面甚至有一定的盲导航功能。当然小脑发达程度不一样,个人能往前走的程度也不一样。脑认知的坐标系按照现在物理学定律应该是对数极坐标系。所以我们的视力表,第一个 E 字那么大,最后一个那么小,它不是线性关系,而是对数关系。
卷积神经网络的三大局限
- 第一个毛病,到底多少是深层次学习。多少个卷积核,每个卷积多大,怎么样来进行特征提取,都有太多的随意性和适凑性,而且不能保证拓扑结构参数的收敛,这是一个最要命的问题。
- 第二个毛病,由细尺度特征到大尺度特征的层层提取,只有前馈没有反馈,已有的认知不能帮助当前的视觉感知和认知,没有体现选择性(Attention 弥补了这种选择性了么?)。
- 第三个毛病要求海量训练样本,一万个样本做了半天,最后能够识别一百个东西。一万个样本你让我指定,最后识别了一百个,不划算。尤其从样本的均等性,没有反映认知的累计性,所以我觉得在座的这么多听众,如果你们觉得我的报告值钱的话,这张片子最值钱。(要有举一反三的能力,这个举一反三 不是说 训练举一 - 测试反三,而是在训练内部就举一反三 )
脑认知单元 vs 图灵模型
图灵模型和冯诺依曼计算机,充其量只具有计算机智能。计算机的架构中,计算、存储和交互相互分离,导致内容不同区域的数据频繁访问,以及硬盘和内存间数据的频繁访问。
而脑认知的构成单元,应该同时具有记忆智能、计算智能和交互智能,大大降低能耗。
脑认知形式化的尺度选择
脑认知的形式化,最关键的是要懂得忽略和聚焦,懂得抽象和分离。
[8] 郑南宁:人工智能的下一步是什么?
非完整信息处理问题
当前人工智能的研究前沿之一是如何实现由完整信息到非完整信息的处理,构建更加健壮的人工智能,使人工智能系统对用户错误、目标偏差、错误模型以及未建模对象具有更 好的适应性。无人驾驶就是一种典型的非 完整信息处理问题。
由于我们不可能为所有的问题建模, “未知的未知”问题对构建稳健的人工智 能系统提出了挑战。为了设计更加健壮的 人工智能,需要采用稳健优化、学习因果模型和组合模型等方法来提高人工智能建 模问题的稳健性。(因果是克服 未知的未知 的一种手段,这可能就是人类为什么只要小样本就可以了的原因)
人的认知过程,在很多场合下是从全局到局部的,在大量先进知识的前提下,往往是一种自上而下的过程。
[9] 脑科学与类脑研究概述
Marr 不但是计算机视觉的开拓者,还奠定了神经元群之间存储、处理、传递信息的计算基础,特别是对学习与记忆、视觉相关环路的神经计算建模作出了重要贡献(我的 Marr 的工作一无所知)
- 人工智能符号主义研究的出发点是对人类思维、行为的符号化高层抽象描述,20 世纪 70 年代兴起的专家系统是该类方法的代表
- 以人工神经网络为代表的联接主义的出发点正是对脑神经系统结构及其计算机制的初步模拟。
理解大脑的结构与功能, 理解认知、思维、意识和语言的神经基础(这是 Science 的人干的)
Minsky 干了神经网络两次
Minsky 干了神经网络两次,第一次是指出单层感知器无法表示异或函数,后来被用 BP 优化的多层感知器克服(MLP 早有,但起初没法训练,BP 解决了这个问题,才算克服这个问题);第二次是 指出当时计算能力的提升不足以支持大规模神经网络训练,这个被深度学习的诞生和 GPU 的发展克服。
图灵机计算的本质
图灵机计算的本质是需要人们对现实世界进行形式化的定义,模型能力取决于人对物理世界的认知程度, 因此人限定了机器描述问题、解决问题的程度。这使得 目前的智能系统在感知、认知、控制等多方面都存在巨 大瓶颈。例如还难以实现海量多模态信息的选择性感知 与注意、模式识别与语言理解在处理机制与效率等方面 与人脑相比还存在明显不足,需要针对某个专用问题非 常依赖人工输入知识或提供大规模标记训练样本
因此,人工智能要满足现实需求还缺乏足够的适应性,没法处理新问题,因为新问题没有事先在这个系统里被形式化定义好,这个的根源在于图灵机的本质(难道不是 数学 的本质?)
语音识别、 图像处理、自然语言处理、机器翻译等采用不同的模型 和不同的学习数据,两种不同的任务无法采用同一套系统进行求解,不同任务之间知识也无法共享。而人脑却 采用同一个信息处理系统进行自动感知、问题分析与求 解、决策控制等。这说的是 目前的人工智能技术缺乏通用性,而人脑是一个通用系统,知识可以共享。
脑科学与类脑研究
脑科学与类脑研究是两个目标完全不同的领域:脑科学的目标是要理解大脑的结构和功能、演化 来源和发育过程,以及神经信息处理的机制。类脑研究的目标是研发出新一代的智能技术,推动信息产业的发 展。
[10] 人工智能中的联结主义和符号主义
人类的智能主要包括归纳总结和和符号逻辑演绎(这两个都算推理),对应着人工智能中的联结主主义和符号主义。(目前的机器学习里面没有 符号逻辑演绎的内容,这也就是 朱松纯 在 正本清源的文章里面提到的)
符号主义
符号主义的主要思想就是应用逻辑推理法则从公理出发推演整个理论体系
人工智能中,符号主义的一个代表 就是机器定理证明
联结主义的缺陷:没有坚实的理论基础。通过仿生学和经验积累得到的突破,依然无法透 彻理解和预测
海马体与梦
大脑中有一对海马体(Hipocampus),它们和人类的长期记忆有关。如果把大脑比喻成一个数据库, 那么海马体就像是索引。如果海马体有问题,那么许多 存入的记忆无法被 取出,同时也无法形成新的记忆。每天晚上,海马体将当天形成的短暂记忆加工成长期记忆,在这一过程中,就形成了梦。海马体和其他神经中枢相连,处理其他中枢已经处理好的数据,形成新的编码。海马体和视觉与听觉中枢直接相连,因此在梦中能够看到 并且听到;但海马体和嗅觉中枢不相连,因此在梦中无法闻到气味
高级中枢向低级中枢反馈
实际上,视觉处理的过程并不只是 从低级向高级传递的单向过程,高级中 枢可以向低级中枢发出反馈信息,最明 显的例子是高级中枢可以决定低级中枢的“注意力”和“焦点”。当看到模糊不清或一时无法辨认的图像时,高级中枢会产生各种概率上合理的解释,并且由这种猜测先入为主地影响低层中枢的判断,从而产生错觉
层次特征
从视网膜到第一级视觉中枢的大脑皮层曲面的映射是保角映射,保角变换的最大特点是局部保持形状,但是忽略面积大小,这说明视觉处理对于局部形状非常敏感。
视觉高级中枢忽略色彩、纹理、光照等局部细节,侧重整体模式匹配和上下文关系,并可以主动补充大量缺失信息(这个主动补充就跟后面的错觉有关系,也就是高级中枢向低级中枢反馈)
[11] 视觉选择性注意的模型化计算及其应用前景
什么是注意?
三 大认知功能:记忆、注意、意识
“注意”在记忆与意识的引导下决定人类视觉感知的主动特性,其中最为核心的视觉选择性注意(Visual Selective Attention,VSA)机制,使人具备从复杂环境中搜索感 兴趣目标的能力。同时,这种主动行为特性也是当前机器视觉区别于人类视觉的沟壑所在
人眼具有 VSA 特性主要源于大脑中可用资源的限制(现有的计算资源也是有限的,尤其是无人自主系统,比如 UAV,所以 VSA 也是有限资源下的必然选择,这是研究 VSA 的现实动机),尤其是视觉系统接受的信息量与大脑中神经细胞的数目相差无几。 其次,外界环境的所有信息对于观察者来说并不是同等重要(这是研究 VSA 符合实际情况的动机),因此大脑只需要对部分重要信息做出响应。
人类视觉系统能瞬息感知外部世界,其主要原因是人脑中关于物体知识的记忆以及意识的引导与环境刺激驱动相结合所引发的视觉选择性注意起着重要的指向与汇聚作用,极大地 提高了视觉感知的有效性(关于物体知识的记忆、意识引导,记忆还可以理解,究竟什么是意识?Top-Down 的 Task Driven?)
人类完美的视觉系统是智能化视觉信息处理系统的典范(这就是最简单的为什么要研究类脑计算的动机,这是联结主义的动机)
人类的主动视觉 (Active Vision,AV)行为是在大脑意识驱动下、记忆与注意共 同引导的视觉感知方式。 其中 VSA 作为 AV 的核心,最重要的功能在于协调外界信息量与人脑资源的不平衡,实现大脑资源的合理分配。(在大数据时代特别重要)
VSA 强调有意识有目的的行为
Marr 视觉理论
Marr 视觉理论的核心问题是设法从图像结构推导出外部世界的三维结构,视觉从图像开始,经过一系列的处理和转换,最后达到对外部现实世界的认识(对外部世界的认识由三维结构来表示?)。
视觉计算框架中的信息流通路是自下而上单一方向的,对高层知识的引导和反馈缺乏足够的重视,与人类视觉系统有目的的、主动的认知过程相距甚远。
知识引导下的主动视觉感知成为 Marr 理论较为完美的补充
主动选择行为的引入,使得传统的 Marr 视觉框架中信息表示的计算约束变得易于解决(Visual Selective Attention + 3D 重建)
视觉信息处理通路
目前生理学普遍认为视觉信息处理通路分为三个阶段:最早的处理阶段包括 视网膜、侧膝体(Lateral Geniculate Nucleus,LGN)、主视皮层区(Primary Visual Cortex),在灵长目动物中也称为 V1 区,都是通过提取简单的局部特征如中心-外周感受野以及具有朝向的线与边缘进行编码来表达图像。这种编码来源于去相关与冗余的计算准则或者采用稀疏编码对输入图像可靠的重建。早期处理过后,有效且适度的复杂特征在 V4 以及与其相邻的 TEO 区表达,最后,部分或完整的感兴趣物体视图在 IT 皮层的前区表达[23]。
VSA 模型化计算
VSA 的模型化计算的核心还是围绕如何构建由刺激引发的自底向上的数据驱动与任务导引下的自顶向下的目标驱动的视觉注意的数学模型所展开,以及由此而引发的信
息流通路的分叉与汇合问题的研究
Koch 和 Ullman 于 1985 年提出的视觉选择注意模型开 创了 VSA 模型化计算的新纪元。 显著图(Saliency Map)的概念也是由他们在那时提出。 Koch-Ullman 模型第一次提出了 先计算后选择的观点,并提出利用“赢者全取”(Winner Take All,WTA)与抑制返回(Inhibit of Return,IOR)机制,实现凝视 点的选取与转移,且转移必须遵循两条规则,一是距离优先, 二是特征相似优先。
将其提高到数理水平的定量计算主导了其后 VSA 模型化计算的研究方向。 Itti 和 Koch[28]于 1998 年在 IEEE Transactions on PAMI 上发表了一篇关于视觉场景快速分析的文章,其中最主要的贡献就是将 VSA 机制从本质上推向了模型化定量计算的新阶段,使 VSA 在从神经生 理学的机制理论研究到信息科学领域的可计算性分析,进而 走向定量计算的工程应用的发展过程中发挥了重要的里程 碑作用。
模型首次运用数学工具对已有生理机制的仿生建模,沟通了神经生理学、心理学与计算机科学、数理科学的桥梁
VSA 模型化计算的关键环节
- 如何产生中央区自下而上兴趣图;
- 视觉任务和物体知识的表达;
- 自上而下与自下而上双向信息流的汇合
- 显性注意中凝视点的转移控制
自下而上兴趣图
中央区自下而上兴趣图的产生在 VSA 的研究中,其核心问题在于如何选择一种合适的显著性度量方法,使得选择的区域能够在其他区域中突显(pop-out)[31],即找到输入图像中的感兴趣区域。
目前针对自下而上兴趣图的产生主要以目标先验信息是否存在为算法研究的依据。
当存在先验目标信息时,由于人脑执行基于内容语义的高级视觉注意,与视觉任务、物体和环境的知识有关,并且与模式识别和匹配密不可分
当目标先验信息不存在的时候,就像把人置于完全陌生的环境中,脑认知功能通过对于“pop-out”研究的实验结果认为此时刺激特征主要表现在当刺激物之间由低对比度转向高对比度时能引起感受野细胞的空间重组织,从而引起观察者的注 意[40-41]。 因此,采用对比度衡量显著性将是自底向上模型合理仿生的途径。
物体知识的表达
语义网络模型的引入可以用来描述物体之间的关系
语义内容已经被证实是最佳搜索路径的预测线索,因此,建立大规模的真实世界语义模 型对选择性注意机制建模具有重要的意义
运用语义网络模型表达的调节控制注意选 择区域
对于双向信息流的汇合,常见的方法主要是通过得到目标先验信息, 再加以对底层特征的调制,即信息流在显著图汇合(激活)
至于两者之间,究竟谁执导谁的问题阐述, 较为有名的是 Wolfe 在特征整合理论的基础上提出的导向搜索理论(Guided Search)[34]。该理论假设存在两个加工阶段,首先是特征加工阶段,类似于特征整合理论的第一阶段; 在第二阶段上,Wolfe 认为在特征识别之后,来自自上而下和自下而上的信息可以联合起来对注意进行引导,在这个过程中那些和被试期望相匹配的奇异刺激最有可能获得注意,两种信息的结合可以使 对复合刺激的搜索快速完成。
自上而下的线索对底层视觉特征的调制是精细粒度,即目标与分心物在单一的特征维内所在的区间也能影响搜索的速度
对底层特征各特 征维部署不同的特征权重得到的显著区域也会大相径庭。 同 时也有文献中的方法通过最优化策略得到不同特征维的自下而上显著图的相关权值,并通过学习得到的统计信息优化自底向上信息流中各底层特征信息的权重,提升目标显著性,抑制背景显著度
针对目前生 理学的研究成果,权值调制是一种可行的途径[57]。但从权值调制 中引发的权值设置也是信息科学领域中机器学习研究的热点 问题,目前已有基于 Bayes 网络的统计学方法[58],基于场景内容 的方法[38]等用来解决 VSA 模型化计算中的该类问题
Attention 很重要,但之前 Attention 权值都要设置;而现在已经是学出来的了,这就是进步以及 Attention Network 伟大的地方。
在目标检测中的应用
VSA 通过引导高效可靠的视觉感知成为众多灵长目类 动物一项重要的心理调节机制,以过滤筛选的方式提取视觉 感知中的有效信息即目标相关信息,从而合理分配大脑视皮 层中的信息加工资源。因此,其应用的直观体现即是目标检测
值得研究的问题
- 如何合理地融入记忆与意识对自底向上视觉搜索的影响(这点是我感兴趣的)
- 如何找到衡量模型性能的标准
- 如何将显性 的眼动注意予以考虑,并将其与隐性注意相融合,找到它们 之间的切入点
[12] 刘成林:从模式识别到类脑研究
“人工智能”(artificial intelligence)概念最早由 John McCarthy 等在1956年的达特矛斯会议(Dartmouth Conference)上提出:人工智能就是通过计算机编程使机器实现类人智能行为
模式识别
模式识别有 2 个层面的含义:
- 一是生物体 (主要是人脑)感知环境的模式识别能力与机理,属于心理学和认知科学范畴;
- 二是面向智能模拟和应用,研究计算机实现模式识别的理论和方法,属于信息科学和计算机科学领域 的范畴。
模式识别基础理论(模式表示与分类、机器学习等)、视觉信息处理(图像处理和计算机视觉)、语音语言信息处理(语音识别、自然语言处理、机器翻译等)是模式识别领域的三大主要研究方向。刘成林解释,模式识别是人工智能的一个分支领域。人工智能是通过计算使机器模拟人的智能行为,主要包括感知、思维(推理、决策)、动作、学习,而模式识别主要研究的就是感知行为。在人的 5 大感知行为(视 觉、听觉、嗅觉、味觉、触觉)中,视觉、听觉和触觉是人工智能领域研究较多的方向。模式识别领域主要研究的是视觉和 听觉,而触觉主要是跟机器人结合。
以深度学习为代表的主流方法有 3 个明显的不足:
- 一是需要大量的标记样本进行监督学习,这势必增加模式识别系统开发中的人工成本;
- 二是模式识别系统的自适应能力差,不像人的知识和识别能力是随着环境不断进化的;
- 三是模式识别一般只进行分类,没有对模式对象的结构解释。
类脑智能
类脑智能就是以计算建模为手段,受脑神经机理和认知行为机理启发,并通过软硬件协同实现的机器智能。
类脑智能研究的软件方向:
- 一是使智能计算模型在结构上更加类脑(联结主义)
- 另外一方面是在认知和学习行为上更加 类人(行为主义)
[13] 深度学习:多层神经网络的复兴与变革
深度学习成功的启示
优化方法的变革是开启深度学习复兴之门的钥匙
Hinton 等 2006 年的主要 贡献是开创了无监督的、分层预训练多 层神经网络的先河
但实 际上最近 3 年来 DCNN 的繁荣与无监 督、分层预训练并无多大关系,而更多 的与优化方法或者有利于优化的模块 有关,如 Mini-Batch SGD、ReLU 激活函数、Batch Normalization 等,特别是其中 处理梯度消失问题的手段
从经验驱动的人造特征范式到数据驱动的表示学习范式
在信息表示和特征方面, 过去大量依赖人工的设计,严重影响了 智能处理技术的有效性和通用性。深 度学习彻底颠覆了这种“人造特征”的 范式,开启了数据驱动的表示学习范 式。具体体现在: 1)所谓的经验和知识也在数据中,在数据量足够大时无需显式的经验或知识的嵌入,直接从数据 中可以学到;2)可以直接从原始信号开始学习表示,而无需人为转换到别的空间再进行学习。
从“分步分治”到“端到端的学习”
分治或分步法,即将复杂问题分解 为若干简单子问题或子步骤,曾经是解 决复杂问题的常用思路
但从深度学习的视角来 看,其劣势也同样明显:子问题最优未 必意味着全局的最优,每个子步骤是最 优的也不意味着全过程是最优的
相 反,深度学习更强调端到端的学习 (end-to-end learning),即:不去人为的 分步骤或者划分子问题,而是完全交给 神经网络直接学习从原始输入到期望 输出的映射。相比分治策略,端到端的 学习具有协同增效(synergy)的优势,有 更大的可能获得全局上更优的解。当 然,如果一定要把分层看成是“子步骤 或子问题”也是可以的,但它们各自完成什么功能并不是预先设定好的,而是 通过基于数据的全局优化来自动学 习的
脑神经科学启发的思路值得更多的重视
Fukushima 在 1980 年底提出的认知机 模型,而该模型的提出动机就是模拟感 受野逐渐变大、逐层提取由简及繁的特 征、语义逐级抽象的视觉神经通路
生物神经系统的连接极 为复杂不仅仅有自下而上的前馈和同层递归更有大量的自上而下的反馈以及来自其他神经子系统的外部连接这些都是目前的深度模型尚未建模的
如何赋予机器演绎推理能力
基于大数据的深度学习可以认为 是归纳法,而从一般原理出发进行演绎是人类的另一重要能力,特别是在认知和决策过程中,我们大量依赖演绎推理。演绎推理在很多时候似乎与数据无关。(这是人能够实现小样本、弱监督学习的关键)
[14] 从脑网络到人工智能 —— 类脑计算的机遇与挑战
如何实现小样本的学习和有效推广?
目前取得巨大成功的深度学习依赖于庞大的样本数量,这与大脑卓越的“举一反三”,即小样本学习的能力形成鲜明对比[11]。原理上看,这意味着生物脑的学习过程并非从零开始,而是从学习之初,就拥有并运用了重要的先验知识,这包含了物种在进化过程中学到的(生物学称之为系统发生),以及个体在生活过程中学到的有关真实世界的关键知识[12]。读取这些知识,以及借鉴如何将这些知识作为先验信息注入神经网络结构从而实现小样本学习,可能会是神经科学以及类 脑算法设计中一个富于成果的领域。(我觉得不仅仅有先验知识的积累,还有推理能力,那么问题来了,推理能力强可以是因为先验知识多么,什么都见过,自然一下就能知道事情发生的后果)
[15] 人工智能在军事领域的渗透与应用思考
人工智能的三个层次
- 运算智能即快速计算和记忆存储能力。旨在协助存储和快速处理海量数据,是感知和认知的基础,以科学运算、逻辑处理、统计查询等形式化、规则化运算为核心。在此方面,计算机早已超过人类,但如集合证明、数学符号证明一类的复杂逻辑推理,仍需要人类直觉的辅助。
- 感知智能即视觉、听觉、触觉等感知能力。旨在让机器“看”懂与“听”懂,并据此辅助人类高效地完成“看”与“听”的相关工作,以图像理解、语音识别、语言翻译为代表。由于深度学习方法的突破和重大进展,感知智能开始逐步趋于实用水平,目前已接近人类。
- 认知智能即“能理解、会思考”。旨在让机器学会主动思考及行动,以实现全面辅助或替代人类工作,以理解、推理和决策为代表,强调会思考、能决策等。因其综合性更强,更接近人类智能,认知智能研究难度更大,长期以来进展一直比较缓慢。
[16] 感知智能到认知智能中对知识的思考
认知心理学将人脑认知世界的过程可以总结为:感知到认知,从认知到理解

认知是大脑把感知得到的信息与已有信息产生联系,得到信息结果是什么的这一过程。为什么是联系,因为人脑对某一个状态的判断并不是独立的,比如看见一辆汽车,你是怎么判断它是汽车,定是你把这辆汽车与头脑中已有的汽车信息进行关联,你才知道。如果你从没有见过汽车,你也不知道这个东西是什么。
理解就是你对认知得到的信息有了一些相对固化认知,比如见到很多辆车的样子,就车的形状有了一个固化的认知,你理解了什么是真正的车。
感知得到信息 -> 认知把感知得到的信息与已有信息联系 -> 理解就是对这类信息形成固化认识。
知识是人为理解和经验充实的信息,是被证明在一段时间范围内正确的信息。因当前的人工智能算法通常只能针对特定数据集执行特定任务,一旦任务条件超出了限制,人工智能就会瞬间沦为 “人工智障”。所以对于人工智能来说,掌握人类知识和常识是下一阶段的重要目标。而如何获得人类所具有的知识和常识?大规模知识工程构建的知识图谱就成为了人工智能的一个重要要点。
智慧是在大量知识积累基础上,并对知识有了深入的理解,能举一反三产生新的洞察。因其具有了洞察力、迁移性和创造性,就克服了当前弱人工智能仅能针对单项任务的缺陷,从而实现了强人工智能。(人之所以能够小样本学习,是因为人是有智慧的,不仅有知识还有推理能力)
[17] 机器学习: 现在与未来
机器学习是人工智能的一个分支学科,主要研究的是让机器从过去的经历中学习经验,对数据的不确定性进行建模,在未来进行预测。(学习经验、对不确定性建模、对未来预测)
谷歌 AlphaGo 的成功,告诉我们结合机器学习与传统符号搜索方法可以解决人工智能里相对复杂的推理问题(解决复杂推理问题的途径)
在计算机视觉领域,即使我们在人脸识别和图片分类上取得了不小的成就,但是对于关系理解和完整的场景认知,现在系统能做到的还很有限(后面 CV 的研究重点应该放在 关系理解和完整的场景认知 上)
[18] 小样本的类人概念学习与大数据的深度强化学习
这篇文章就是介绍 Human-level concept learning through probabilistic program induction,贝叶斯规划学习的,做的是小样本学习问题
深度学习是一种机器学习中建模数据的隐含分布的多层表达的算法
强化学习,其实就是一个连续决策的过程,其特点是不给任何数据做标注,仅仅提供一个回报函数,这个回报函数决定当前状态得到什么样的结果(比如“好”还是“坏”),从数学本质上来看,还是一个马尔科夫决策过程。强化学习最终目的是让决策过程中整体的回报函数期望最优。
[19] 人工智能: “热闹”背后的“门道”
人类智慧、人类智能、人工智能
人类智慧最为充分的表现就是为了实现自己的目标而不断地发现问题、定义问题和解决问题的能力
发现问题和定义问题的能力是人类智慧之中最具创造性的能力,这是因为,发现问题和定义问题是人类寻求进步的第一步,也是最重要的一步;这种能力有赖于人类的目的、知识、直觉、想象、审美、灵感和顿悟这样一些抽象的隐性能力,因此通常被称为“隐性智慧能力”
解决问题的能力则是人类智慧之中最具操作性的能力,主要有赖于获取信息、提炼知识、演绎智能策略和执行智能策略这样一些显性的操作能力,因此通常被称为“显性智慧能力”
人们把隐性智慧和显性智慧的整体称为“人类智慧”,把具有操作性特色的显性智慧称为“人类智能”。于是,可以把探索、理解和模拟“人类智能(显性智慧能力)”的研究称为“人工智能”研究。
弱人工智能:对“人类智能(显性智慧能力)”的探索、理解、模拟和扩展
强人工智能:对“人类智慧(包括隐性智慧和 显性智慧两者)”的探索、理解、模拟和扩展
AI 时代的工作方式
AI可以远远高于人类的工作速度、远远优于人类的工作精度、远远胜过人类的工作耐力,协助人类解决各种各样的问题,甚至在危险环境和极端环境等场合代替人类去完成各种任务
人类发挥驾驭和引领的作用主要负责发现问题和定义问题,即负责
- 明确描述所要解决的问题
- 预设问题解决所应当达到的目标
- 提供解决问题所需要的知识
这三者的联合就构成了解决问题的工作框架
这就是人们所说的“人机 共生”的工作方式,更确切地说是“人为 主、机为辅的人机合作”工作方式。
基于结构模拟的人工智能(人工神经网络)的原理是:在投入工作之前需 要对人工神经网络进行训练,以便学习到求解问题所需要的经验知识(表现为各个神经元之间的连接权重),从而解决相应的问题。
[20] 人工智能研究的三大流派: 比较与启示
- 符号主义认为智能是基于逻辑规则的符号操作;
- 联结主义认为智能是脑神经元构成的信息处理系统;
- 行为主义认为智能是通过感知外界环境做出相应的行为
符号主义
符号主义,也被称之为逻辑主义,它是基于还原论的理性主义方法。该学派认为智能的基本元素是“符号”,人的认知过程是一个信息加工过程,通过对符号的逻辑演绎与推理等方式可以将智能活动表达出来。他们将信息加工系统也就是通常所理解的“认知系统”看作是一个巨大的符号加工系统,将智能系统理解为物理符号系统。设计好的信息处理程序将智能活动形式化为某种算法,通过算法对搜集到的信息进行逻辑处理,使得机器最终输出智能结果。
符号主义的缺点:还原论的理性主义方法无法对复杂系统的问题进行有效处理,简单的线性分解会使得系统复杂性遭到破坏,并且形式化的处理方式对常识问题采取了回避态度;复杂的现实世界,使得符号系统无法周全地完成万能逻辑推理体系,从而开始走向衰落。逻辑演绎并非人类智能的全部,对符号主义而言,非逻辑思维是其无法实现的障碍;对人类直觉思维、情感思维以及联想思维等的模拟,是符号主义的“短板”
联结主义
联结主义也被称之为仿生学派。通过模拟人类神经系统的结构与功能,联结主义试图使机器拥有智能
人工神经网络科学研究是联结主义研究的重要部分
行为主义
行为主义,也被称之为进化主义。行为主义认为智能行为就是通过与环境交互对感知结果做出相应行为。基于控制论的“感知—动作”模式,行为主义希望能够通过模拟生物的进化机制,使机器获得自适应能力
行为主义认为智能取决于感知与行为,以及智能取决于对外界环境的自适应能力的观点
由于行为主义的经验主义表现,在智能的实现过程中,不存在符号主义里无限的形式系统的尴尬,也不像联结主义那样需要对人体结构极度透彻的了解。它只需要智能体通过“感知—动作”型控制系统,以进化计算或强化学习的方法,通过对外部感知而做出的反应进行进化和学习,同时找寻合理的协调机制对智能体内部进行自我协调与主体间协调
与符号主义及联结主义相比,行为主义不再执着于 “内省式”的沉思,而是在与外界交互过程中用具体行为去拥抱真实世界
符号主义和联结主义还算是 “内省式”的沉思,向内求;
三大流派的比较
- 符号主义认为智能是基于逻辑规则的符号操作,人的认知是符号计算的过程
- 联结主义认为智能是脑神经元构成的信息处理系统,人类的认知是脑神经元运动的经验结果
- 行为主义认为智能就是通过感知外界环境做出相应的行为,认知活动是对外界环境“感知—动作”的反应模式。
基于对智能的理解不同,三大流派对“认知”都提出了自己的观点。
- 符号主义是对人类逻辑演绎思维的模拟(认知就是计算)
联结主义对应的则是人类归纳推理思维的再现(认知是脑神经元运动的经验结果)
符号主义是直接复制人类的演绎推理能力来实现人工智能。
- 联结主义是从通过对生物内在组织的模仿来实现人工智能;
- 行为主义是从通过对生物外在行为的模拟来实现人工智能;
符号主义认为智能是基于逻辑规则的符号操作,他们从“符号是智能行动的根基”出发,认为有机体是带程序的“活生生的机器,智能的核心就是根据某套规则作出理性决策”[10],符号主义对于智能的表达方式,我们可以理解为是这样的一个过程:模拟人类逻辑思维去设计信息处理程序,对搜集到的信息符号化并按照程序进行逻辑处理,最后输出知识或行为完成智能的表达。符号主义主张功能模拟方法,坚信只要建立出一个通用的、万能的逻辑运算体系,就可以使计算机模拟人类的思维。诚然,知识是对信息的积累以及重新组合,智能的基本元素是符号的观点同人类的逻辑演算能力相契合。;符号主义研究者是企图绕过大脑和躯体,利用对行为的形式化去认知世界的本质的“最后的形而上学家”;由于注重智能对信息的逻辑运算结果,而不注重对信息的归纳总结,从而引起了联结主义的强烈排斥,与联结主义形成了很大的理论分歧
人工智能三种学派的研究方式各有优劣,“精确性”可以通过运用规则、符号进行表征而获取(符号主义),但“灵活性”却需要通过统计性描述才能得到(联结主义)
符号主义擅长知识推理,联结主义擅长技能建模,行为主义擅长感知行动(所以应该将三大流派尽量融合才可以通向更好的 AI)
符号主义对应 逻辑演绎,联结主义对应 归纳推理,逻辑演绎与归纳推理是人类智能中的两种主要思维能力。
归纳和演绎
人类认识活动,总是先接触到个别事物,而后推及一般(归纳,Induction),又从一般推及个别(演绎,Deduction),如此循环往复,使认识不断深化。
归纳(Induction)就是从个别到一般,演绎(deduction)则是从一般到个别。
归纳和演绎这一组,描述的是特殊和一般的关系
归纳是从个别的或者特殊的现象中概括出一般性的原理。而演绎是从一般性的原理推演出个别性的结论。
综合和分析这一组是针对整体与要素的分析方法。一般先分析后综合,分析就是把整体拆解也各个部分,把复杂的事物分解为简单的要素而各个击破,单独分析每一个要素的特点,获得每个要素的属性。而综合是把对象各个部分、属性、要素有机的结合到一起看,从而对这个整体的属性有个认识。
[21] 类脑智能研究的回顾与展望
图灵机模型和冯·诺依曼计算机体系结构
图灵机模型和冯·诺依曼计算机体系结构的提出,从计算本质和计算结构方面分别奠定了现代信息处理和计算技术的两大基石,然而两者共同的问题是缺乏自适应性(一个是自适应性很难实现,另外是因为当时只要计算原子弹等物理问题,不需要自适应性)
图灵计算的本质是使用预定义的规则对一组输入符号进行处理,规则是限定的、输入也受限于预定义的形式. 图灵机模型取决于人对物理世界的认知程度,因此人限定了机器描述问题、解决问题的程度.
冯·诺依曼体系结构是存储程序式计算,程序也是预先设定好的,无法根据外界的变化和需求的变化进行自我演化
(这么看来,只要图灵机模型和冯·诺依曼计算机体系结构,首先就不具有主动描述、定义问题的能力,由此看来是没有办法在图灵机上实现强人工智能的,因为强人工智能在解决问题的基础上还需要能够发现问题、定义问题)
难以实现海量多模态信息的选择性感知与注意
目前几乎所有的人工智能系统都需要首先进行人工形式化建模,转化为一类特定的计算问题(如搜索、自动推理、机器学习等)进行处理(没想到除了机器学习以外,还有搜索和自动推理这两个的存在)
强人工智能的核心问题之一便是问题的自动形式化建模
深度学习的缺点:深度学习的优越性能仍然限于特定领域(不是通用智能平台),其实现依赖大量标记样本(缺少弱监督、小样本学习能力,缺少知识和智慧),而且主要是离线学习,它的环境迁移和自适应能力较差(自适应能力弱、鲁棒性差).
大数据大部分为非结构化数据,如图像、视频、语音、自然语言等.机器对这些数据的理解能力与人类相比还有明显的差距,正是这种能力的不足阻碍了大数据的充分和有效利用
人脑是一个通用智能系统,能举一反三、融会贯通,可处理视觉、听觉、语言、学习、推理、决策、规划等各类问题,可谓“一脑万用”.并且,人类的智能感知和思维能力是在成长和学习中自然形成和不断进化的,其自主学习和适应能力是当前计算机难以企及的.因此,人工智能的发展目标是构建像人脑一样能够自主学习和进化、具有类人通用智能水平的智能系统
类脑智能
什么是类脑智能?
类脑智能是以计算建模为手段,受脑神经机制和认知行为机制启发,并通过软硬件协同实现的机器智能
由于类脑智能的手段主要是从机制上借鉴脑,而不是完全模仿脑,其对应的英文术语为“Brain inspired Inteligence”更为合适(这就是 脑启发啊)
类脑智能是脑与神经科学、认知科学、人工智能这三个科学的交叉学科
为什么是借鉴而非模仿脑?
人脑是进化的产物,在进化过程中存在各种设计妥协,因此从脑信息处理机制出发推动人工智能研究最优的途径应当是受脑启发、借鉴其工作机制,而不是完全地模仿(这一点很像商业里面,大鳄们分享自己的成功经验、原因,但完全 follow 经验肯定会失败,那只是幸存者偏差,不一定是导致对方成功的原因)
认知科学中的类脑智能研究
回答的科学问题:“人类的心智如何能够在物理世界重现;其具体的探索即是人类思维如何在计算机系统上重现
计算神经学中的类脑智能研究
计算神经科学是以计算建模为手段,研究脑神经信息处理原理的学科(和人工智能一样都是以计算建模为手段,区别在于计算神经科学的目的是研究(我觉得是验证更合适)脑神经信息处理原理,人工智能的目的在于是实现我们想要的结果,所以一个是 Science,是发现科学,一个是 Engineering,是工程科学)
计算神经科学研究的重点是通过多尺度计算建模的方法验证各种认知功能的脑信息处理模型
传统计算神经学与类脑智能的区别
传统的计算神经科学仍然更为关注神经系统表现出来的物理现象(如振荡、相变等) 和微观尺度的建模(如神经元尺度精细的连接结构、脑区尺度反馈的机制),对于整体的脑认知系统相对缺乏框架级别的计算模型
专注于极为精细的微观神经元及其微环路建模,目前较为完整地完成了特定脑区内皮质柱的计算模拟(可以看一下递归皮质网络)
人工智能中的类脑智能研究
人工智能的符号主义研究出发点是对人类思维、行为的符号化高层抽象描述,而以人工神经网络为代表的连接主义的出发点正是对脑神经系统结构及其计算机制的初步模拟.
人工智能研究集中在类人行为建模上,目标一般为行为尺度接近人类水平;
类脑智能研究分为 类脑模型与类脑信息处理、类脑芯片与计算平台 这两个方向性,所以就像一级学科、二级学科一样,更具体的感兴趣方向是 类脑信息处理
认知脑计算模型的构建
传统人工智能系统的设计与实现思路是: 从待解决问题相关数据的特点与问题目标的角度出发,从计算的视角设计算法. 这使得所实现的智能系统只适用于解决某一类问题.
类脑智能研究长期的目标是实现通用智能系统,这就需要首先研究人脑如何通过同一系统实现不同的认知能力,从中得到启发并设计下一代智能系统. 因此,类脑智能研究的首要任务是集成两百年来科学界对于人脑多尺度结构及其信息处理机制的重要认识,受其启发构建模拟脑认知功能的认知脑计算模型,特别需要关注人脑如何协同不同尺度的计算组件,进行动态认知环路的组织,完成不同的认知任务.
认知脑计算模型研究内容
- 多尺度、多脑区协同的认知脑计算模型: 根据脑与神经科学实验数据与运作原理,构建认知脑计算模型的多尺度(神经元、突触、神经微环路、皮质柱、脑区)计算组件和多脑区协同模型,其中包括类脑的多尺度前馈、反馈、模块化、协同计算模型等;
- 认知/智能行为的类脑学习机制: 多模态协同与联想的自主学习机制,概念形成、交互式学习、环境自适应的机制等;
- 基于不同认知功能协同实现复杂智能行为的类脑计算模型: 通过计算建模实现哺乳动物脑模拟系统,实现具备感知、学习与记忆、知识表示、注意、推理、决策与判断、联想、语言等认知功能及其协同的类脑计算模型
最核心的是研究 学习与记忆的计算模型
所有认知任务相关的脑区中,学习与记忆遵循相同的法则:即赫布学习法则(Hebb’sLaw)与脉冲时序依赖的突触可塑性(缩写为STDP)
认知脑计算模型 和 类脑信息处理 的区别?
我感觉 认知脑计算模型 就是计算神经学做的,所以研究认知脑计算模型是为了搞清楚机制;类脑信息处理 是 人工智能 做的,是为了对类人行为建模。
模型 Modeling 和 处理(依据 Cost Function 优化出想要的结果)
类脑信息处理
需要在认知脑计算模型的基础上进一步抽象,选取最优化的策略与信息处理机制,建立类脑信息处理理论与算法,并应用于多模态信息处理中(由此可见,模型 和 信息处理机制是不一样的,模型应该是一个表示方式,是没有应用目的导向的,而怎么处理是含有目的导向的 )
研究内容:
- 感知信息特征表达与语义识别模型: 针对视觉(图像和视频)、听觉(语音和语言)、触觉等感知数据的分析与理解,借鉴脑神经机理和认知机理研究结果,研究感知信息的基本特征单元表示与提取方法、基于多层次特征单元的感知信息语义(如视觉中的场景、文字、物体、行为等)识别模型与学习方法、感知中的注意机制计算模型以及结合特征驱动和模型驱动的感知信息语义识别方法等;
- 多模态协同自主学习理论与方法: 人脑的环境感知是多模态交互协同的过程,同时感知特征表示和语义识别模型在环境感知过程中不断地在线学习和进化
- 多模态感知大数据处理与理解的高效计算方法:面向大数据理解的应用需求,基于类脑感知信息表达和识别模型,研究面向感知大数据处理的新型计算模式与方法,如多层次特征抽取和识别方法,结合特征和先验知识、注意机制的多层次高效学习、识别与理解等;
- 类脑语言处理模型与算法: 借鉴人脑语言处理环路的结构与计算特点,实现具备语音识别、实体识别、句法分析、语义组织与理解、知识表示与推理、情感分析等能力的统一类脑语言处理神经网络模型与算法.
由 Hawkins 等人提出的分层时序记忆(Hierarchical Temporal Memory)模型更为深度借鉴了脑信息处理机制,主要体现在该模型借鉴了脑皮层的6层组织结构及不同层次神经元之间的信息传递机制、皮质柱的信息处理原理等.该模型非常适用于处理带有时序信息的问题,并被广泛地应用于物体识别与跟踪、交通流量预测、人类异常行为检测等领域.
这里的 Hawkins 就是 Jeff Hawkins,写 《On Intelligence》也就是 人工智能的未来的那个人,后来他徒弟出走创建的公司 vicarious 用的技术也是这个 HTM 的衍生,Vicarious 后来的 Paper 也上了 Science,就是 递归皮质网络
大部分数据是图像视频、语音、自然语言等非结构化数据,需要类脑智能的理论与技术来提升机器的数据分析与理解能力.
我感兴趣的内容
多层次特征抽取,结合特征和先验知识、注意机制,语义组织与理解,知识表示与推理,感知中的注意机制计算模型
[22] 类脑计算芯片与类脑智能机器人发展现状与思考
“类脑芯片”是指参考人脑神经元结构和人脑感知认知方式来设计的芯片。
类脑芯片研究的两大方向
方向一:神经形态芯片
“神经形态芯片”就是一种类脑芯片,顾名思义,它侧重于参照人脑神经元模型及其组织结构来设计芯片结构。
代表是 IBM 的 TrueNorth,高通的 Zeroth。高通的 Zeroth 在业界引起了巨大的震动。原因就在于它可以融入到高通公司量产的 Snapdragon 处理器芯片中,以协处理的方式提升系统的认知计算性能,并可实际应用于手机和平板电脑等设备中,支持诸如语音识别、图像识别、场景实时标注等实际应用并且表现卓越(在产业界能应用就会有很大的意义)
TrueNorth 芯片采用了神经形态的组织结构和新兴的“脉冲神经网络”算法
方向二:
参考人脑感知认知的计算模型而非神经元组织结构(由此看出,计算模型 和 神经元组织结构 是不一样的,计算层面 应该是高于 (计算机)组织结构的,一个是应用抽象层,一个是物理层)(专门针对深度学习算法设计,而不像 CPU 那样通用,就和算法一样,先验越强越符合,算法性能更好;这里也是,越是针对某类算法设计,效能越好)
代表就是 中科院的 DianNao 和 DaDianNao,寒武纪(全球首款深度学习处理器芯片)
类脑芯片完全可以同时参考神经元组织结构并支持成熟的认知计算算法,这并不矛盾。
冯诺依曼架构 vs 大脑架构
目前,传统计算机芯片主要基于冯诺依曼架构,处理单元和存储单元分开,通过数据传输总线相连。芯片总信息处理能力受总线容量的限制,构成所谓 “冯诺依曼瓶颈”。而且传统计算机的处理单元一直处于工作状态,导致能耗巨大。同时,由于需要精确的预编程,传统计算机无法应对编程以外的情况和数据。
大脑结构则完全不同:神经元 (处理单元) 和突触 (存储单元) 位于一体,不需要高能耗的总线连接,突触是神经元之间的连接,具有可塑性,能够随所传递的神经元信号强弱和极性调整传递效率,并在信号消失后保持传递效率。
[23] 国务院关于印发新一代人工智能发展规划的通知
链接:http://www.gov.cn/zhengce/content/2017-07/20/content_5211996.htm
适合我的人工智能关键共性技术
自主无人系统的智能技术。重点突破自主无人系统计算架构、复杂动态场景感知与理解、实时精准定位、面向复杂环境的适应性智能导航等共性技术,无人机自主控制以及汽车、船舶和轨道交通自动驾驶等智能技术,服务机器人、特种机器人等核心技术,支撑无人系统应用和产业发展。研究复杂环境下基于计算机视觉的定位、导航、识别等机器人及机械手臂自主控制技术。
关键词就是 自主无人系统 和 复杂动态场景感知与理解
[24] 谈方法论:归纳与统计
链接:https://zhuanlan.zhihu.com/p/34190289
我找到这篇文章是因为我想知道 归纳 与 统计有什么区别?都说统计机器学习,机器学习有不用统计的吗?
认识是从个别到一般, 又由一般再到个别的过程。通过个别认识一般的主要思维方法是归纳, 由一般认识个别的主要思维方法是演绎。
归纳
归纳方法是从个别或特殊事物概括出共同本质或一般原理的逻辑思维方法, 在逻辑上叫做归纳推理。
不完全归纳法是在考察了某类事物的部分个别对象后,就得出关于这类事物的一般性原理的方法。实际上就是对事物全集的子集进行抽象,得到部分子集的共性,而这个共性不一定就是全集的共性。(这点和机器学习很像)
结论的跨层级性。这个用集合去理解,通过对子集的归纳,得到了对母集属性的刻画,认识就从个性上升为共性,部分上升为整体,从偶然性上升为必然性。
统计
统计是不完全归纳常用的数学工具之一,统计方法实质上是归纳的低层次具现化。
统计,就是对样本性质做调查分析,去估计总体的性质。掌握统计思想,可以使得我们花费较小的成本和精力,就可以得到对广泛事物的高层级认识,达到见微知著、见微知萌的作用。(这么感觉,统计、压缩感知、机器学习 都是 见微知著、见微知萌 的味道)
统计的局限性:统计得到的数据和结论,仅仅只是现实的直观的表象的,得到的是相关性,而不直接是事物之间的本质联系,需要掌握好其他思维方法才能够利用好统计工具。比如说,我们统计一批老鼠,所有的正常老鼠碰见人都会逃跑,然后所有的被剁掉四条腿的老鼠看见人都不会跑,于是得出结论:老鼠的耳朵在腿上。
[25] 人工智能: 天使还是魔鬼?
人工智能系统的能力维度可分为信息感知 (perceiving)、机器学习 (learning)、概念抽象 (abstracting) 和规划决策 (reasoning). 目前人工智能系统在信息感知和机器学习方面进展显著, 但是在概念抽 象和规划决策方面能力还很薄弱. 总体上看, 目前的人工智能系统可谓有智能没智慧、有智商没情商、 会计算不会 “算计”、有专才无通才. 人工智能还有很多不能.
统计学习成为人工智能走向实用的理论基础。
[26] 类脑智能研究现状与发展思考
以往的人工智能
以往人工智能的研究成果属于行为尺度模拟部分智能的计算模型(可见基于类脑智能的人工智能研究是希望能够下沉到 脑信息处理机理、脑组织结构的尺度上模拟智能的计算模型,尺度上的下移)(这个下移有两个促因,一个是对脑机制的了解更加深入了,机理上到了某个相对成熟的点,另一个是现在的人工智能太消耗计算资源和数据,而人脑才 20 瓦可以小样本学习,有充分的动机)
脑与神经科学对人工智能的潜在启发
类脑智能研究的核心是受脑启发构建机制类脑、行为类人的类脑智能计算模型(计算神经学是要搞懂人脑认知机制、建立认知计算模型,这是机制类脑;人工智能则是实现 行为类人,行为类人 可以通过组织架构类脑来实现(脑启发),也可以不通过借鉴来实现)
脑的多尺度结构
- 微观:神经元、突触工作机制及其特性
- 介观:网络连接模式
- 宏观:脑区间的链路及其协同特性
在微观层面,突触方面, 如时序依赖的突触可塑性(Spike-Timing Dependent Plas- ticity, STDP)是一类时序依赖的连接权重学习规则,突触权值的变化主要依赖于细胞放电发生于突触前神经元和突触后神经元的先后时刻,通过对放电时间差与权重 更新建立数学映射关系,来描述网络中的神经连接强度的变化情况。(目前看来,我的兴趣点不会在围观层面去借鉴神经元、突触的工作机制)
在介观层面,特异性的脑区内部的连接模式和随机性的网络背景噪声的有效融合,例如生物神经网络中的泊松背景噪声对生物神经网络的学习和训练过程起到极大的促进作用(介观也不是我的兴趣点)
在宏观层面,脑区之间的连接不仅决定信号的传递,而且反映了信息处理的机制。如脑区之间的前馈连接可能反映了信息的逐层抽象机制,而反馈连接则反映了相对抽象的高层信号对低层信号的指导或影响。此外,有些脑区负责融合来自不同脑区的信号,从而使对客观对象的认识更为全面(如颞极对多模态感知信号的融合),而有些脑区在接收到若干脑区的输入后则负责在问题求解的过程中屏蔽来自问题无关脑区的信号(宏观层面是我的兴趣点,不管是 前馈对应的 信息的逐层抽象机制,反馈对应的 高层信号对低层信号的指导,还是 颞极对多模态感知信号的融合,还是屏蔽来自问题无关脑区的信号(注意机制)都是我感兴趣的,因此,我对于宏观尺度脑的工作机制、也就是信息处理机制比较感兴趣,而非脑的信号传递机制 )
要实现人类水平的智能,需要计算模型能够融合来自微观、介观、宏观多尺度脑结构和信息处理机制的启发。实现跨尺度机制的融合(但我对微观、介观并不感兴趣)
新一代人工神经网络模型
究竟什么才算新一代人工神经网络模型,从感知机-多层感知机-脉冲神经网络 这么去看,似乎指的是借鉴了更多生物机制的脉冲神经网络算新一代。但我觉得还是不要这样去想好,我感觉还是任意在结构上做了创新的都算新的神经网络模型,所以就不用去纠结是不是 新一代,只要是 新的就可以了。由此来说,这也就可以是我可以做的问题了。
目前在神经元的类型、突触的类型及其工作机理、 网络权重更新、网络背景噪声等方面,神经生物学的研究都取得了可以被计算模型应用的进展。(意思是说这些领域的成果形式化成数学模型可以加到现有结构来)
自顶向下的视觉注意就是来自于从高级认知脑区(如PFC、LIP 等)的脑活动到初级视觉脑区的反馈信号(这个脑的反馈,和 BP 优化根据 Loss 更新前面的权重一样吗?后者能算反馈吗?)
基于记忆、推理和注意的认知
记忆 (Memory)、推理(Reasoning)和注意(Attention)等 机制逐渐成为神经网络领域的新研究热点(Attention 多火就不说了,Reasoning 应该是 朱松纯那边的工作吧,记忆,不太清楚,也许是 LSTM 那些? 但这些的确是可以做的方向。)
合理采用记忆、推理和注意机制,可以有效地解决人工智能的很多核心问题
目前主要注意的问题:
- 记忆单元中存储哪些内容?
- 神经记忆单元中记忆的表示形式?
- 记忆单元规模较大时如何进行快速语义激活?
- 如何构建层次化记忆结构?
- 如何进行层次化信息推理?
- 如何对冗余信息进行遗忘或压缩处理?
- 如何评价系统的推理和理解能力?
- 如何从人类或动物记忆机制中获得启发?
“记忆” 具有自适应性,具有记忆单元的智能体可以从经验中学习,概括能力更佳,可以利用先验信息在不完整数据中进行更好地推理和预测。
从智能应用角度看,短时记忆由当前环境数据产生的状态编码更新和存储,而长时记忆是对历史信息进行高度经验性概括的编码,如概念、实体和结构化知识的表示。
早期利用神经网络对信息进行编码记忆的模型注重于神经记忆单元的结构化设计(早期放在怎么设计带有记忆功能的神经元单元结构,代表就是 LSTM)
注意机制是由外部刺激引发注意转变,从环境和非定长记忆编码单元中选择重 要信息进行融合,得到当前时刻刺激下有限长度的语义向 量。
人类视觉系统能够在复杂场景中迅速地将注意力集中在显著的视觉对象上,这个过程称之为视觉选择性注意(VSA)。人类的视觉注意过程包括两个方面:由刺激驱动的自下而上的视觉注意过程和由任务驱动的自上而下的视觉注意过程。(在 CV 中,复杂场景可以成为为什么要应用注意机制的一个动机)
DNN 所忽略的很多生物规则可能恰恰是实现类脑智能的关键(如对于时间的编码、抑制性神经元在网络中的特殊作用等)
关于类脑智能模型的进一步思考
脑是自然界中最复杂的系统之一,由上千亿(10的11次方) 神经细胞(神经元)通过百万亿(10的14次方)突触组成巨大网络(我知道神经元数量是上千亿,没想到突触是百万亿)
大量简单个体行为产生出复杂、不断变化且难以预测的行为模式(这种宏观行为有时叫做涌现),并通过学习和进化 过程产生适应,即改变自身行为以增加生存或成功的机 会。(智能是通过涌现 产生的么?如果可以,那就联结主义的目的就达到了)
目前脉冲神经网络的缺陷
更多地 借鉴了神经元、突触等微观尺度的机制,其在学习方式 上更加接近于无监督学习,计算效能也比深度网络高出 一个量级,但由于网络训练只考虑了两个神经元之间的局部可塑性机制,对介观(如神经元网络连接、皮层结 构)、宏观尺度(如脑区之间的网络连接)的借鉴非常缺乏 ,因此在性能上与 DNN 等模型还存在一定差距。
让机器像人一样不断地从周围环境对知识、模型结构和参数进行学习和自适应进化,是机器学习的最高目标,这种学习方式被称为终生学习(Life-Long Learning)或永不停止的学习(Never-Ending Learning)[53,54],里面混合监督学习、无监督学习、半监督学习、增量学习、迁移学习、多任务学习、交互学习等多种灵活方式。
认知科学认为,一个概念的形成具有组合性和因果性,因此认知一个新概念时用到了已有的经验积累,从而具有个例的举一反三能力。
[27] 类脑(受脑启发的)计算的问题与视觉认知
是 郑南宁 院士做的报告。
我之后的工作应该也是试图从脑网络连接机制及视觉认知的角度探讨类脑计算可能的实现途径和方法
目前深度学习模型的缺点:
对训练数据过度依赖,大多采用前馈连接,缺乏逻辑推理和对因果关系的表达能力、缺乏短时记忆和高效的无监督学习能力,很难处理具有复杂时空关联性的任务。 这些问题促使我们去寻求新的计算模式。
寻求类脑计算的物理实现形式,我们需要在物理的、符号的、语义的三个层面上弄清楚如下两者之间的 关系,即:计算装置与计算过程之间的关系,大脑与认知之间的关系。
图灵机的局限(判符号主义死刑)
图灵机模型表明,存在一种普适的计算机制,它可以完成任何可用形式化方式描述的计算任务(只要这个问题可以用形式化表达,那么这个任务就可以用图灵机完成,因此问题的关键在于脑认知机制能否被形式化),而且图灵测试的可能性是建立在符号系统所具有的可塑性的基础之上。计算形式的普适性使得冯诺依曼结构的现代计算机可以完成图灵机表征 的任何过程,但前提是能将人类或其他生物的认知行为抽象出诸如:规则、推理、推论、归纳等这样的语义规律性,并把它们看作是关于符号的计算。(这就是符号学派背后的逻辑)然而,人类的大脑具有感知、识别、学习、联想、记忆 和推理等功能,并不能全部用符号计算的形式来实现(这不就从根本上判了符号主义死刑了么)。这些功能与大脑的结构存在着对应关系,并且大脑的神经网络系统具有多层的反馈机制,如来自于高级 “控制” 脑区到初级视觉脑区的反馈信号,形成了基于内容和语义的视觉 “选择性注意” 机制。
类脑计算就是受上述脑功能和脑神经网络连接机制启发的一种计算架构,它以神经形态计算的模式来部分模拟大脑功能与其结构的对应关系和反馈连接, 增强人工智能及其计算效率,不完全依赖现有冯诺依曼计算结构,也不是复制人类的大脑或简单地建造一种模拟神经元功能的芯片,更不是去完全替代冯诺依曼计算结构。
大脑认知的层次
人类大脑认知活动分为三个不同层次:
- 直觉
- 形象思维和逻辑思维
- 灵感与顿悟
其中形象思维和逻辑思维是在人的意识控制之下进行的,而直觉、灵感与顿悟则是一种潜意识活动,是大脑的自主信息处理功能的具体表现。直觉、灵感与顿悟是人类在发明创造的过程中经常表现出来的认知活动。
直觉是以知识经验为基础,跳跃地、直接抽象地识别事物的本质,直觉判断往往是为了迅速解决当前的问题,而灵感则是在某种偶然因素的启发下使问题得以顿悟。然而,人工智能的很多研究工作主要集中在完整信息(结构化或半结构化)的处理,用特征学习和定量计算的模式来实现大脑认知的 “形象思维和逻辑思维”(现在的人工智能研究其实都是为了实现大脑认知的形象思维和逻辑思维),将深度学习与概率网络结合,也可在一定程度上对完整信息进行直觉判断,而对于实现非完整信息的直觉判断还无能为力。
传统人工智能的局限性
- 需要对问题给出形式化描述(即抽象出一个可解析的数学模型,如果抽象不出,即归纳为不可解问题);
- 需要对形式化描述设计确定的算法(容易产生 NPC 类问题)
- 处理的结果无法表示现实世界问题所存在的测不准性和不完备性
- 图灵意义下的可计算问题都是可递归的(“可递归的” 都是有序的)
- 用 “度量” 来区分模式、只能处理可向量化的数据
传统人工智能的基本理论框架建立在 “思维即计算” 的理论基点上,以 “演绎逻辑和语义描述” 和 “形式化方法” 实现计算。将 “思维” 抽象为 “符号计算”(像low-rank、机器学习的模型这些可以认为是将思维抽象成数学符号计算吗?)对人工智能的发展产生了重大的推动作用,但为所有的对象建立模型是不可能的,也未必是完备的。这里存在条件问题(Qualification Problem)和分支问题 (Ramification Problem),即不可能枚举出一个行为的所有先决条件,也不可能枚举出一个行为的所有分支。而大脑的认知具有多种方式,如对环境的理解、非完整信息的处理、复杂时空关联的任务,还有最基本的形象思维,特别是人脑在非认知因素和认知功能之间的相互作用,它们是形式系统难以,甚至不能描述的。
人类能够为未来做出计划、可以灵活处理问题并且向他人学习,这些是人类智能的基本属性。而传统人工智能方法,无法实现类似人一样思考推理的机器,去深度解决自然场景描述和环境理解等知识推理问题,也难以完成许多对于人类大脑来讲轻而易举的一些任务。因此,人们期望借鉴大脑的工作原理发展出一种新的智能机器的架构或称之为强人工智能的计算理论和方法。(自然场景描述和环境理解 属于 知识推理问题,这里面既要有知识,又要有推理的成分)
冯诺依曼计算架构的面临的困境
冯 ̇诺依曼架构的计算机可以实现任何可用形式化方法描述的计算任务。(关键在于问题能否被形式化定义),但我们面临的计算任务并不都是可用形式化方法来描述的。(那不用形式化定义,用什么来定义呢?)
冯 ̇诺依曼计算架构主要是由于分离的运算和存储结构(总线传输瓶颈)、以及有限的并行度(指令级、数据级、线程和任务级)(人脑是高度并行的)、有限的容错和鲁棒性,特别是功耗问题。
大脑网络连接与认知的关系
类脑计算的最根本的挑战是人类大脑信息处理和认知功能的复杂性(所以机制上是很复杂的咯?那这个符合“涌现”的定义吗?)。
大脑是由多个不同区域的脑组织连接而成的网络达成共识,其中各个脑组织区域负责不同的认知任务。层次化、多尺度、高度连通、多中央枢纽的网络拓扑结构,决定着大脑任务相关以及自发的活动。
通过发掘大脑结构连接(structural connectivity)、功能连接(functional connectivity)和有效连接(effective connectivity)的聚合和分离(敛散性)来洞察大脑的认知机理 (图 4)。其中,大脑的结构连接是相对静态的,而功能连接和有效连接具有时、空动态演化的特性, 具体表现在连接强度变化以及神经脉冲信号的时序关系变化上。(神经网络的连接强度是个什么东西?就是神经网络的权重,所以在脑中突触连接的权重是在动态变化的,但目前的神经网络一旦学好,权重都是固定的)
大脑的结构连接
通过对猫科动物和猕猴的大脑皮层解剖发现,大脑的结构网络具有 “Small world” 的特性。大脑连接的形成方式和连接长度受限于生物材料和能量代谢的约束,形成了占大量比重的短距离连接(低成本)以及丰富的中央枢纽结构(适应性)。(这个短距离连接就是 CNN 用卷积来建模背后的机理吧,这个中央枢纽结构是啥?)
大脑的功能连接
大脑皮层的功能连接常用来分析识别大脑特定的任务和功能(Task-Specific)
功能连接是和特定的任务相关联的,例如:通过对脸盲症患者的实验发现,人眼看到运动的人物时,大脑是通过两条不同的神经传输路径分别来提取人物身份和判断运动位姿(功能连接)(两条不同的神经传输路径,这个已经在很多论文里提到了)
高级的认知任务中则表现出了较多的模块间的互连度
在大脑处理新任务时,位于额顶叶中的中央枢纽灵活地在各个专门任务处理区域间进行多项快速的连接切换,中央枢纽网络的存在使得人可以处理新的认知任务,并增强人的学习能力和适应性
大脑的功能与其结构存在着对应关系。这种关系有别于基于符号和概率的知识表达,大脑通过复杂的时、空动态演化的网络系统来完成信息的判断和推理。对于这样一种可塑的、动态的非线性关系网络, 目前,我们无法使用形式化的方法进行完整描述,更无法简单地利用传统的基于数值的计算模型来实现。(动态的非线性,难怪混沌、复杂网络会跟神经网络扯到一起去)
大脑的记忆
大脑首先从感知觉系统的外部或者内部感受器中收集内外部的信息,然后利用神经系统中记忆的知识对收集的信息进行解释和判断(解释和判断必须要依赖记忆,更好地建模记忆才能够更好的构建场景理解的模型)。
由于信号不可避免的带有噪声,而且通常观察也是不完全的,因此,在神经系统的各个水平上都必须借助记忆完成对接受的信号的修正和完整化(记忆能够帮助修正和补全不完全观测,这对于目标检测、识别、跟踪里面的遮挡、噪声等问题可以很好的解决途径)。
同样的,为了形成适应性的行为决策,神经系统必须能够对环境变化的 “历史” 形成内部模型,这个作为决策依据的模型也是由记忆提供的。
机械记忆和生物记忆是两类主要的记忆形式,分别以计算机中对于数据的存储和高等动物脑中的记忆为代表,不同于机械记忆,生物记忆有如下几个特点:
首先,生物记忆的介质是生物神经系统,神经元是神经系统的基本组成单位。神经生物学实验表明,神经系统主要通过改变多个神经元之间的突触联接强度而记忆信息,并通过多个相关神经元状态的集体变 化表示不同的信息。因此,生物记忆的第一个特点是分布式记忆,这与现代计算机利用一个或几个相邻 字节表示一个单位信息的所谓局部性方式有很大不同。(意思是神经系统的记忆也是在突触连接强度上,那神经网络学到的知识也是在权重上,不就一样了么。说神经网络是黑箱没有可解释性,那问题来了,人脑有可解释性吗?)
其次,在生物记忆的回忆过程中,输入的信息与回忆出来的信息必定有某种关联,或者前者是后者的一部分,或者两者在内容上相似或有联系(如正好相反),或者两者在环境中同时出现(即空间相关)或 相继出现(即时间相关)。早在两千多年前,亚里士多德就提出记忆的输入信息和回忆出的信息之间具有关联性,他把这种现象总结为联想律(Principle of Association)。因此,人们通常把人类或高等动物 的记忆称为联想记忆。输入信息与读取信息的关联性是生物记忆的重要特点,而在计算机中,信息在介质中存储具有确定的地址。(一个是某种关联,计算机是就是等同,这点对我们构建算法会有什么启示?想不到诶)
生物记忆的第三个特点是动态性,在人类的联想记忆中,不只是由一个输入项联想出一个相关联的记忆项,人们能够记忆和回忆一个结构化的序列,人的回忆是一个具有丰富动态特点的过程。形成鲜明对比是,计算机利用一个地址读取一个信息,是一种机械单调的过程。(回忆其实就是一个重建的过程,而不是简单的读取)
在生物神经系统中,记忆与信息的处理过程是缠绕在一起的,不像计算机系统那样,信息存取的过程与计算过程是相对分离的
神经记忆的特征
- 分布式表达和存储
- 输入信息与检索记忆在内容上具有关联性
- 存储和记忆检索具有动态性
- 记忆与信息处理过程紧密结合
我对类脑智能感兴趣,主要是我想通过借鉴 在复杂的认知行为中,大脑功能网络如何有效的合作、竞争以及协调工作的,从而来指导我对于场景理解算法的构建。
人脑强悍的计算能力
类脑计算需要完成高性能计算到高智能计算的进阶,计算能力的度量由每秒完成的浮点数操作 (Floating-point Operations Per Second,FLOPS)变化为每秒完成的突触操作(Synaptic Operations Per Second,SOPS)。人类大脑约有 10^11 的神经元,其中每个神经元有约 10^4 的突触连接,如果以 10Hz 的速度释放神经脉冲,其计算量约为 10^16 次突触操作(SOPS),假设每次神经脉冲操作需要 10^2 次数值计算,则共需要具有 10^18 (Quintillion,百亿亿)次运算能力的高性能计算机(High Performance Computer,HPC)才能匹配整个大脑突触操作的次数。目前最快的高性能计算机天河 - 2 的计算能力为 33.86~54.90 PFLOPS(one quadrillion floating point operations per second,每秒千万亿,10^15)。而具有 10^18 浮点计算能力的机器预期在 2019-2023 年才能出现。(也就是说 10^15 到 10^18 还差三个数量级。)
10^3,Thousand,千
10^6,Million,百万
10^9,Billion,十亿
10^12,Trillion,万亿
10^15,Quadrillion,千万亿
10^18,Quintillion,百亿亿
三种类脑(受脑启发的)认知计算模型
(1)基于生物学的脑认知网络计算模型(图 5a),代表性的工作有瑞士联邦理工的马克哈姆教授发起 的欧盟 HBP 项目;
(2)基于数据驱动的脑认知计算模型(图 5b),设计各种巧妙的激励测试实验,通过如核磁共振、脑 电图等神经成像技术获得有限的实验数据,并对测量数据加以分析归纳;
(3)基于数学和人工神经网络的脑认知计算模型(5c),使用数学分析和计算机模拟的方法对生物实 验观察数据和测试结果进行研究,提出大脑信息加工的生物学假设、提炼出相应的数学和计算模型,发 展出了相应的计算神经理论和计算方法。
这块我没看懂,不知道 数据驱动 与 数学和人工神经网络 有什么区别?
已有类脑计算架构设计者大多是来自计算机相关专业的专家和学者,往往受人工智能神经网络设计思路的影响,集中在寻找合适的特征来描述外部世界的复杂性和不变性,而忽略了从神经网络内部信息表达模态不变性的角度分析和设计类脑计算系统的研究方法。
视觉计算
视觉信息中存在着大量的无关甚至使人误解的偏差,并且视觉信息数据本身不会显现出相应的相关性和不变性
用机器来求解视觉场景理解的问题时,需要回答:在物理学和光学的基础上,对感知的景物图像必须完成哪些处理?如何表示和利用客观世界模型、知识以及选择性注意机制?
选择人类视觉处理机制的典型应用为出发点和突破口,尝试构建类似大脑的视觉信息处理模型及架构(我想做的点),对促进类脑计算的深入研究具有重要的指导意义。
作者在从事计算机视觉的研究工作中,始终思考着这样一个问题: 怎样利用知识,将大脑的某些视觉感知功能赋予机器,即:
- 如何实现初级视觉中不同层次和水平的自然衔接,使视觉系统自动将信息组织成具有连续性的结构?
- 认知的基本单元是什么?是否存在统一的方式处理不同视觉模块灰度、纹理、形状、颜色、表面深度和运动的组织信息?
- 选择性注意力机制是怎样在大脑的初级视觉信息处理中产生作用的?
- 如何将这个组织原则映射到物理可实现的高度并行的 “类脑” 计算结构中?
视觉认知计算可以作为类脑计算的一个突破点(由此可以看到,视觉认知计算是 类脑计算下面的一个子领域,目的在于解决视觉问题)
信号经由感受器(视杆和视锥细胞)-> 双极细胞(第一级神经元)-> 节细胞(第二级神经元)-> 视神经 -> 视交叉 -> 视束 -> 外侧膝状体 (第三级神经元)-> 视辐射 -> 内囊枕部 -> 枕叶视区的传导途径到达大脑皮层,形成视觉
研究计算视觉,我们必须知晓: 视觉不是孤立地起作用,而是复杂的行为系统的一部分;其次,视觉计算是动 态的,通常并不需要一次将所有的问题都计算清楚,而是对所需要的信息加以计算(Attention);第三,视觉计算应该是自适应的,视觉系统的特性应该随着与外界的交互而变化。同时,初级视觉中的全局和局部感知同样存在着交互行为,小尺度和大尺度感知是并行的、相互作用的(局部和全局是有交互且相互作用的,小尺度和大尺度也是并行且相互作用的,关键就在于怎么建模这种相互作用)。生物视觉具有小范围竞争、大范围协作的特点
视觉交互行为与注意力集中
视觉认知过程不只是被动地对环境的响应,同时也是一种主动行为: 人们在环境信息的刺激下,通过眼动、走动,改变观察点,从动态的信息流中抽取不变性,在交互作用下产生知觉 (主动视觉系统)。人脑在视觉认知过程中存在自下而上和自上而下的双向信息处理通道。生物视觉通道使用自下而上的传递过程(200ms-300ms)对视觉对象形成初步认知结果(100 步法则)。通过自上而下的反向传递控制眼球的注意力,完成预测 - 验证的认知过程。人具有从复杂环境中搜索特定目标,并对目标信息进行选择处理的能力。这种搜索与选择的过程被称为注意力集中(Focus attention)。比如,大脑通过控制 眼球的肌肉,完成注意区域的聚焦,在眼动过程中的信息则是被忽略的。人们对于注视点周围的物体可 以精确地反应出其颜色、形状、深度信息,而对于处于视野边缘的物体,则很难分辨清楚它的颜色、形状和距离。这就是信息表达的不完整性。选择注意机制可分为独立于内容和语义的初级(Low-level)注意系统和基于内容和语义的高级(High-level)注意系统两个层次。
深度学习的问题
- 缺乏理论支持(如:面向不同复杂度的任务需要设计多少隐层?如何消除海量存在的冗余参数?何种网络连接为最优结构?)。因此其很难对效果超群的深度学习算法在具体问题上给出恰当的理论解释。
- 大规模神经网络容易过拟合数据,只有采集到充分大的标注且数据维度足够高时,有了大数据样本 才能缓解复杂模型的过度学习。因此深度学习性能依赖于海量的学习样本以及样本的质量,在小样本数据下无法获得有效的知识(概念)。
- 目前的深度学习方法,还是停留在统计学习和复杂模式识别与分类层面上,比起人的学习能力还有很多局限。比如,人的举一反三、触类旁通、无师自通所展现出的知识迁移的学习能力是现有统计学习所远远不能达到的。(这是统计学习的缺陷,不光是深度学习的缺陷)
深度模型与知识的融合,外部记忆的增强,深度学习与贝叶斯学习推理的结合应该是其未来的研究方向。
视觉认知中的深度学习层次结构
我就需要这一小节的内容来指导工作,这是个典型范例。
在视觉认知计算中,对深度学习层级结构的理解要避免走入一个误区:层级结构最顶层的输出是认知编码的目的。 实际上人对视觉刺激的认知编码的结果是整个层级结构,而不只是层级结构最顶层的输出(这个不就是 skip-layer 动机么)。 目前的深度学习和计算z机视觉只需要识别出图像中的对象,这种认知是面向对象的。人脑不仅能识别出输入图像中的对象,还能在一定程度上识别出构成这些场景和对象的细节(虽然不是像素级的细节)。 也就是说,在大脑层级编码模型中,底层的作用不仅是为了最终得到最顶层,而每一层本身就是对图像的部分编码。
另外,一种观点认为高级视觉认知就是对象认知,这种理解容易对视觉认知机制产生混淆和误导。比如 啮齿动物,它们并不需要识别出什么是建筑、什么是草坪、什么是公路,它们的高级视觉认知主要在于 复杂环境中的导航,比如快速识别出哪里可以逃跑,哪里存在障碍等 [27]。人脑认为草坪和道路作为两 个对象,其界线非常明显,而啮齿动物的高级视觉认知可能并不会对视觉场景做这样的划分。因此,构 造一个能很好的识别 “对象” 的算法只是解决 “眼前” 的问题。但是,对象识别只是人脑适应环境的结果, 仍然不是最根本的视觉认知机制。
现有视觉计算架构的局限
在初级特 征获取之前,大量未加工的、冗余的数据需要进行传输或者计算,从而消耗了大量的通讯带宽和计算资源。(这就是老大那篇 Paper 和 后续基金的 Motivation)
脑启发的视觉处理计算架构
视觉通道特别是视网膜的信息处理能力、大脑神经连接的网络化结构以及联想记忆启发我们设计和研究 新型的视觉计算模型和处理架构。这种架构的组成单元有:从帧驱动到事件驱动的信息获取单元(智能计算前移)、注意力选择 / 事件驱动的信息获取方式、时空动态的信息编码、网络化分布式的动态信息处理、结合长时和短时记忆功能的网络结构,以及条件要素的约束和引导的有效控制。实现大脑结构网 络、功能网络和有效网络在视觉处理架构不同层次的映射。
学习和记忆的基本过程是:信息获取、选择、巩固和再现。信息获 取是感知器官向大脑输入信号的阶段,注意力在信息的获取阶段影响很大。选择和巩固是信息在脑内进 行简单处理、决定是否需要保持和进一步强化形成长时记忆的阶段,其巩固程度和信息对于个体的意义 以及是否重复出现有关(增加曝光度会增加熟悉度和确定性,但不清楚是否影响记忆)。再现也即回 忆,是将脑中存储的长时记忆信息提取再现于意识,从而利用经验知识信息完成高层次的信息加工处理 的过程。
[28] 机载激光雷达技术在长江三峡工程库区滑坡灾害调查和监测中的应用研究
里面给了用 LiDAR 的一个案例,具体是给定了 3 个点,计算这 3 个点在东西、南北方向上的距离,比较在前后两次测量时的距离,这个案例中这三个点,在南北方向上的距离的变化很小,但东西方向上的距离变化很大。 在这个案例中,可以看到是用特征点的分布(互相之间的距离)变化来检测滑坡的。
[29] 基于地面 LiDAR 的滑坡地表整体变形监测
目前,对于滑坡体的变形监测已有多种方式和手段。最多见的是在滑坡体关键部位布设人工监测点构成监测网,采用全站仪或 GPS 获取监测点的坐标值。 这样的方法能够得到精确的点位坐标,能够灵敏地捕捉到点位的变化信息,获取水平位移、垂直位移及变化速率。
为什么要做点云匹配?
采集点云数据的时候,往往由于单幅数据无法覆盖整个区域,需要进行多次扫描或设置多个扫描测站得到多幅 点云数据。每次扫描基于不同的坐标系统,为了完整地重构地表形状,需将所有基于不同视角获取的点云转换至统一的坐标系下,这个过程就称为点云配准。
点云配准包括两个步骤: 对包含重叠区域的两幅点云采用两视配准的方法在重叠区域选取3至5对同名点进行初步配准; 采用最近邻点迭代算法(Iterative Closest Points, ICP)进行精确配准, 通过迭代获得均方差最小的最优化配准结果。(这是对同一期有重叠但不同区域的匹配)
对于多期的点云模型进行比对时,选取数据采集时多余观测测的稳定区域作为坐标基准(这个怎么选?怎么知道哪些是 稳定区域?),采用点云配准的方法使用多期稳定区域间的空间变换关系将多期点云统一到同一坐标系,无需额外设置固定扫描站。
[30] SuperPoint: Self-Supervised Interest Point Detection and Description
这是我看的第一篇特征点检测的文章…
这篇文章是 Magic Leap 的。
Motivation
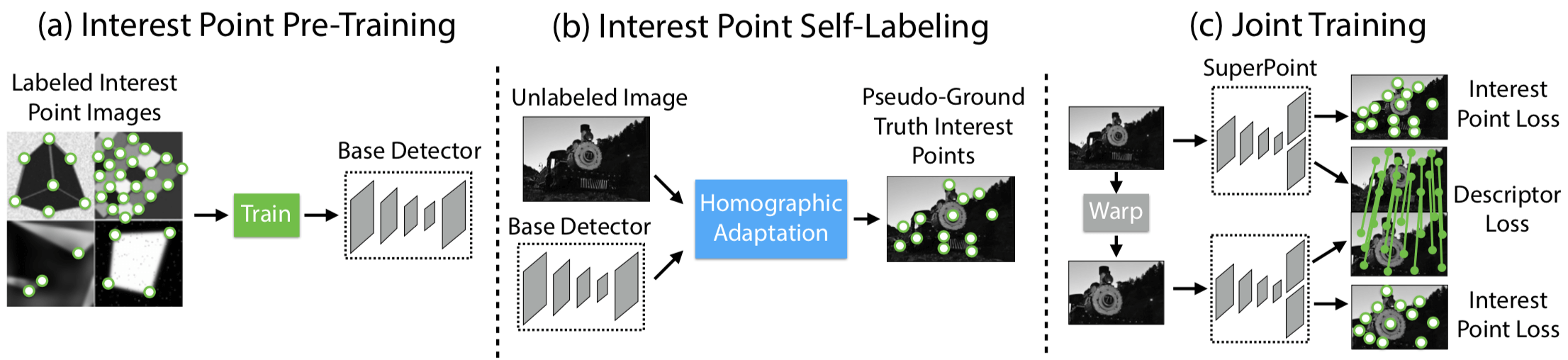
文章的主要贡献给出了一种不需要 human annotation,以 Self-Supervised 训练的 fully-convolutional CNN 来同时学 interest point detectors and descriptors。
Self-Supervised 是以 From Simple to Complex 的方式实现的,之所以这么做,在于作者相信能够 transfer knowledge from a synthetic dataset onto real-world images,具体步骤如下图所示:
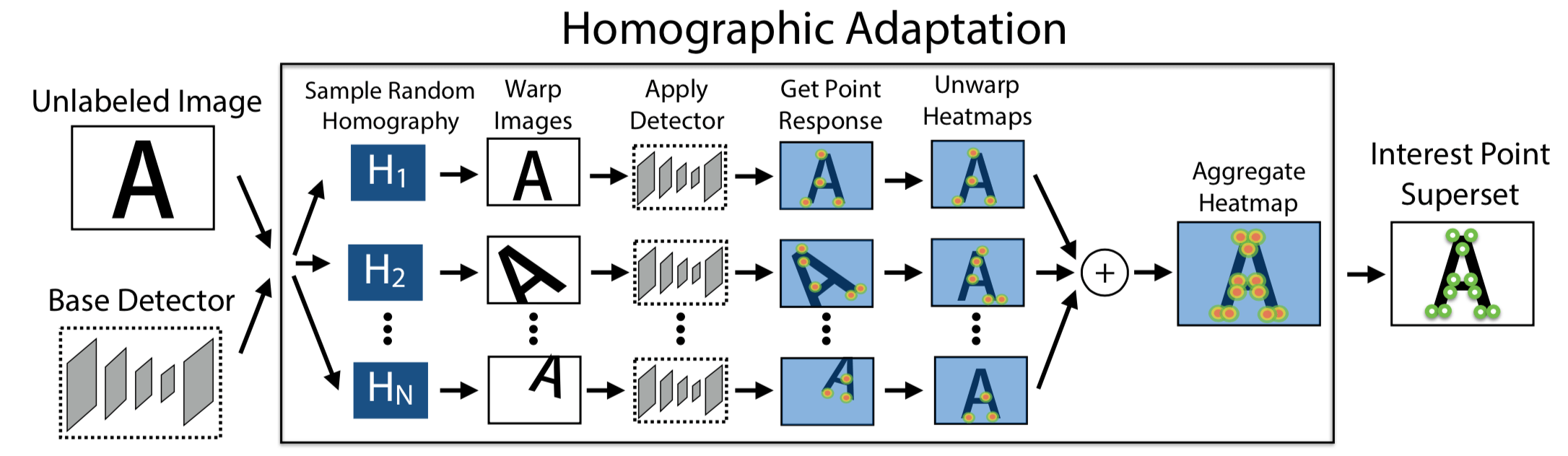
- 首先是 pre-train an initial interest point detector on synthetic data(这是 From Simple to Complex 的 Simple 阶段),这个阶段得到的 Detector 叫作 MagicPoint;MagicPoint 在 synthetic data 上表现比传统的特征点检测子要来得好,但对于 real images,相比于经典检测子还是会 misses many potential interest point locations. 后面这个能力会通过 Homographic Adaptation 这个 multi-scale, multi-transform technique 来补全(意思就是说作者认为,synthetic data 相比于 real images,缺少 multi-scale, multi-transform,所以 MagicPoint 缺的是在 multi-scale, multi-transform 下的鲁棒性?)
- 第二步是 Interest Point Self-Labeling,现在 unlabeled image(这是 real images,不是 synthetic data,这是 From Simple to Complex 的 Complex 阶段)上检测出特征点,然后再运用 Homographic Adaptation,就可以得到单应性变换后的特征点。Homographic Adaptation 的核心在于 刻画 repeatability,最后 detectors and descriptors 的 loss 其实惩罚的就是在 repeatability 上表现不好的,而非检测的特征点与 Human Annotated 特征点之间的 Loss。也就是说,之所以能够 Self-Supervised,在于 Loss 由刻画 Prediction 与 Groundtruth 之间的差距,变成了刻画 Prediction 在 Homographic Adaptation 下的 repeatability,也就是 Homographic Adaptation 前后的差距。
- 最后就是 Joint Training,根据 Loss Function 用 ADAM 优化即可,在优化 Detector 的同时 Description 也学了,Description 就是 CNN 最后的特征表示。
Model
网络结构就是 VGG 的,但因为 SuperPoint 是同时做 interest point detection 和 interest point description,这两个 task 是同时的,共同 share 一部分 computation(传统方式是先做 point Detection,完后了再做 point description),SuperPoint 之所以可以说是同时做,是因为它 Detection 和 description 两个 sub-network 的输出都是 W * H,也就是输入大小,所以 SuperPoint 是做了一个 Dense Output。
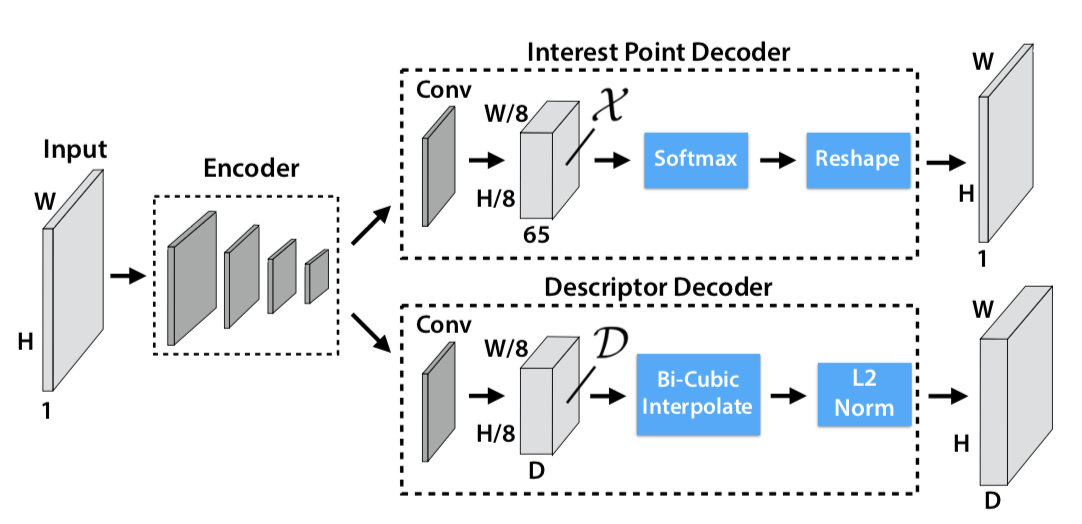
upsampling 没有学习,直接用的插值
对于 Interest Point Decoder,Softmax 之前的特征的尺寸是 $H { c } \times W { c } \times 65$,65 是因为 8 8 下采样一个 Cell 里面对应原来 64 个 Pixel,再加上一个额外的 “no interest point” dustbin,一共 65 个。原图是 W H,现在变成了 W/8 H/8 64,所以变成 W * H 的大小只要 reshape 就可以了
在 Training 阶段,Homographies 是被用来作为提高模型 repeatability 的约束条件 / Loss 来用;在 Test 阶段,Homographies 被拿来当做集成学习多个弱分类器组合成强分类器那样的味道来做,只不过这个组合方式是简单的对在做了单应性变换后检测出来的特征点再反变换回原图的结果的相加,具体公式如下
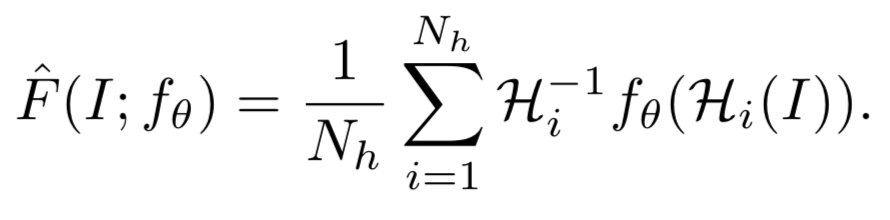
图像表示如下
Loss
注意,Loss 是建立在 $H { c } \times W { c }$ 的 Feature map (8 * 8 下采样)上,而不是在最后跟原图一样大小的 Output 的。
总的 Loss Function 如下:
$$
\begin{array} { l } { \mathcal { L } \left( \mathcal { X } , \mathcal { X } ^ { \prime } , \mathcal { D } , \mathcal { D } ^ { \prime } ; Y , Y ^ { \prime } , S \right) = } \ { \mathcal { L } { p } ( \mathcal { X } , Y ) + \mathcal { L } { p } \left( \mathcal { X } ^ { \prime } , Y ^ { \prime } \right) + \lambda \mathcal { L } _ { d } \left( \mathcal { D } , \mathcal { D } ^ { \prime } , S \right) } \end{array}
$$
interest point detector loss
interest point detector loss 具体如下
$$
\mathcal { L } { p } ( \mathcal { X } , Y ) = \frac { 1 } { H { c } W { c } } \sum { h = 1 \atop w = 1 } ^ { H { c } , W { c } } l { p } \left( \mathbf { x } { h w } ; y _ { h w } \right)
$$
其中
$$
l { p } \left( \mathbf { x } { h w } ; y \right) = - \log \left( \frac { \exp \left( \mathbf { x } { h w y } \right) } { \sum { k = 1 } ^ { 65 } \exp \left( \mathbf { x } _ { h w k } \right) } \right)
$$
Y 就是 MagicPoint 在原图上检测出的兴趣点,作为 pseudo groundtruth interest point,X 则是 SuperPoint 网络的 Detector 在原图上检测出的兴趣点,在第一次迭代的时候,X 和 Y 应该是一样的,因为 MagicPoint 就是没有 descriptor head 的 SuperPoint,但随着 SuperPoint 的迭代优化,X 是会发生变化的。这个时候这个 Loss 会去惩罚跟 Y 不一样的 X,也许 X 检出了更多的点呢,这一点合理吗?
虽然 MagicPoint 会 misses many potential interest point locations,但已经算是 performs surprising well on real images 了。所以 MagicPoint 检出的点作为 pseudo groundtruth,后面由 MagicPoint -> SuperPoint,不再努力检测出更多的点,而是致力于 boost repeatability(检测出尽量多的点 与 检测出的点在 large viewpoint changes 还具有很好的 repeatability 这是两个性质。)
MagicPoint performs reasonably well on real world images 但还不够好,相比于其他经典检测子,但是 Homographic Adaptation 也就是 self-supervised approach for training on real-world images 提高了性能(提高性能不一定非要从减小 Prediction 和 Groundtruth Annotation 的任务中来,也可以是构建其他 Loss,这就是 Self-Supervised 的精髓吧 )
descriptor loss
对于 Description 的 Loss,监督信息是通过 Homographic Adaptation 来实现的,从而完成了的监督学习, 具体计算如下,
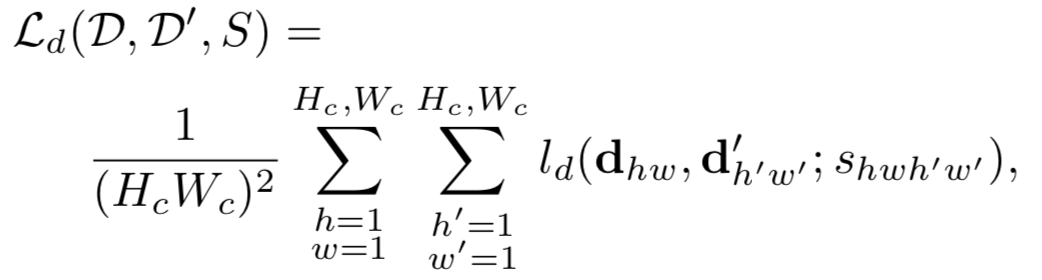
其中 $S$ 是一个指示矩阵,指示第 $hw$ 个 cell 是否与 $h’w’$ 个 cell 是 corresponding 的。怎么判断两者是否 corresponding 依据下面这个公式,原图上的特征点做单应性变换后 与 原图做单应性变换检测出的特征点(先检测后变换,还是先变换后检测的区别),如果一个落在另一个的 邻域内,就算是 corresponding 的。
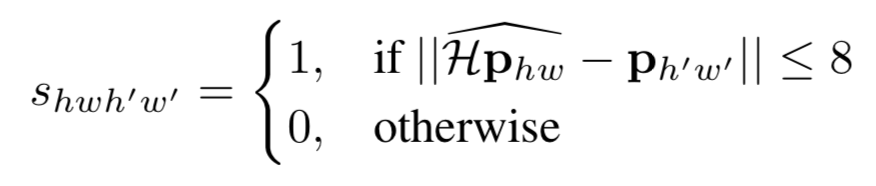
原图上的特征点做单应性变换后 与 原图做单应性变换检测出的特征点如果在完美的检测和单应性变换下应该是一致的,形式化表示如下。上面的公式其实就是把下面等式两边的两项差距小于 8 的都认为满足这个约束,是同一个点。其实下面这个式子是 repeatability 具体的形式化表示。 repeatability 被刻画成了单应性约束。
$$
\mathcal { H } \mathbf { x } = f _ { \theta } ( \mathcal { H } ( I ) )
$$
有了 corresponding 关系后,两者之间的 Loss 就可以如下算出来
$$
\begin{aligned} l { d } \left( \mathbf { d } , \mathbf { d } ^ { \prime } ; s \right) & = \lambda { d } s \max \left( 0 , m { p } - \mathbf { d } ^ { T } \mathbf { d } ^ { \prime } \right) \ & + ( 1 - s ) * \max \left( 0 , \mathbf { d } ^ { T } \mathbf { d } ^ { \prime } - m { n } \right) \end{aligned}
$$
这项 Loss 容易理解。如果 s = 1,则表示这两个点是 corresponding 的,那么就是第一个惩罚项非零,惩罚两者的 Description 不够接近;如果 s = 0,则表示这两点是不 corresponding 的,那么就惩罚第二项,惩罚两者的 Description 接近了。其中,$m_p = 1, m_n = 0.2$
[32] Single-Shot Object Detection with Enriched Semantics
CVPR 2018 的文章。
Motivation
这篇文章的 Motivation 是 SSD 算法对小目标的检测只是利用了浅层的特征,缺少高层语义,如果能让浅层特征能够有更多的语义,就可以改善小目标检测的性能。这篇文章给出了一种做 Semantic Enrichment 的方式。
语义可以简单地看做是数据所对应的现实世界中的事物所代表的概念的含义,以及这些含义之间的关系,是数据在某个领域上的解释和逻辑表示。
这个 Semantic Enrichment 是通过把一个高层语义分割任务最后的 Feature Map 作为 Attention 权重加到 Detection 的 低层特征上去,这种 Semantic Enrichment 具体的操作方式就是 spatial attention mechanism,通过 element-wise multiplication 上 Spatial Attention Weight Map,直接对最底层的 Detection Layer 的 Feature Map(conv4_3)来 suppress or emphasize 用于检测的低层 feature maps。Semantic Enrichment 具体的表现,用 BAM 论文的话来说则是:denoises low-level features such as background texture features at the early stage;focuses on the exact target which is a high-level semantic (Spatial 维度上).
问题在于这个 Attention Map 怎么来的?作者是通过一个 Semantic Segmentation 分支得到的,只不过这里的标注有点粗略,就是把 BBox 里面的所有像素都标注成了那个 BBox 对应的 label。
下图把这种通过 weighted 上 Attention Map 来提高特征语义的思路展示得很清楚,A 是原图;B 应该是低层的 Detection Layer 对应的低层特征,上下两行分别对应的是 狗 对应类别的特征图 和 人 对应类别的特征图,可以看到不管是狗还是人的特征图上,都有大量无关的特征显著存在;C 是两者对应的由 Semantic Segmentation 得来的 Attention weight map;D 就是 B 和 C 做了 element-wise multiplication 之后的结果,可以看到对于每一类的无关特征都被压制的干净了。

Model
文章的整个网络架构如下图所示,由 Detection Module、Segmentation Module 和 Global Activation Module 三部分组成。其实 Detection Module 就是 SSD,Segmentation Module 就是 FCN(用 dilated convolution 的,为了保持大小不变),Global Activation Module 就是 Squeeze-and-Excitation Block。
使用 SE Block 的目的是不仅仅要在 Spatial 维度上 提升有用的特征并抑制对当前任务用处不大的特征,在 Channel 维度上也这么做。因此这篇论文和 BAM 和 CBAM 一样都是同时做了 Spatial 和 Channel Attention 的文章。文章中的说法是用于提高 high level 的 feature map 的语义信息,我理解的提高 feature map 的语义信息的方式还是通过 attention weight 抑制干扰特征来实现的。 SE Block 的思想是在 Channel 维度上解耦,让某些 channel 就对应某些 image class;这篇文章的思想也是如此,只不过是 channel 对应某些 object class。这篇文章里的 SE Block 也就是 global activate module 的作用是学习 channel 和 object class 的关系,以提高效果。
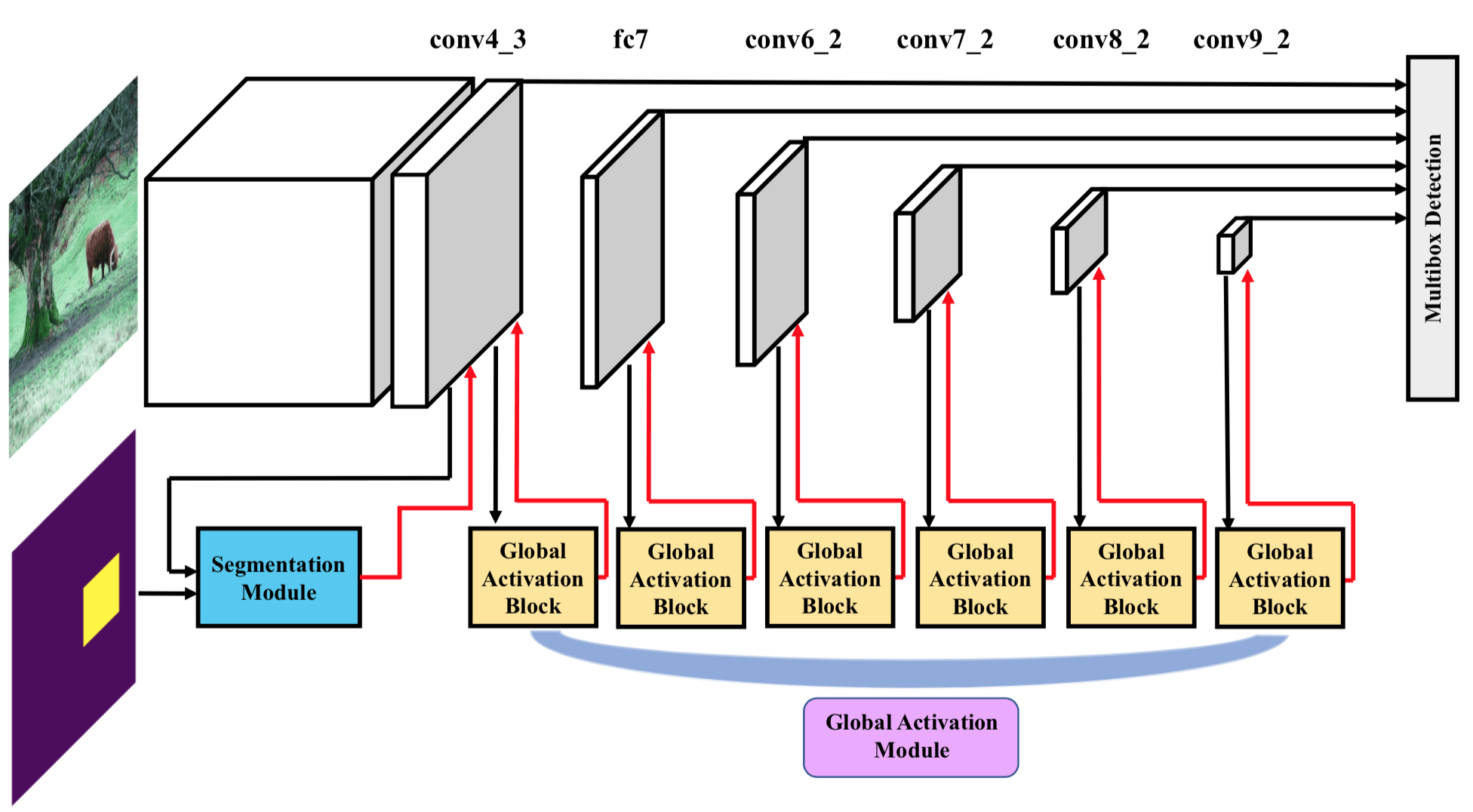
Segmentation branch
需要一提的是,在这篇文章的 Semantic Branch 的 Output 有两个, 这是因为一个 Output 通道数是要等于类别数,这是为了计算 Loss;还有另外一个 Output 是为了生成 Attention Weight,通道数必须和 Detection Branch 的 Feature Maps 通道数一样。
Loss
Loss 就是正常的 Object Detection 和 Semantic Segmentation 的 loss 之和,只不过 Semantic Segmentation 里的 Groundtruth Truth 就是 BBox 的范围,但是计算还是和一般的 Semantic Segmentation 是一样的。
[33] Residual Attention Network for Image Classification
CVPR 2017 的文章,是比较早的一篇 Soft Attention 的工作。
Motivation
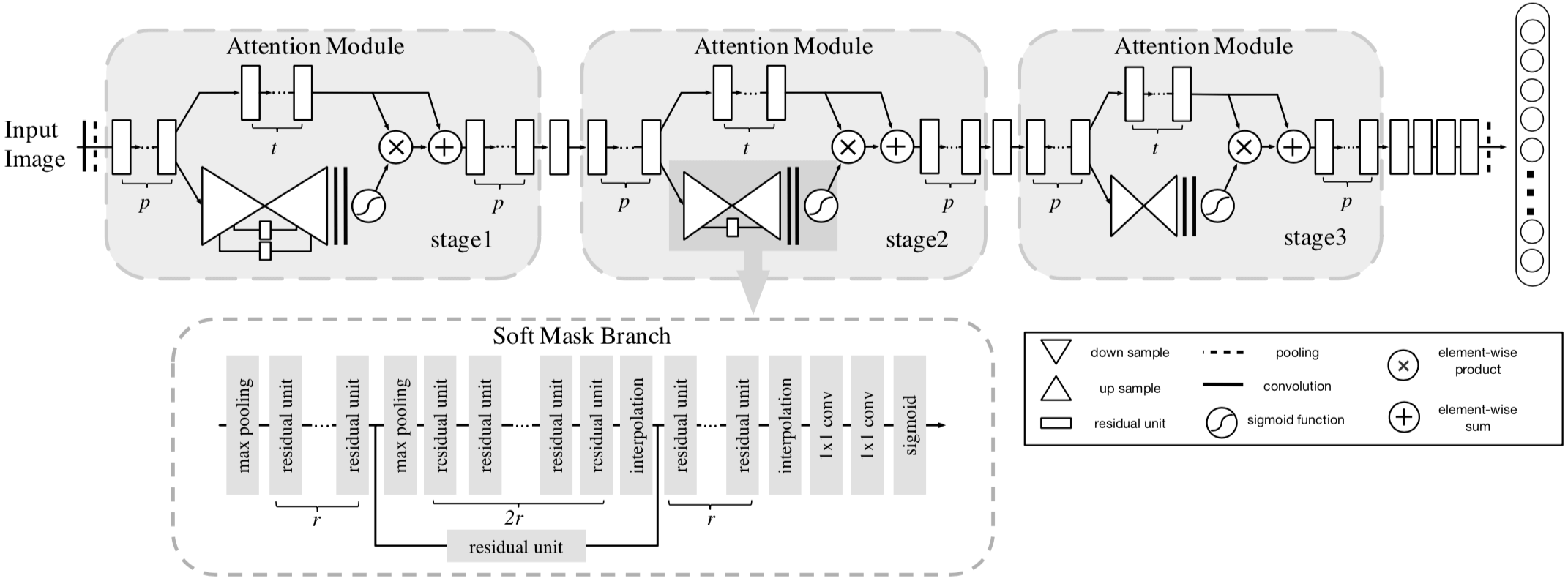
窃以为这篇文章的动机在于 bring more discriminative feature representation by the attention mechanism,具体地说是通过在 feedforward network structure 中 incorporates the soft attention 来 generate attention-aware features。这些 attention-aware features 质量更好,更有利于分类,因为这些特征 enhances different representations of objects at that location。为了实现这个目的,文章中给出了 Attention Module 的方式。但之间堆叠这些 Attention Module 会产生梯度消失问题,网络不能很深。为了解决这个问题,类似于 Residual Block,文章给出了一种 Attention Residual Learning 方式。因此,本文所提出的 Residual Attention Network 其实就是 Attention Module + Attention Residual Learning。
Model
Residual Attention Network = Attention Module + Attention Residual Learning
这篇文章的 Residual Attention Network 的架构如下
Attention Module
Soft Attention 的方式就是学出一个权重分布,再拿这个权重分布施加在相应的特征之上。在目前我看过的 Attention 的论文里,比如 SENet、BAM、CBAM、DES,这个相应的特征就是计算 Attention 权重的输入。这是因为在 SENet 中,Attention Module 只是一个主要特征抽取模块之外 add-on 的模块,起到的作用是改进已经由主要模块抽取的特征的质量;而在本文中,本文的 Attention Module 是要成为像 Residual Block 那样的基础性模块,是用来抽取特征的,只不过抽取的是 attention-aware features 质量更好。因此,本文的 Attention Module = trunk branch + mask branch。 其中,trunk branch 负责往常的特征抽取,可以是 pre-activation Residual Unit, ResNeXt and Inception 中的任一种 state-of-the-art network structure。至于 Soft Mask Branch,如下图所示,是一个 hourglass 结构,encoder-decoder 结构。
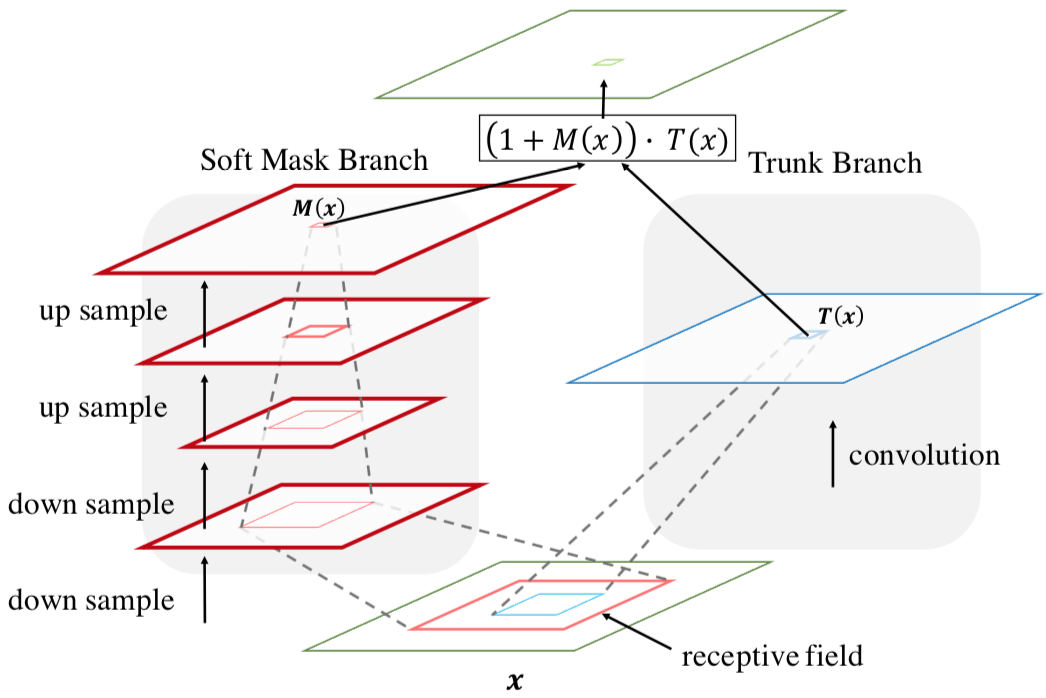
但要注意的是,mask branch 和 trunk branch 的 receptive field 是不同的
Attention Residual Learning
在给定 trunk branch output $T(x)$ 和 mask branch output $M(x)$,通常按照一般的 Soft Attention 的方式,Attention Module $H$ 的输出会是
$$
H { i , c } ( x ) = M { i , c } ( x ) * T _ { i , c } ( x )
$$
$M(x)$ 的作用是 feature selectors,用来 enhance good features and suppress noises from trunk features. 然而,由于 mask 里的权重位于 0-1 之间,多个 Attention Module 堆叠后(网络变深),梯度就会消失,而网络深度加深是获取最后好性能的一大关键。文章给出了一种 attention residual learning 方式来解决这个问题,也就是把 Attention Module $H$ 的输出变成
$$
H _ { i , c } ( x ) = \left( 1 + M ( x ) \right) \cdot T ( x )
$$
注意,此 Residual 非彼 Residual。在 ResNet 中,Residual Learning 是 $H { i , c } ( x ) = x + F { i , c } ( x )$ 这样的。在同样 Soft Attention 的 BAM 和 CBAM 中也采用了 Residual Learning,但它们的 Residual 也是 ResNet 方式的标准的 Residual Learning 的方式,与本文不同。
Spatial Attention and Channel Attention
Attention 说白了就是一个 0 到 1 的权重,最后只要每个点的数值都在 0-1 之内就行,那这个权重具体怎么算出来呢?这就是公式(4)、(5)、(6)了。这三个公式分别对应着,是既对 Spatial 又对 Channel 做 Attention,还是只对 Channel 施加 Attention,后者只对对 Spatial 施加 Attention。
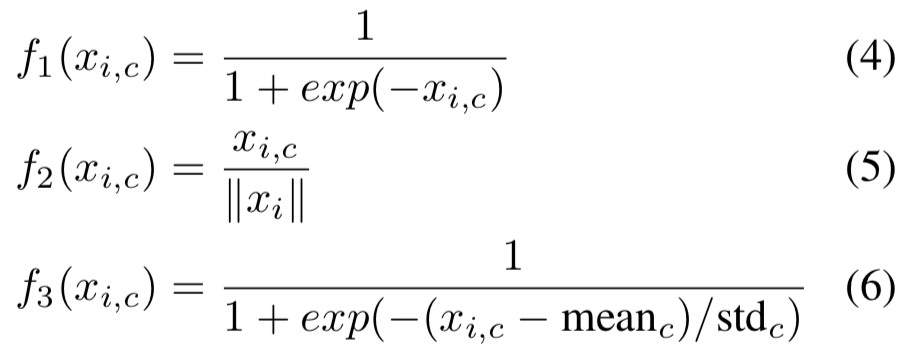
这里有个概念要澄清一下。虽然都叫 Channel Attention,之前在 SENet、BAM、CBAM 中,我们说 Channel Attention 是 Channel-wise Attention,不同 Channel 不同,但同一个 Channel 内的所有 Spatial Position 都是同一个权重;因为做了 Global Average Pooling,这里整个特征的 Channel Attention Weight 是一个 Channel 数的向量。在这篇文章里的 Channel Attention 是说计算某个点(each spatial and channel position )的时候,计算出来的权值仅与该点同个 Channel 上的其他点有关,与 Spatial 点无关;这里整个特征的 Channel Attention Weight 仍然是跟特征向量相同大小的张量,因为没有像 SENet 那样做 Global Average Pooling。
概括一下,在 SENet、BAM、CBAM 中的 Channel Attention 是只有 Channel 维度不一样,Spatial 维度所有点的权重都一样;而本文的 Channel Attention 是只在计算权重也就是归一化的时候考虑了 Channel 维度上的点,而没有考虑 Spatial 权重上的点,因此不同 Spatial 上点的权重还是不同的,因为他们各自 Channel 维度上的向量不同。
例如,公式(5)performs L2 normalization within all channels for each spatial position to remove spatial information. 这个的确是 remove spatial information 了,因为得到的权重只与一个 spatial position 上的所有点之间的相互大小有关,与其他 Spatial Point 无关;但需要一提的是,公式(5)的 channel Attention 得到的还是一个 $H \times W \times C$ 的张量。
最后的效果是 mixed attention,也就是既对 Spatial 又对 Channel 做 Attention 效果最好。这与我们的直觉也是相符的。
Loss
这篇文章没有专门讲 Loss,但既然是分类,一般就是 cross entropy loss 吧。
[34] Semantic Point Detector
ACM Multimedia 2011 的文章。
Motivation
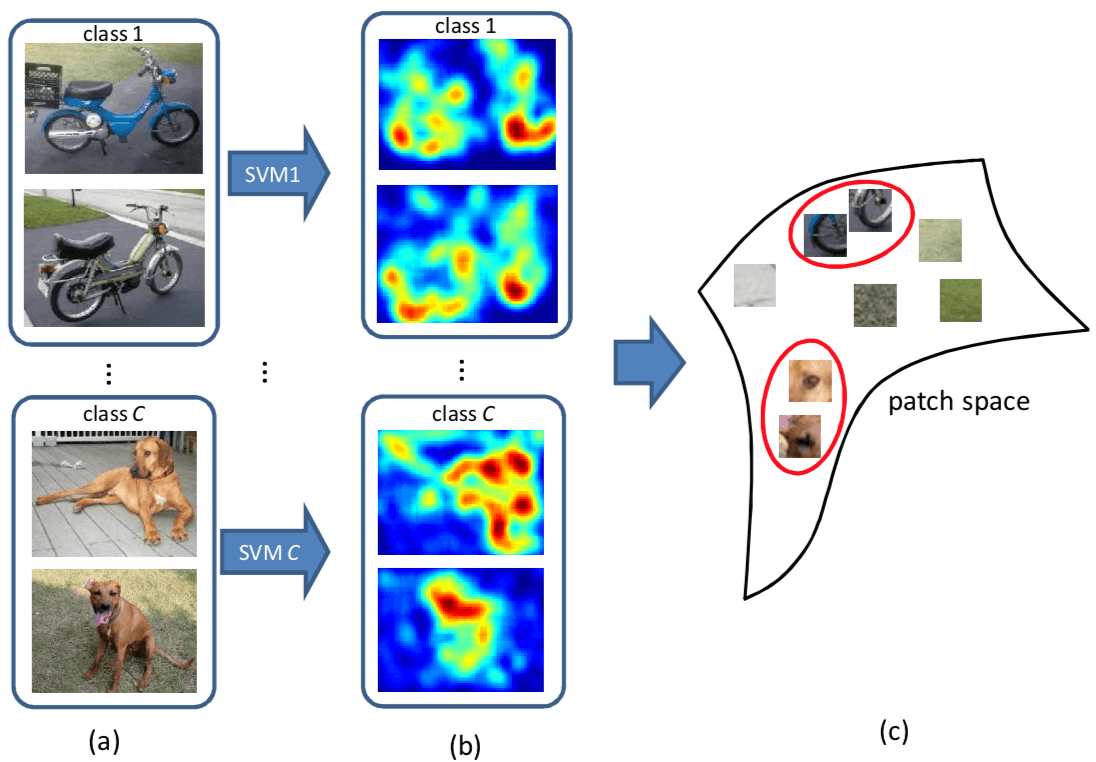
这篇文章的动机在于 local features (Feature point Detection + Feature Description)其实是图像内容的一种表示方式,在深度学习兴起之前的主流范式就是 SIFT 这些特征点检测器 + Bag of Visual Worlds 对局部特征编码 + SVM 分类。但是当前的 interest point detector 主要是为了图像匹配设计的,选取这些特征点的出发点是 invariant under a certain family of transformations,让 the correspondence establishment between images with the same object or scene 足够的robust,而非是针对描述图像内容、揭示语义信息来最优设计的。
这篇文章的 Motivation 就在于 propose a learning-based point detector called semantic point detector which aims to select a set of points that can better represent the image. 通俗地讲,就是 SIFT 这些特征点,会检测出图像中所有的特征点,包括我们不希望被检测出的背景或者其他类别中的特征点,而这篇文章的 semantic point detector 就是希望学习出一个仅会检测感兴趣类别物体上的兴趣点的兴趣点检测器。具体的效果如下图所示,第一排是传统检测子检测出的特征点,大量的特征点位于背景上;第二排是这篇文章的 semantic point detector 检出的,大多数特征点集中在前景目标上。

看到这里,会不由自主地产生一个疑问,单个局部的角点本身,也会具有语义吗?其实一个特征点不仅仅只是这个点本身,尤其是我们对特征点描述的时候,还包括了其周围的区域。具体到本文,与其说本文给出的是一个如其标题所说的 Semantic Point Detector,不如说实际上这篇文章做的是 Semantic Patch Detector。这篇文章具体的做法是将图像转化成 a set of 32x32 patches,步长是 4 个像素。论文中没说怎么在得到 Semantic Patch 后得到 Semantic Point,最直接的方式就是取中心点了。下图是一些 Semantic patches 的示例

既然是 Semantic Point Detector,就要有 label 来赋予 Detector 语义信息。最直接的方式当然有现成的人肉 label 好的 Semantic interest point,但这个太不现实了。这篇文章采用的是一个 Weakly Supervised Learning 的方式。对于每一个类,可以根据是否还有该类物体,构造出相应的 a set of positive images 和 a set of negative images。基于 Background Patch 会在正类和负类中都出现,而 Semantic Patch 只会在正类中出现,以此来完成对于 Semantic Patch Detector 的学习。到这里,可以发现,本文要做的问题,很类似于一个 Weakly Supervised Object Detection 问题,区别在于,Object Detection 的 Object 大小会变动,而本文只要判断固定大小的 Patch 是 Positive 还是 Negative 即可。因此,本文实际上是一个 Weakly Supervised Patch Classification 问题。弱监督则是表现在,需要预测 Patch-level 的 label,但只给了 image-level 的 label。
Weakly Supervised Learning 的核心问题就在于怎么用 Weak label 上的 loss 来改善在具体任务上的 Prediction。这篇文章是怎么建立 Weak Label 和 Accurate Prediction 之间的关系的呢,具体地说,是怎么把 image-level classification 和 patch-level classification 给联系起来的呢?本文是用了两点,第一点是 image representation 是用所有 patch representation 的 linear combination,第二点是采用了 linear SVM 作为分类器。在给定 local patch descriptor $\phi \left( I _ { p } \right)$ 的情况下,image $I$ 的 Representation 就是
$$
\Phi ( I ) = \frac { 1 } { P } \sum { p = 1 } ^ { P } \phi \left( I { p } \right)
$$
由此,图像 $I$ 在 linear SVM 下的 score $f ( I ) = w ^ { T } \Phi ( I )$ 也是所有 patch 在 linear SVM 下的 score 的 linear combination,具体如下式所示
$$
f ( I ) = w ^ { T } \Phi ( I ) = \frac { 1 } { P } \sum { p = 1 } ^ { P } w ^ { T } \phi \left( I { p } \right) = \frac { 1 } { P } \sum { p = 1 } ^ { P } f \left( I { p } \right)
$$
最后 patch-level classifier 的表示就是 $f \left( I { p } \right) = w ^ { T } \phi \left( I { p } \right)$。一言以蔽之,本文如何用 image-level classification 来指导 patch-level classification?本文的做法是,直接拿学到的 image-level classifier 作为 patch-level classifier 来使用,根本不是指导,而是自己亲下火线了。
Model
emmm… 好像 Model 上面说的差不多了,补充些细节。patch representation 用的是 Super-Vector coding,感兴趣的可以看原文的公式(1), (2), (3)。
对于 多类的情况,也很简单,相应的类别就是对应 score 最高的那个。
模型的示意图如下
Loss
Loss 就是正常的 SVM 的 hinge loss 啦,一个典型的正负类分类的 loss。
[35] 图像物体分类与检测算法综述
- 目的上:物体分类要回答的问题是这张图片中是否包含某类物体(我感觉是要回答包含哪类物体);物体检测要回答的问题则是一张图像中在什么位置存在一个什么物体
- 手段上:物体分类算法通过手工特征或者特征学习方法对整个图像进行全局描述,然后使用分类器判断是否存在某类物体;除特征表达外,物体结构是物体检测任务不同于物体分类的最重要之处
- 常用方法:物体分类方法多侧重于学习特征表达,典型的包括词包模型(Bag-of-Words)、深度学习模型;物体检测方法则侧重于结构学习,以形变部件模型为代表
物体分类与检测研究存在的困难与挑战,下图概括的很好
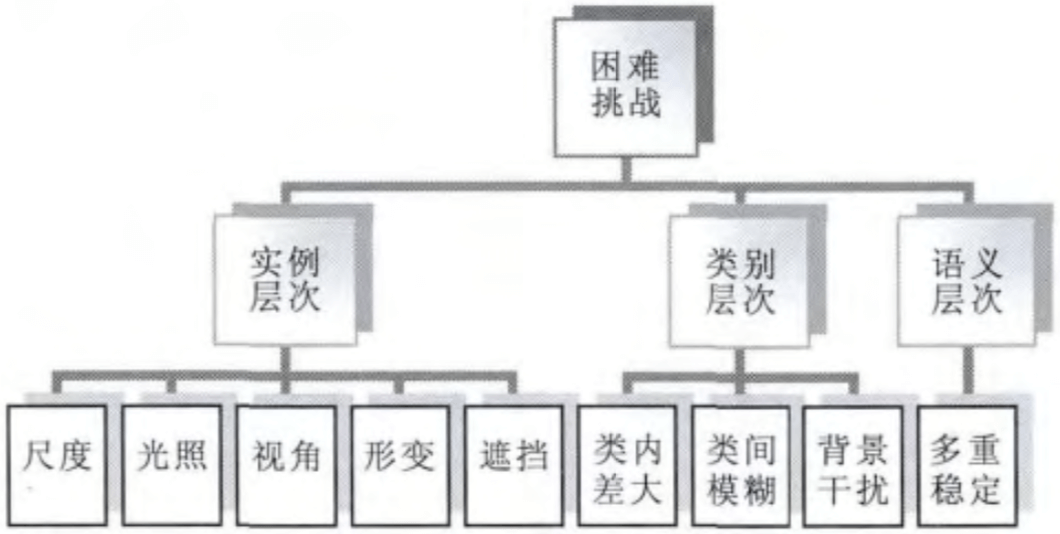
把物体分类与检测研究存在的困难与挑战分为了实例、类别和语义三个层次,这点我以前没有想到可以把难点扩为 3 个层次
- 实例层次
- 光照条件、拍摄视角、距离的不同、物体自身的非刚体形变以及其他物体的部分遮挡,使得物体实例的表观特征产生很大的变化
- 类别层次
- 首先是类内差大,也即属于同一类的物体表观特征差别比较大,其原因有前面提到的各种实例层次的 变化,但这里更强调的是类内不同实例的差别(椅子形状千千万)
- 其次是类间模糊性,即不同类的物体实例具有一定的相似性(哈士奇和狼),特别是物体类别越多导致类间差越小
- 再次是背景的干扰,背景可能是非常复杂的、对我们感兴趣的物体存在干扰的
- 语义层次
- 多重稳定性,也就是图像的二义性(一张图像是年轻女人还是年老女人,是兔子还是鸭子)
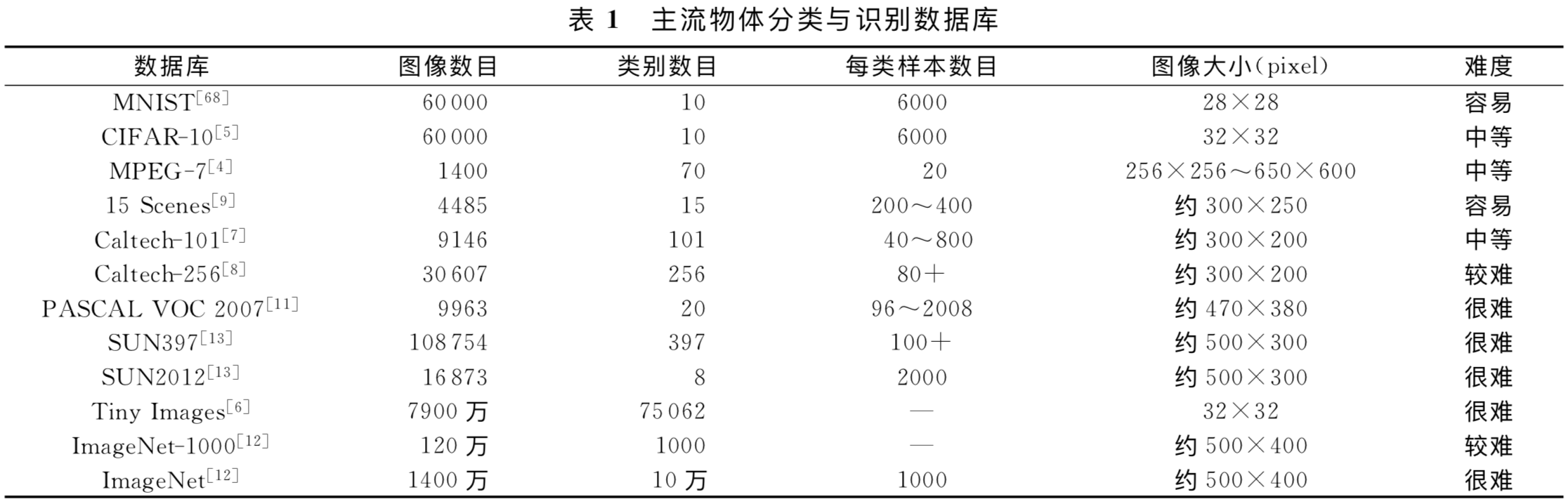
主流物体分类与识别数据库下表概括的很好
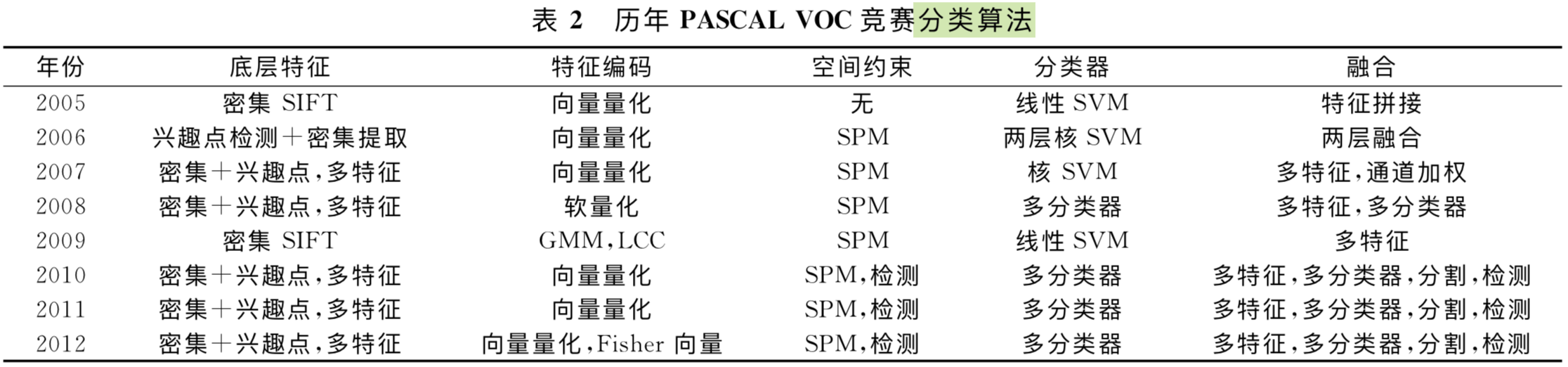
基于词包模型的物体分类
作者这里把基于词包模型的物体分类分为了 底层特征、特征编码、空间约束、分类器设计、模型融合这几个层次,前三个跟 Notes on CVPR-06-Spatial Pyramid Matching 里面总结的 local feature extraction、feature coding 和 feature pooling 三个是一样的,现在看来 feature pooling 叫作 Spatial Feature Pooling 更好一些。
下表对分类算法概括地很好:
Step 1: 底层特征提取
底层特征提取方式有两种:一种 是基于兴趣点检测,另一种是采用密集提取的方式。
兴趣点检测算法通过某种准则选择具有明确定义的、局部纹理特征比较明显的像素点、边缘、角点、区块等,并且通常能够获得一定的几何不变性,从而可以在较小的开销下得到更有意义的表达,最常用的兴趣点检测算子有Haris 角点检测子、FAST 算子、LoG、DoG等.(注意,基于兴趣点检测的底层特征就是 像素点、边缘、角点、区块,这里的 兴趣点 是没有 descriptor 的,特征就是 兴趣点本身,而不是 descriptor)
密集提取的方式,从图像中按固定的步长、尺度提取出大量的局部特征描述,大量的局部描述尽管具有更高的冗余度,但信息更加丰富,后面再使用词包模型进行有效表达后通常可以得到比兴趣点检测更好的性能. 常用的局部特征包括SIFT、HOG、LBP等.(因为密集提取的方式提取的是 局部特征描述,而非仅仅点的位置,所以信息更加丰富)
为什么密集提取方式更好?在底层特征提取阶段,通过提取到大量的冗余特征,最大限度的对图像进行底层描述,防止丢失过多的有用信息,这些底层描述中的冗余信息主要靠后面的特征编码和特征汇聚得到抽象和简并
为啥要特征学习?手工设计的底层特征描述子作为视觉信息处理的第一步,往往会过早地丢失有用的信息,直接从图像像素学习到任务相关的特征描述是比手工特征更为有效的手段
Step 2: 特征编码
这一块基于词包模型的物体分类算法的重点,绝大部分论文都是在这一块做工作。
一个很自然的问题,既然底层特征提取环节已经抽取了特征,直接用于后面的空间特征汇聚不好吗?为什么还要做特征编码?这个编码在编码什么?
论文中的说法是,密集提取的底层特征中包含了大量的冗余与噪声,为提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,从而获得更具区分性、更加鲁棒的特征表达,这一步对物体识别的性能具有至关重要的作用,因而大量的研究工作都集中在寻找更加强大的特征编码方法。
但我觉得,真正的原因在于,底层特征,比如 SIFT, 虽然有 descriptor,但是这些 descriptor 只能用来计算两两相似度的,是无法用于空间特征汇聚环节的汇聚操作的(依据特征的什么性质汇聚?怎么汇聚?)。因此,肯定要有一个特征变换环节,由原来的底层特征变为空间特征汇聚环节能够使用的特征,这个环节就是特征编码环节。而且空间特征汇聚是对于图像分类必须的,因为底层特征提取到的是一个由元素数量不同的集合,不能直接输入需要固定长度向量输入的 SVM。因此,空间特征汇聚不可避免,由此,特征编码也是必须的。
向量量化编码
使用一个较小的特征集合(视觉词 典)来对底层特征进行描述,达到特征压缩的目的
向量量化编码只在最近的视觉单词上响应为1,因而又称为硬量化编码、硬投票编码,这意味着向量量化编码只能对局部特征进行很粗糙的重构
软量化编码
为什么要软量化?硬量化编码的缺点是什么?
图像局部特征常常存在一定的模糊性,即一个局部特征可能和多个视觉单词差别很小,这个时候若使用向量量化编码 将只利用距离最近的视觉单词,而忽略了其他相似性很高的视觉单词
软量化编码(又称核视觉词典编码)算法,局部特征不再使用一个视觉单词描述,而是由距离最近的 K 个视觉单词加权后进行描述,有效解决了视觉单词的模糊性问题
稀疏编码
将稀疏编码应用到物体分类领域,替代了之前的向量量化编码和软量化编码,得到一个高维的高度稀疏的特征表达,大大提高了特征表达的线性可分性,仅仅使用线性分类器就得到了当时最好的物体分类结果,将物体分类的研究推向了一个新的高度上(关于 稀疏表示分类的文章太多了,关键在于 高维的高度稀疏的特征表达导致了 线性可分性)
这里岔开去一点,找 Bag of visual words 的模式套一下 Sparse Representation Classification,SRC 的分类器的样本就是图像,所以这里的底层特征不再是 local features 的 集合,就是图像本身;因为不再是 local features,所以也就不存在 local features 聚合的问题;因此,稀疏编码本身就是在做分类。
局部线性约束编码
稀疏编码的问题?为什么要引入局部线性约束?稀疏编码存在一个问题,即相似的局部特征可能经过稀疏编码后在不同的视觉单词上产生响应,这种变换的不连续性必然会产生编码后特征的不匹配,影响特征的区分性能
局部线性约束编码的提出就是为了解决这一问题,它通过加入局部线性约束,在一个局部流形上对底层特征进行编码重构,这样既可以保证得到的特征编码不会有稀疏编码存在的不连续问题,也保持了稀疏编码的特征稀疏性.局部线性约束编码中,局部性是局部线性约束编码中的一个核心思想,通过引入局部性,一定程度上改善了特征编码过程的连续性问题,即距离相近的局部特征在经过编码之后应该依然能够落在一个局部流形上.局部线性约束编码可以得到稀疏的特征表达,与稀疏编码不同之处就在于稀疏编码无法保证相近的局部特征编码之后落在相近的局部流形
显著性编码
显著性编码引入了视觉显著性的概念,如果一个局部特征到最近和次近的视觉单词的距离差别很小,则认为这个局部特征是不“显著的”,从而编码后的响应也很小.
Fisher 向量编码
基本思想: 编码局部特征和视觉单词的差
Step 3: 空间特征汇聚
空间特征汇聚是特征编码后进行的特征集整合操作,通过对编码后的特征,每一维都取其最大值或者平均值,得到一个紧致的特征向量作为图像的特征表达. 这一步得到的图像表达可以获得一定的特征不变性,同时也避免了使用特征集进行图像表达的高额代价.(目的是从 局部特征集合 set/collection 中得到 整个图像的一个特征表示向量)
空间金字塔匹配
由于图像通常具有极强的空间结构约束,空间金字塔匹配(Spatial Pyramid Matching,
SPM)[9]提出将图像均匀分块,然后每个区块里面单独做特征汇聚操作并将所有特征向量拼接起来作为图像最终的特征表达
深度学习模型
自动编码器是基于 特征重构的无监督特征学习单元,加入不同的约 束,可以得到不同的变化,包括去噪自动编码器、稀 疏 自 动 编 码 器
词包模型与 CNN 的异同
在词包模型中,对底层特征进行特征编码的过程,实际上近似等价于卷积神经网络中的卷积层,而汇聚层所进行的操作也与词包模型中的汇聚操作一样.
不同之处在于,词包模型实际上相当于只包含了一个卷积层和一个汇聚层,且模型采用无监督方式进行特征表达学习,而卷积神经网络则包含了更多层的简单、复杂细胞,可以进行更为复杂的特征变换,并且其学习过程是有监督过程的,滤波器权重可以根据数据与任务不断进行调整,从而学习到更有意义的特征表达.(因此,卷积神经网络具有更为强大的特征表达能力)
要注意分类算法的发展趋势:高计算强度,高内存消耗等,多特征、非线性分类器等这些在 PASCAL 竞赛中广为使用的算法和策略无法在 ImageNet 这样规模的数据库上高效实现.在性能和效率的权衡中,逐渐被更为简单高效的算法(单特征、特征压缩、线性分类器等)替代(总而言之是要 简单、有效)
物体检测
物体检测任务与物体分类任务最重要的不同在于,物体结构信息在物体检测中起着至关重要的作用,而物体分类则更多考虑的是物体或者图像的全局表达。(那这些物体检测算法是怎么刻画物体结构信息的?)
物体检测的输入是包含物体的窗口,而物体分类则是整个图像,就给定窗口而言,物体分类和物体检测在特征提取、特征编码、分类器设计方面很大程度是相通的。(物体检测与物体分类的相似之处)
滑动窗口方法比较简单,它是通过使用训练好的模板在输入图像的多个尺度上进行滑动扫描,通过确定最大响应位置找到目标物体的外接窗口.(训练好的模板是什么?)

相比 分类算法,检测算法多了一个 检测策略,把 空间特征汇聚 换成了 上下文,但其实 检测算法也有空间特征汇聚,比如 faster r-cnn,但是 上下文是目标检测独有的。
结构化学习
与物体分类问题不同,物体检测问题从数学上是研究输入图像X与输出物体窗口Y之间的关系,这里Y的取值不再是一个实数,而是一组“结构化”的数据,指定了物体的外接窗口和类别,是一个典型的结构化学习问题.
弱标签结构化支持向量机(Weak-Label Structrual SVM,WL-SSVM)是一种更加一般的结构化学习框架,它的提出主要是为了处理标签空间和输出空间不一致的问题,对于多个输出符合一个标签的情况,每个样本标签都被认为是“弱标签”(可以认为弱监督学习问题是标签空间和输出空间不一致的问题)
物体检测和物体分类的统一性
分类模型建立了以词包模型和深度学习模型 为基础的体系框架,检测模型则以可形变模型为核 心发展出多种方法
物体检测可以取代物体分类?
在模型区分性比较强的情况下,也就是物体检测能给出准确的结果的情况下,物体检测在一定程度上可以回答“什么物体在什么地方”,但在真实的世界中,很多情况下模版不能唯一的反映出物体类别的唯一性,只能给 出“可能有什么物体在什么地方”,此时物体分类的介入就很有必要了.由此可见,物体检测是不能替代 物体分类的.(这里讲得其实是 Object Detection 会有 Classification Loss 和 Localization Loss 两个,Object Detection 还可以有先 Localization 再 Recognition 的思路,所以不一定要同时做出来,可以有先后的做出来;如果粒度比较细,就让专注分类的来做,而不是让 Localization 来拖累网络的专注性)
物体检测和物体分类之间的差异性和互补性
物体检测主要采用的是可变的部件模型,更多的关注局部特征,物体分类中主要的模型是词包模型,从两者的处理流程来看,他们利用的信息是不同的,物体检测更多的是利用了物体自身的信息,也就是局部信息,物体分类更多的是利用了图像的信息,也就是全局的信息. 他们各有优劣,局部信息考虑了 更多的物体结构信息,这使得物体检测和分类的准确性更高,但同时也带来物体分类的鲁棒性不强的问题; 全局信息考虑了更多的是图像的全局统计信息,尤其是图像的语义信息,这使得能考虑更多的信 息来进行判断,但信息量的增加可能带来准确度的提高,也可能由于冗余降低分类的性能,但是从统计意义而言,其鲁棒性是能够得到一定的提高的.由此 可见,物体检测和物体分类之间存在着较大的差异 性,同时也就说明存在着比较大的互补性.(我是没看懂,物体检测不就是 Classification on Proposed Region 这个思路么?没啥区别吧?)
物体分类与检测的发展方向
物体分类中全局表达更关键;物体检测中物体结构更为关键。
- 专注于学习结构,即结构化学习.观察变量与其他变量构成结构化的图模型,通过学习得到各个变量之间的关系,结构包括有向图模型(贝叶斯网络)、无向图模型(马尔科夫网络). 结构化学习通常变量具有显式的物理意义,变量之间的连接也具有较强的因果关系,解释性较好.
- 专注于学习层次化表达,即深度学习.(这个好像做不动了吧?基础架构不动了,但通过Attention改善特征质量好像还可以做)
两条思路各有侧重,但并不是互相独立的.在这两条发展线路的基础上,建立更为统一的物体识别框架,同时处理物体分类与检测任务,是一个更加值得研究的方向. 如何利用物体检测和物体分类之间的互补性去构建统一的物体识别框架(利用物体检测和物体分类的统一性)是计算机视觉和视觉认知领域的研究热点,也是视觉认知计算模型研究的重点之一
层次化学习(深度学习)存在的难点与挑战
- 解释性差(真的差吗?文章里的解释没法说服我)
- 模型复杂度高,优化困难.
- 计算强度高:对于深度学习,输入一个视觉信号,所有的神经元都会进行计算,人为加的一些稀疏约束只是会使某些神经元输出为0,但不代表该神经元“处于不活动”状态
- 模型缺少结构约束.深度学习模型通常只对网络的“输入-输出”进行建模,却缺少必要的结构先验的约束.例如,对人脸关键点可以采用卷积神经网络进行回归,网络学习到的是一种隐式的“输入-输出”结构,却完全没有加入显式的结构先验;将显式结构先验嵌入深度学习模型中,可以有效降低网络参数空间的规模,减少局部极值的问题(怎么将显式结构先验嵌入深度学习模型中?)
[36] Biological Explanation on Visual Selective Attention
这篇是对下面两篇文章的笔记整理。两篇文章都是同一个作者,前一篇是 ECCV 2018 的文章,后面作者挂在了 arXiv 上,看样子是投 CVPR 的。
Yohanandan, ECCV 2018, Saliency Preservation in Low-Resolution Grayscale Images
Yohanandan, arXiv 2018, Fast Efficient Object Detection Using Selective Attention
注意力机制一般分为 bottom-up 和 top-down 两种。Bottom-up 的注意力机制是外界刺激和特征驱动的,负责快速、自动且不由自主的注意力和凝视的快速转变;相反,top-down 机制是任务驱动、基于经验(记忆)的,因人而已。这篇笔记,或者说上面两篇论文只针对 Bottom-up,主要内容是从生理机制上解释为何人类的显著性检测和选择性注意力能够如此高效。此外,对我而言,读完这两篇文章另外一个收获是对于 Object Detection 中的 One-stage method 和 Two-stage method 中的选择,让我坚定了对 Two-stage method 的信仰,因为在我看来人眼 Bottom-up 的视觉选择性注意就是一个 two-stage 过程。
Biological Explanation
作者先是讲了一个生物视觉进化的故事:
- 最早的生物都是没有视觉的
- 后来略微进化出一点感光细胞,有了 discriminated night and day 的能力;
- 再后来,有了一点光源定位的能力,能够 distinguishing light from shadow;
- 接着是进化出能够粗略认出周围物体的能力,这被认为是 the birth of stimulus-driven, bottom-up visual salience detection,到这一阶段是 blurry achromatic peripheral vision,模糊的消色的外围视觉
- 然后,进化出 focus-sharpening lenses
- 再然后是 foveated central vision
- 最后才是感知 彩色 的能力,到这一步才有 high-acuity chromatic central vision,高度敏锐的彩色中央视觉
从这个故事叙述里,作者已经开始在暗示 彩色 和 高敏锐度的视觉都是在 粗略认出周围物体的能力 之后发展出来的。如果只是要模拟粗略认出周围物体的能力(这就是 Region Proposal 干的事情),那么就不需要在我们的 computational model 里面去涉及对彩色 和 高敏锐度的视觉的模拟,彩色就是彩色,高敏锐度的视觉则指的是高分辨率图像,也就是说 Region Proposal 或者 Saliency Detection 不需要在彩色高分辨率图像上做,只要 blurry achromatic peripheral vision 就可以了。
由此可见,人类 bottom-up Attention 其实有两部分构成,一部分是 blurry achromatic peripheral vision,另一部分是 high-acuity chromatic central vision。Peripheral vision 相当于 Region Proposal,负责 bottom-up visual salience detection,用来指示 the sharper, high-resolution foveated (sometimes chromatic) vision to investigate objects and regions further,由此实现了人类可以 rapidly shift foveal gaze to salient regions 的能力。但这样机制的背后,是有具体的生理基础。
总所周知,我们视网膜上的感光细胞分为视杆细胞(Rods)和视锥细胞(Cones),这两种细胞在分工、数量、分布和连接的后续细胞的数量上都有以下不同:
- 在分工上,Rods primarily encode achromatic luminance (brightness) information;而 cones encode chrominance (color);
- 在分布上,Rods have a higher distribution outside the fovea;而 are concentrated in the fovea (center of the retina),这就是为什么一个被叫做 peripheral vision,一个被叫做 foveated central vision,下图展示了 Rods 和 Cones 的分布情况
- 在连接的后续细胞的数量上,multiple rods converge to and activate a single retinal ganglion neuron,而 each cone activates multiple ganglion neurons。这个 Retinal ganglion cells (RGCs) 是 Final output neurons of the retina,可以代表输出图像的分辨率。因为连接的后续细胞的数量上,Rods 少于 Cones,这也是为什么 rod vision has lower spatial resolution,而 Cones vision 是 higher acuity vision。为什么最后输出的图像分辨率会不同,因为决定感知到的图像分辨率(perceived image resolution)的 并不是 光感受体(photoreceptors)数量,而是 视网膜传入神经节神经元 RGCs,而视锥细胞连接的 视网膜传入神经节神经元 比 视杆细胞多。
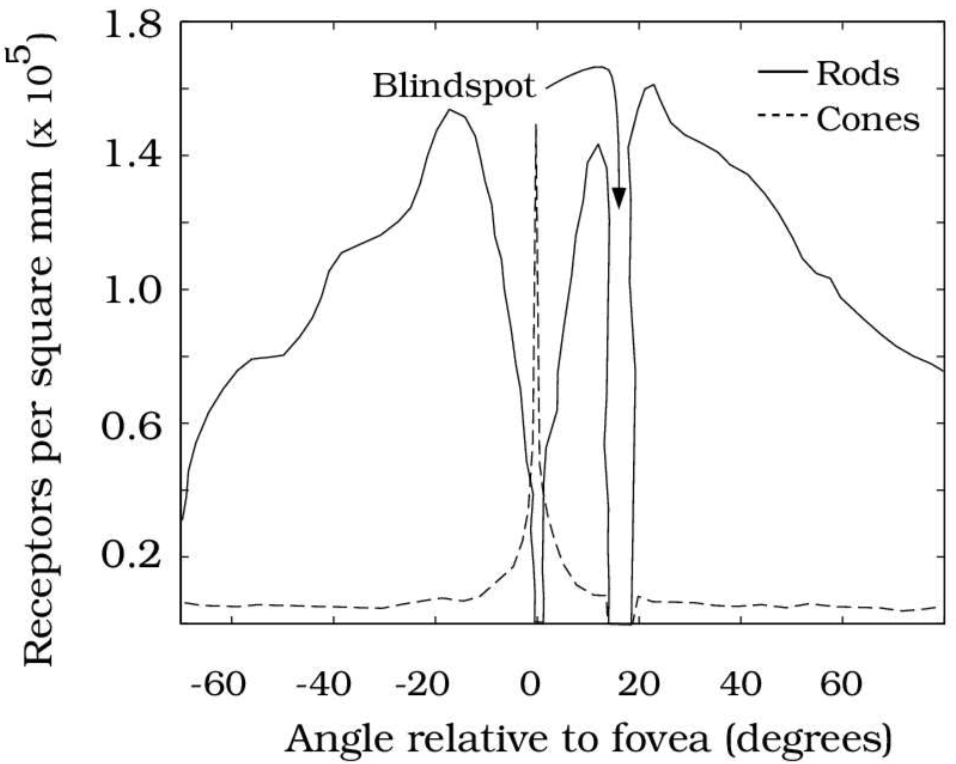
因此,可以稍微概括下,Cones, concentrated in the fovea, encode high-resolution color. Rod photoreceptors distributed outside the fovea encode low-resolution grayscale information。
那么具体 Rods 对应的 RGCs 和 Cones 对应的 RGCs 分别是什么,又是怎么一个数量关系呢?RGCs 作为视网膜最后的输出神经元,有 P$\beta$ RGCs,P$\alpha$ RGCs 和 P$\gamma/\epsilon$ RGCs 三类。其中,P$\beta$ RGCs 负责通过 longwave (red), medium-wave (green), and shortwave (blue) sensitive detectors 表现 color opponency 颜色对比。什么是这些 RGB sensitive detectors 呢?就是 Cones 视锥细胞。而 P$\alpha$ RGCs 和 P$\gamma/\epsilon$ RGCs 是消色的,编码 primarily luminance information。P$\beta$ RGCs,P$\alpha$ RGCs 和 P$\gamma/\epsilon$ RGCs 的分布分别是 Laplacian,Gaussian 和 Poisson,前两者分布相对集中、中心化,而后者分布相对均匀、平坦。具体如下图所示。
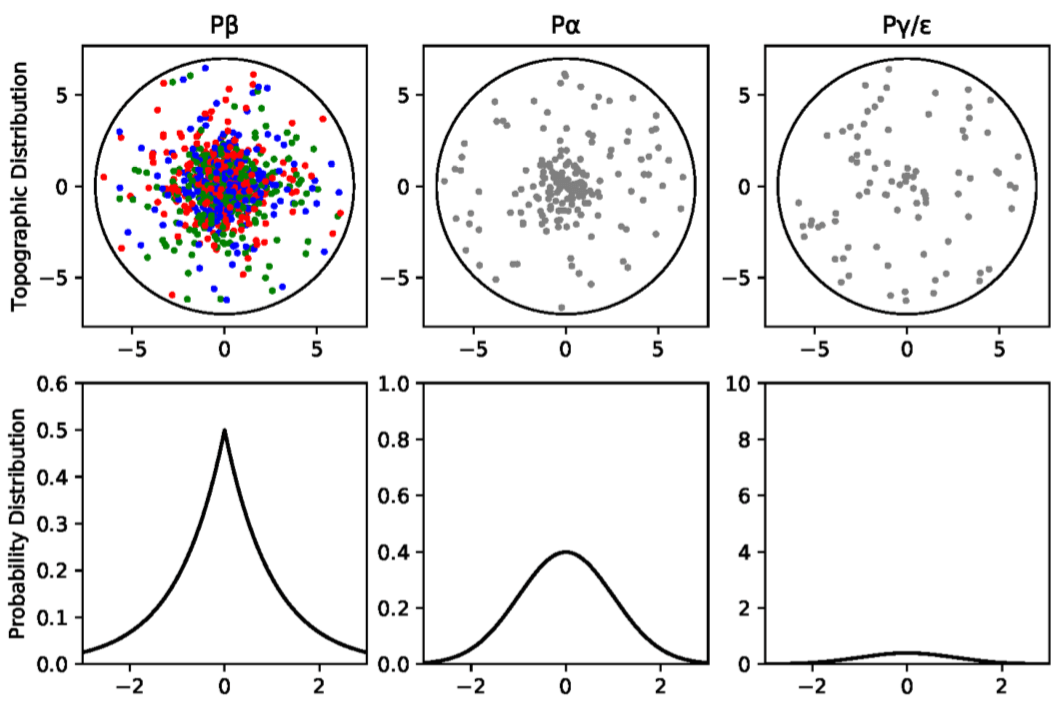
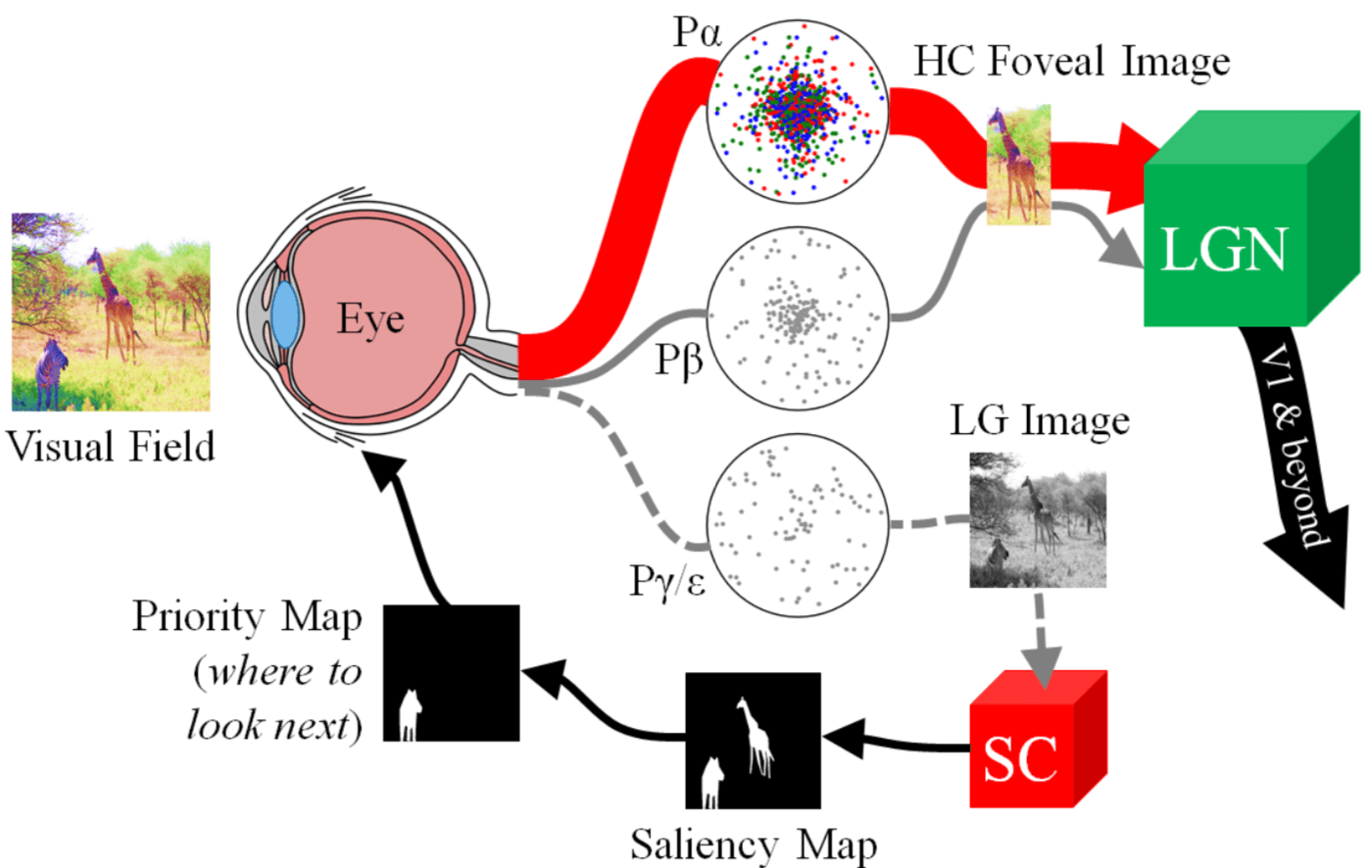
在所有 RGCs 中,大约 80% 是表现颜色对比度的 P$\beta$ RGCs;大约 10% 的 RGCs 是消色的 P$\alpha$ neurons,他们的轴突投射都是从视网膜的 foveal region 到 lateral geniculate nucleus 外侧膝状体,简称 LGN。只有剩下 10% 的 P$\gamma$ RGCs 和 P$\epsilon$ RGCs 以及某一些 P$\alpha$ RGCs,被投影到了一个叫做 optic tectum,中文叫视顶盖,也叫 superior colliculus,中文叫 上丘 的结构,简称 SC。由于 SC 接收到的信息只有所有 RGCs 的 10%,这就是为什么论文中会说 SC 所接收的信息只有输入视网膜信息的 10% 的依据,是属于较低分辨率的视觉信息,且是消色的。而近年来神经科学的研究发现,SC 是负责产生显著性图的区域,是 bottom-up salience detection 的先驱。 此外,SC 还对眼部肌肉有着直接控制,direct retinal input into the SC 引发由脑干动眼神经核控制的反射般的跳视 reflex-like saccades,这个应该是为了输入 High-Resolution Color Foveal Image。Eye movements align objects with the high-acuity fovea of the retina, making it possible to gather detailed information about the world。因此,在我看来,Rods 负责完成消色下采样,SC 负责 generate Saliency map 并在此基础上做 Region Proposal(通过 control eye muscles 实现)。
多提一句 Saliency map 的价值在于 This mapping projects the locations of salient and interesting regions in visual space, thus making vision more efficient by narrowing down the regions an observer must attend to in a typically large visual field. 这是 Region Proposal 的作用。
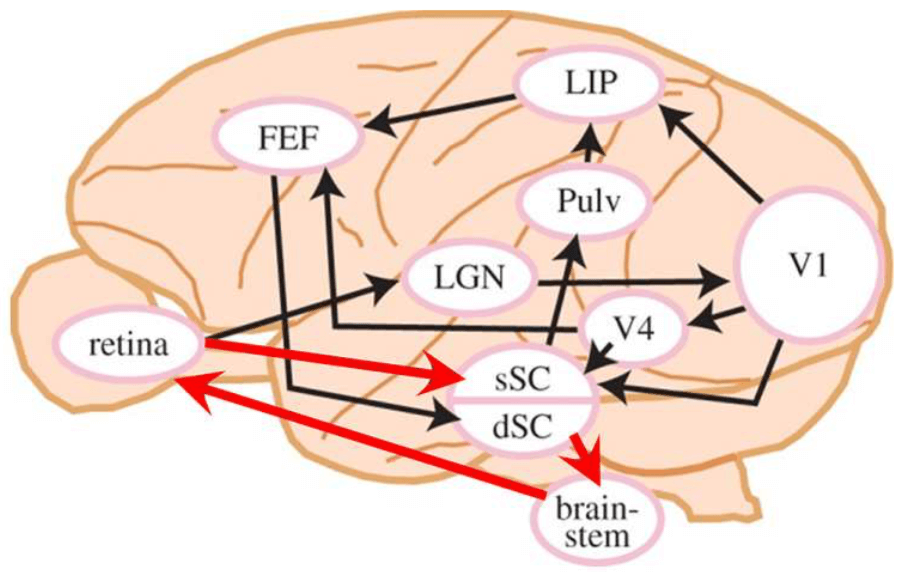
这里表明,人类视觉有两条视觉通路,一条是开始与消色的 Rods 光感受体 -> P$\gamma$ RGCs 和 P$\epsilon$ RGCs -> SC 的通路,这条通路叫作 the retinocollicular pathway,也是下图中红色箭头所指的;另一条是 Cones -> P$\beta$ RGCs 和 P$\alpha$ RGCs -> LGN -> V1 的通路,具体如下图所示。两条通路这件事对我震动蛮大的,以前人们认为 the saliency map was generated in the primary visual cortex (V1),也就是认为图像只有一个输入,就是高分辨率的输入;但现在发现,图像其实有 两个输入,different visual pathways,一个是输入 SC 的 LG 图像,另一个是根据 SC 产生的 Saliency Map 指导下输入的 high-resolution region。但目前我们 end-to-end 的算法都只有高分辨率输入,要不要为此做出相应的改变呢?
现在我们已经知道人类视觉是在以 Rods 为起点的 blurry achromatic peripheral vision 通路,和以 Cones 为起点的 high-acuity chromatic central vision 两条通路合作下工作的,那么它们是怎么合作的呢?
快速高效的 Bottom-Up Visual Attention 的机制如下,关键在于 processing low-resolution achromatic visual information from the retina:
- 首先,the retinocollicular pathway shrinks the high-resolution color image projected onto the retina from the visual field into a tiny colorless, e.g. low-resolution grayscale, image, which can then be scanned quickly by the SC to highlight peripheral regions worth attending to via the saliency map.
- The SC then aligns the fovea to attend to one of these regions, thereby sending higher-acuity, e.g. high-resolution color, visual information to the LGN and beyond for further processing.
- In doing so, a new image of the visual field is now projected onto the retina, and the cycle repeats.
具体的示意图如下图所示:
由此可见,Visual signals from the retina to the cerebral cortex are mediated through the primary visual cortex (V1) and the superior colliculus (sSC and dSC). 输入大脑皮层的视觉信息同时受到 primary visual cortex (V1) 和 superior colliculus 的调解,这也应了一个很早以前就看到的观点,大脑并不是一个中央处理器,而是由多个处理器共同决策、控制的结果。
除了输入是 Low-Resolution Grayscale Images 之外,Visual Saliency Attention 能够快速有效的还有一个生理基础在于存在一个 a shortcut from the superficial (sSC) to the deep (dSC) superior colliculus, which then sends outputs directly to the brainstem oculomotor nuclei, resulting in rapid saccades,也就是 现在的 shortcut 是 retina -> sSC -> dSC -> brain-stem -> retina,否则得话,我看图上有 retina -> LGN -> V1 -> V4 -> FEF -> dSC -> brain-stem -> retina 这种绕一圈的通路,这就没法 rapid 了。
Computational Approximation
我们稍微概括一下上面的生物机制,然后看看如何用计算模型模拟这种生物机制
- SC 是产生显著性图的地方
- SC 的输入是 low-resolution grayscale image
对上述生物机制的计算模型逼近显然易见,就是在 Low-Resolution Grayscale Images 上计算显著性图,并以此显著性检测的结果作为高分辨彩色输入图像上的 Region Proposal,然后再进一步识别。 在 Low-Resolution Grayscale Images 上计算显著性图先比在 High-Resolution Color Images 上计算并不会有什么信息缺失,这一点不管是上面的生物机制启示还是论文后面的数值实验都验证了,这就是论文标题的 Argument, Saliency Preservation in Low-Resolution Grayscale Images,而这么做的好处是非常高效。
- 怎么将 High-Resolution Color Images 降采样成 Low-Resolution Grayscale Images?(模拟 视杆细胞 负责对图像下采样)
- 怎么在 Low-Resolution Grayscale Images 上实现显著性检测?(模拟 SC 负责的基于显著性检测的 Region Proposal)
- 怎么对 High-Resolution Color 的 Foveal Image(比如上图右上角的长颈鹿所在的 Region Proposal)实现识别?
那么降采样改怎么做呢?分为两步。感觉这个就很平常了
- 第一步,transforming the color space of high-resolution color (HC) images $I_HC$ to 8-bit grayscale $I_HG$
- 第二步是 down-sampled the original image resolution using bicubic interpolation (单边 64 像素,或者 downsample the original image to 10% of its original size,但作者也提到了,10% 是依据猕猴的生理机制来的,未必对于计算机视觉里的Object Detection 就是最优的)
但作者说这篇文章是提出本文是最早提出 Saliency Preservation in Low-Resolution Grayscale Images,感觉也有点过了,我印象里至少 Hou Xiaodi 在 CVPR 2007 的 Spectral Residual 里面就提到 64 x 64 就足好地可以计算显著性了。
至于怎么实现显著性检测,作者虽然给了方案,但是太简略了,也不是我对论文感兴趣的原因。至于第三个问题,论文中也没有提。
对目标检测的启示
目前方法慢的原因:不管是 One-Stage 还是 Two-Stage 的 Region Proposal 阶段,虽然他们都是在 downsampling 后的 feature map 上做的,但是这些 feature map 都来自于 High-Resolution Color Images。从 High-Resolution Color Images 得到这些 Feature Map 需要消耗很多的计算量,这是一个慢的原因。另一个慢的原因是 exhaustive classification,为了要 densely covering many different spatial positions, scales, and aspect ratios 需要 evaluate $10^4 − 10^5$ candidate regions per image. 但我不是很赞成后面一点,因为在不知道目标可能在哪之前,总要考虑所有区域,做 Saliency Detection 本身也是一件需要 exhaustive search 的事情,计算的绝大多数区域而是一样的 uninformative background。
而在 Low-Resolution Grayscale Images 上做 Region Proposal 的好处是,significantly reducing the visual search space of objects and regions of interest;因为 输入是 LG,总的计算量不大,另外一个好处是,generating a saliency map 只要 a relatively small and simple neural network 就够了,模型不需要很大。
作者这里还有一个 argument,是 detecting the presence of an object,如果仅仅是 detect 也就是判断有无,而不是判断哪一类(Classification),那么high-resolution details about objects, such as texture, patterns, and shape 这些是没有用的,color or other feature-specific properties are seem only essential for classification,这个 argument 支持了为什么 natural vision 会有 LG transformation。但作者这里的 Detect 是 Region Proposal 阶段的 Saliency Detection,并不是现在我们常说的 Object Detection 的 Detection。
最后的最后,这篇文章给我留下的疑惑是,这丫不就又回到 R-CNN,Region Proposal 和后面的 Classification 分开做,且 Region 要 resize 之后的路线了么?
To Read List
- [1] 郑南宁. 认知过程的信息处理和新型人工智能系统[J]. 中国基础科学. 2000(8): 9-18.
- [2] ICCV-2015-Look and think twice: capturing top-down visual attention with feedback convolutional neural networks(在 CNN 的卷积层加上层间的反馈连接,将高级的语义和全局信息传到下层,通过语义标签的反馈,可以激活特定的与目标语义相关的神经元,从而实现自顶向下的视觉注意,定位复杂背景中的潜在目标。)
- [3] NIPS-2014-Attentional neural network: feature selection using cognitive feedback (通过 top- down 的反馈连接和乘法机制引入注意力模型)
- [4] CVPR-2015-Recurrent convolutional neural network for object recognition 和 [5] NIPS-2015-Convolutional neural networks with intra-layer recurrent connections for scene labeling (在 CNN 的卷积层加上层内连接的方法,使每个单 元可同时接收前馈和反馈的输入)
- Scale-Aware Trident Networks for Object Detection 主要要解决的问题便是目标检测中最为棘手的 scale variation 问题
[2 - 5] 都是为了更好地模拟脑,将将反馈引入神经网络的尝试(脑皮层中反馈神经元连接比前 馈多得多,但是传 统的深度神经网络模型里一般只有前馈连接,尚缺乏对 反馈的建模)
Deep Image Homography Estimation
还是 Magic Leap 的文章,跟上一篇 SuperPoint 是同一个作者 Daniel DeTone。
Instead of manually engineering corner-ish features, line-ish features, etc, is it possible for the algorithm to learn its own set of primitives?
从上面这段话看来,作者不是要做不是人工设计的特征,而是自己学特征么?但从标题看,作者更是要做学怎么估计 Homography?
如果您觉得我的文章对您有所帮助,不妨小额捐助一下,您的鼓励是我长期坚持的一大动力。
 |
 |
|---|---|
Discriminative learning of deep convolutional feature point descriptors
ICCV 2015 的文章。
本文想做的目的是 Representing local image patches in an invariant and dis- criminative manner
In our case discriminative training does not rely on labels of individual patches, but rather on pairs of cor- responding, or non-corresponding patches. 这是不是也是一种 weakly supervised learning?
use a Siamese network architecture
treating the CNN outputs as patch descriptors(CNN 的 output 直接作为 patch descriptor)
minimize a loss that enforces the L2 norm of their difference to be small for corresponding patches and large otherwise (Loss 就是 让一样的 pair 之间的 L2 norm 尽量小,不一样的尽量的大)
作者提出的 a strategy of aggressive mining of “hard” positives and negatives 到底是什么?
这里首先有个问题,it may be unclear whether CNNs are equally appropriate for patch-level applications where semantic information may be missing,也就是说 Patch 里面的 semantics 不够,那么 CNN 适合来做 patch 吗?
simply use the L2 distance to compare patches 是本文的一个卖点
这篇文章其实是来解决 descriptor 的 repeatability 的,这里的 repeatability 由同一对 pair 通过 Siamese 网络判断是不是同一对来保证,对于实际上是同一对但有视角变化的 pair 来说,应该要输出相近的 descriptor
最后一层的输入是 88,滤波器是 55,如果不做 padding,那么滤波后的大小就是 4 4,又因为 Pooling 的 大小是 4 4,所以最后输出的就是一个 1 1 128 的向量
3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions
2017 CVPR
本文的目标是想做什么? our goal is to create a function ψ that maps the local volumetric region (or 3D patch) around a point on a 3D surface to a descriptor vector,也就是想做一个 3D 的 local Feature descriptor
同 2D 一样,这个 3D 的 local Feature descriptor 也要具有 repeatability,具体表现就是 Given any two points, an ideal function ψ maps their local 3D patches to two descrip- tors, where a smaller l2 distance between the descriptors in- dicates a higher likelihood of correspondence.
本文的 3D local Feature descriptor 是学出来的,要学习就要有 data 和 label,本文的 data 和 label 的来源是 making use of data from existing high quality RGB-D scene reconstructions,我没看到是什么意思,到底怎么来的?
文章说,each reconstruction contains millions of points that are observed from multiple different scanning views,是说 3D 模型可以转啊,也就是不同的视角,这就是现成的匹配数据(同 Homographical adaptation 在 2D 平面上变化一个道理,都是用来做自监督的)
文章通篇再讲 descriptor,关键在于 Detector 是怎么产生的,文中的 interest point 是怎么产生的?
是直接对 patch 做的,关键是你怎么知道哪些 patch 是相关的,哪些不是的?
因为知道 3D 点的 3D position,然后随着帧的变化,只要在不同帧的这个 3D position 周围的两个 3D patch 就是匹配的 pair
Discriminative learning of deep convolutional feature point descriptors
ICCV 2015 的文章
使用卷积网络提取图像局部特征,得到的 patch 描述之间的距离可以直接用欧式距离度量。可以在各种应用中直接替代 SIFT 等特征。网络是用 Contrastive Loss 训练的
develop 128-D descriptors whose euclidean distances reflect patch similarity,and which can be used as a drop-in replacement for any task involving SIFT
Quad-networks: unsupervised learning to rank for interest point detection
用人肉去 label interest point 是不现实的,it is often unclear what points are “interesting”, human labelling cannot be used to find a truly unbiased solution. Therefore, the task requires an unsupervised formulation. 所以作者打算用无监督的来做
有意思的是作者还尝试了 cross-modal interest point detection between RGB and depth images,这个可以关注一下
Learning an interest point detector is a task where labelling ambiguity goes to extremes. 对于 label 而言,interest point 的 label 是非常模棱两可的,没有很清晰的标准。
我们想要得到什么?a sparse set of image locations which can be detected repeatably even if the image undergoes a significant viewpoint or illumination change
retaining the top/bottom quantiles of the response function (contrast filtering) 和 retaining the local extrema of the response function (non-maximum suppression) 这两有啥区别啊?
为什么叫做 quadruple?因为这个涉及到 ranking,所以按照公式(1),会有两个点,然后又是经过变换 t 前后的,所以一共会有 4 个点。
按照公式(2),因为 H 是一个 a single real-valued response function,所以如果两个点在变换前后的 ranking 不发生改变,则这个 ranking agreement function 的数值会是正的,否则就会是 负的
$$
\begin{array} { l } { R \left( p { d } ^ { i } , p { d } ^ { j } , p { t ( d ) } ^ { i } , p { t ( d ) } ^ { i } , p { t ( d ) } ^ { j } | w \right) = } \ { \left( H \left( p { d } ^ { i } | w \right) - H \left( p { d } ^ { j } | w \right) \right) \left( H \left( p { t ( d ) } ^ { i } | w \right) - H \left( p _ { t ( d ) } ^ { j } | w \right) \right) } \end{array}
$$
the set of corresponding point indexes 到底是什么?是变换前后 matching 的点。
那这里只讲了 detect 到一些特征点后,怎么保证 detect 的 invariant,但没有涉及如何 detect,以及如何做 matching?
observation 2 里面的 visible 到底是什么意思?
LIFT: Learned Invariant Feature Transform
ECCV 2016 的文章
LIFT 的训练数据来源于使用 Structure from Motion(SfM) 算法得到的特征点
Feature descriptors are designed to provide discriminative representations of salient image patches, while being robust to transformations such as viewpoint or illumination changes. 注意哦,Feature descriptor 就是来描述 salient image patches 的。
There are datasets that can be used to train feature descriptors [24] and orientation estimators [9]. 竟然有特征点描述子的训练集?
特征点检测就是通过 provides a score map S 以及 perform a soft argmax [12] on the score map S and return the location x of a single potential feature point 来完成的吧,那么问题来了,就是首先你的 score map S 是怎么产生的?
learning first the Descriptor, then the Orientation Estimator given the learned descriptor, and finally the Detector, conditioned on the other two 是说这三部分网络,当学习一个的时候,就固定另外两个的权重?
发现好像这类文章里的 Descriptor 网络的输入都是 Patch
softargmax is a function which computes the Center of Mass,万万没想到 softargmax 竟然是计算重心的?真的假的?按照公式 7 真的是的啊
LF-Net: Learning Local Features from Images
NIPS 2018 的文章
涉及到了 depth maps 啊,可以是 laser scanners 或者说 shape-from-structure algorithms 来的
Scale-Aware Trident Networks for Object Detection
本文说的 generate scale-specific feature maps 是怎么一回事?
a parallel multi-branch architecture in which each branch shares the same transformation parameters but with different receptive fields
a scale-aware train- ing scheme to specialize each branch by sampling object instances of proper scales for training
本文说的 sacrificing the feature consistency across different scales. 怎么理解?
Both image pyramid and feature pyramid methods share the same motivation that models should have different receptive fields for objects of different scales.
With the help of dilated convolutions [43], different branches of trident blocks have the same network structure and share the same parameter weights yet have different receptive fields. 权重是一样的,只是 dilated conv 的间隔不一样,这就是 Trident Networks 的关键吗?
to avoid training objects with extreme scales, we leverage a scale-aware training scheme to make each branch specific to a given scale range matching its receptive field.
approximate the full TridentNet with only one major branch during inference 不理解,怎么做到的? 敢这么做的原因是 This approximation only brings marginal performance degradation.
影响 backbone network 的要素:downsample rate, network depth and receptive field.
Section 3 的 Table 1 是本文最基础的来源,目标的感受野要与目标的尺度相适应
自然而然地有了一个想法,如果可以对不同尺度的目标、同时能有大小不同的感受野去反应它们的特征
以 ResNet 的 residual block 为例,一般是 1x1,3x1,1x1 连续三个卷积核,其中 3x3 的卷积将用上述方法改良,获得三个由不同 rate 的 dilate 卷积构成的并行分支,改良后的结构称之为 trident blocks。
由于存在多分支,最后 inference 的时候,会像 SNIP 一样,每个分支预测出来的结果,只有大小没超出该分支合法范围的 gt 才作数
作者提出的 fast inference approximation 就是用 rate 为 2 的分支近似替代三个分支,来加速预测
考虑对于一个 detector 本身而言,backbone 有哪些因素会影响性能。总结下来,无外乎三点:network depth(structure),downsample rate 和 receptive field。
对于前两者而言,其影响一般来说是比较明确的,即网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。
但是没有工作,单独分离出 receptive field,保持其他变量不变,来验证它对 detector 性能的影响
我们很惊奇地发现,不同尺度物体的检测性能和 dilation rate 正相关!(应该是 物体尺度与 dilation rate 的匹配程度 与 检测性能正相关才对),更大的 receptive field 对于大物体性能会更好,更小的 receptive field 对于小物体更加友好
先 investigate receptive field size 对检测性能的影响,而 receptive field size 这里的表现是 dilation rate,而不是 深度(receptive field size 既可以被 dilation rate 影响,也可以被 receptive field size 影响,还有 anchor size 也会影响)。在发现了 物体尺度与 dilation rate 的匹配程度 与 检测性能正相关之后,要解决的问题是 有没有办法把不同 receptive field 的优点结合在一起呢?
Tridentnet is a backbone, yolo is a detector. You can apply trident block to yolo to get the best of both worlds.
Tridentnet 是个 backbone,是个从 Detection 出发考虑的 backbone,想 ResNet 这种 Backbone 就不是专门为 Detection 考虑的
总结一下,我们的 TridentNet 在原始的 backbone 上做了三点变化:
- 第一点是构造了不同 receptive field 的 parallel multi-branch,
- 第二点是对于 trident block 中每一个 branch 的 weight 是 share 的。
- 第三点是对于每个 branch,训练和测试都只负责一定尺度范围内的样本,也就是所谓的 scale-aware。
这三点在任何一个深度学习框架中都是非常容易实现的。
对 scale variation issue 解决的尝试:
- leverage multi-scale image pyramids
- SNIP 就是这一流派的
- employ in-network feature pyramids
- 最早是 Fast feature pyramids for object detection 这篇文章
- 然后是 SSD,接着是 FPN
A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
ECCV 2016
multi-scale CNN (MS-CNN)
这篇文章是 最早的一个解决尝试目标检测的尺度变化问题的
这文章里面说 RPN 是 A single receptive field,所以不能 handle multi-scale issue 我没看懂
什么是 the inconsistency between the sizes of objects and receptive fields?
这篇文章还是跟 SSD 思路差不多啊,The detection is preformed at various intermediate network layers, whose receptive fields match various object scales
既然是跟 SSD 差不多,那么为什么要有一个上采样的过程呢? 是为了小目标检测,enabling small objects to produce larger regions of strong response,对 Features 做上采样是用来代替对 input 做上采样,可以节省计算量。
从 Fig 3 看,MSCNN 跟 SSD 有什么区别?
MSCNN 中提出的多层特征金字塔上各个分支独立做目标检测,跟 ECCV2016_SSD 的思想很相似,但又往前迈进了一步:SSD 各个分支上预定义 anchor 与 gt bbox 的匹配是粗放的,一个 gt bbox 可能与多个分支上的 anchor 匹配;但 MSCNN 做到了将与 gt bbox 匹配的 anchor 固定到了特定的某一层,某层 feature map 上的 anchor 仅用于匹配特定尺度范围的 gt bbox;预测时,每层分支上独立预测特定尺度范围的目标,这样 MSCNN 每个分支就相当于一个只对特定尺度范围目标做检测的专家系统,然后各个专家系统结果融合,形成三个臭皮匠,顶个诸葛亮的效果,最终能 cover 所有目标尺度的算法;
在 proposal 生成子网络中,基于多尺度特征金字塔分支独立做 proposal 预测,每层 feature map 上特定范围的感受野来匹配特定尺度范围的目标;这些只检测特定尺度范围的检测分支最终联合成一个能处理多尺度目标的检测器;可以达到输入单尺度图像,却能检测多尺度目标之目的,而且不需要图像金字塔操作,检测速度也快;
别人是怎么 handle multi-scale 的?
- Fast R-CNN 在单尺度 feature map 上预定义多尺度 anchor 达到能覆盖多尺度目标之目的;
Attention-guided Unified Network for Panoptic Segmentation
panoptic segmentation 的定义:a task which segments foreground (FG) objects at the instance level as well as background (BG) contents at the semantic level
FG objects provide complementary cues to assist BG understanding
Attention-guided Unified Network (AUNet)
之前的方法 ignores the underlying relationship and fails to borrow rich contextual cues between things and stuff, e.g., people are more likely to stand on grass, instead of trees, although they often have similar appearances.
To facilitate in- formation flow between FG things and BG stuff
Panoptic Segmentation 的 发展
[19] gave a bench- mark of panopic segmentation,应该也是第一次提出 Panoptic Segmentation 这个 Task
然后是 [20],weakly-supervised
然后是 [8]
[19] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dolla ́r. Panoptic segmentation. arXiv:1801.00868, 2018.
[20] Q. Li, A. Arnab, and P. H. Torr. Weakly-and semi-supervised panoptic segmentation. In ECCV, 2018.
[8] D. de Geus, P. Meletis, and G. Dubbelman. Panoptic seg- mentation with a joint semantic and instance segmentation network. arXiv:1809.02110, 2018.
Panoptic Segmentation
在这篇开创性的文章中,作者并没有提出关于全景分割的新算法,只是定义了新的问题,文章中关于全景分割的效果是通过将语义分割(PSPNet)与实例分割(Mask R-CNN)的结果联合在一起得到的
Learning Spatial Context: Using Stuff to Find Things
第二作者是 Daphne Koller,就是写 PGM book 的 Koller
Heitz ECCV 2008
做目标检测的时候,我们人类是会利用 two primary signals
- The first is the local appearance in the window near the potential car.
- The second is our knowledge that cars appear on roads. This second signal is a form of contextual knowledge
那么 Spatial Context 的关键就在于怎么去刻画 contextual knowledge 么?
对于 context 的重要性,下图说的太好了。如果仅仅用 local appearance,两个都会被认为是 cars,但是看见 context 之后,地下的那个人就不会认为是 car 了

context 有 4 种:
- Scene-Thing context,allows scene-level information, such as the scale or the “gist” [5], to determine location priors for objects
- Stuff-Stuff context captures the notion that sky occurs above sea and road below building
- Thing-Thing context considers the co-occurrence of objects, encoding, for example, that a tennis racket is more likely to occur with a tennis ball than with a lemon
- Stuff-Thing context allows the texture regions (e.g., the roads and buildings in Figure 1) to add predictive power to the detection of objects (e.g., the cars in Figure 1)
刻画 context 的方式:
- 刻画成 co-occurrence context,可以是 the presence of a certain object class in an image probabilistically influences the presence of a second class 也可以是 certain objects occur more frequently in cer- tain rooms, as monitors tend to occur in offices
- 一些方法去刻画 Spatial Context 的方式就是 detect objects using a descriptor with a large capture range, allowing the detection of the object to be influenced by surrounding image features
- Another approach to modeling spatial relationships is to use a Markov Random Field (MRF) or variant (CRF,DRF) [14, 15] to encode the preferences for certain spatial relationships.
Context Driven Focus of Attention for Object Detection
很有意思,作者来自于 Slovenia
WAPCV 2007
International Workshop on Attention in Cognitive Systems
In the proper context, humans can identify a given object in a scene, even if they would not normally recognize the same object when it is presented in isolation.
The limitation of a local appearance being too vague is resolved by using contextual information and by applying a reasoning mechanism to identify the object of interest.
刻画 context 的方式其实本质上是在刻画 a reasoning mechanism,co-occurrence context 中 reasoning 的逻辑就是 co-occurrence 的就符合上下文,不 co-occurrence 就不符合
context 的作用就在于拯救 local appearance is rather weak for a unique object recognition
本文的 context 是用来 determine a focus of attention, that represents a prior for object detection,感觉像是 Scene-Thing context
In the field of cognitive attention for object detection, researchers usually decouple the contextual information processing from object detection. These can be performed in a cascade or calculated in parallel and fused in the final stage(分为 performed in a cascade,或者 calculated in parallel and fused in the final stage,也就是 cascade 串行 和 parallel 并行两种,前者就很像 RPN 了). Using such an approach, any object detector can be combined with the contextual processing. Therefore, the related work is focused on how context can improve object detection rather than on object detection approaches. (本文想研究的是 context 来改善 Object Detection)
我现在明白 Context Driven Focus of Attention for Object Detection 这题目的意思了,作者要表达的是 context driven focus of attention for object detection,attention 或者说 Saliency Detection 具体怎么计算的,这里说是来自于 context

Torralba and Oliva 是做 context 领域的大牛
Scene-Thing context 用 gist of the scene 来刻画:The main idea is to categorize scenes based on the properties of the power spectrum of images. Semantic categories are extracted from the spectrum in order to grasp the so called gist of the scene. As the category of an image is determined, the average position of objects of interest within the image (e.g., a pedestrian, a car) is learned from a large database.
spatial context 的另一种刻画方式,extract a geometric context from a single image,extended classical object detection into 3D space by calculating a coarse viewpoint prior [18]. The knowledge of the viewpoint limits the search space for object detection, e.g. cars should not appear above the horizon. (the reasoning mechanism 就是 某些 Object 不会出现在某些区域)(这一点蛮有意思的,把 3D Vision 和 2D vision 结合起来了)
how to depict the context
这篇文章是把 context Information 作为 a focus of attention,用 context 来做 Region Proposal? 说法是 Context provides cues of information about an object’s location within an image. 而通常 object detectors typically ignore this information. This context was then used to calculate the focus of attention, that presents a prior for object detection.
下图把这种 context Information 作为 a focus of attention 也就是 cues of information about an object’s location 展示的很明显。

我搞不懂的是 geometry 和 viewpoint 的区别在哪里?
the viewpoint prior 是 the tilt angle of the camera’s orientation
the viewpoint prior, derived from a horizon estimate,We calculate the position of the horizon in the image, which is described by the tilt angle of the camera’s orientation
Attentive Contexts for Object Detection
现有方法的局限:
typically classify candidate proposals using their interior features
localize objects using only information within a specific proposal that may be insufficient for accurately detecting challenging objects, such as the ones with low resolution, small scale or heavy occlusion.
context 的好处
global and local surrounding contexts that are believed to be valuable for object detection
extract and utilize contextual information to facilitate object detection
context 还分为 global contextual information 和 local context,自然就会有怎么去刻画 global context 和 local context 的问题
- how to identify useful global contextual information for detecting a certain object?
- how to exploit local context surrounding a proposal for better inferring its contents?
considerable improvements for object detection brought by exploiting contextual information
a global view on background of an image can provide useful con- textual information;if one wants to detect a specific car within a scene image, those objects such as person, road or another car that usually co-occur with the target may provide useful clues for detecting the target.
但是 incorporating meaningless background noise may even hurt the detection performance;那么关键问题就变成了 identifying useful contextual information is necessarily the first step towards effectively utilizing context for object detection 我怎么知道什么是 useful?
a local view into the neighborhood of one object proposal region can also provide some useful cues for inferring con- tents of a specific proposal. For example, surrounding environment (e.g. “road”) and discriminative part of the object (e.g. “wheels”) could benefit detecting the object (e.g. “car”) obviously
related works
Chen et al. [20] proposed a contextualized SVM model for complementary object detection and classification
[20] Chen, Q., Song, Z., Dong, J., Huang, Z., Hua, Y., Yan, S.: Contextualizing object detection and classification. IEEE Transactions on Pattern Recognition and
Machine Intelligence 37(1) (2015) 13–27
Bell et al. [21] presented a seminal work devoted to integrating contextual information into the Fast-RCNN framework. In [21], a spatial recurrent neural network was employed to model the contextual information of interest around proposals.
[21] Bell, S., Zitnick, C.L., Bala, K., Girshick, R.: Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. arXiv preprint
arXiv:1512.04143 (2015)
问题:How to effectively model and integrate contextual information into current state-of-the-art detection pipelines is still a worthwhile problem yet has not been fully studied.
incorporate the most discriminative global context into local object detection 具体是怎么实现的?
global attention map 的作用:background noise that may hurt the detection performance is successfully suppressed on the attention map
说白了就是要 exploit cues from context
之前 RPN 虽然有多个多尺度的 Anchor,但每个 Anchor 都是独立经过 ROI Pooling 的;这个 Multi-scale contextualized sub-network 干的事情就是把 多个尺度的 Anchor(以同一点为中心、但 Anchor Size 不同)做完 ROI-Pooling 的 features concatenating 在一起,作者把这个叫做 Multi-scale contextualized sub-network,具体如下图所示。这么做背后的依据是觉得 local surrounding contexts 会 benefit object Detection 吧
Global context 是怎么刻画的?a recurrent attention model including three LSTM layers is adopted to recurrently detect useful regions from a global view (怎么从 a global view 里来 detect useful regions 应该是靠 LSTM 来实现的吧)
算法流程:
- An image is first fed into a convolutional network to produce the feature cube 抽取共享的特征
- Then the feature cub passes through the multi-scale contextualized sub-network for local context information extraction.
- The bounding box of each proposal is scaled with three pre-defined factors and feature representations from the bounding boxes are extracted by an RoI pooling layer. (Multi-scale ROI-Pooling,背后的 Motivation 是 Beyond the original bounding box of a specific proposal, two more scales used to exploit inside and outside contextual information are employed to enhance the feature representation.)
- Each feature representation, after L2-normalization, concatenation, scaling, dimension-reduction, is then fed into two fully-connected layers (normalization, concatenation, scaling, dimension-reduction)
- In the attention-based contextualized sub-network,
- the feature cube is first pooled into a cube with a fixed scale (是对 shared conv 得到的整个 feature cube 做 pooling,理由是 Since input images usually have different sizes, shapes of feature cubes from the last convolutional layer are also different. To calculate the global context with consistent parameters, the feature cube is pooled into a fixed shape of K × K × D (20 × 20 × 512 in our experiments) )
- Then, a recurrent attention model including three LSTM layers is adopted to recurrently detect useful regions from a global view (这一块没看懂,框图里面的输入 lt, xt 分别是什么? $x_t$ 并不是 $K^2$ 中的第 1 个 tube, $x_t$ 具体的计算方式见公式(5),$l_t$ 具体的计算方式见公式 (4), $lt$ 是一个 K × K 大的 Saliency Map, $X{t,i}$ 是什么?公式(5)很像是 Weighted 的 Global Average Pooling 啊,LSTM 负责计算 Weight Map, 直接乘上原来的 Features Cube,然后做 Global Averaging Pooling ,作为 Global context,concat 到 Region ROI 出来的
- Finally, a global context feature is pooled based on the calculated attention map and fed into two fully-connected layers.
$I$ 是 input image,$p$ 是 one specific proposal
The proposal p is encoded by its size (w, h) and coordinates of its center $(c_x,c_y)$, i.e., $p = (c_x,c_y,w,h)$.
To exploit inside and outside contextual information of p, we crop p from the feature cube with three scaling factors: $λ_1 = 0.8, λ_2 = 1.2 and λ_3 = 1.8$.
denote the features of p pooled from crops of the feature cube with different sizes as ${v_p^i |i = 1, 2, 3}$
没看懂,Based on the feature cube, the recurrent model learns an attention map with the shape of K2 to highlight the region that may benefit the object detection from the global view. 这句话在讲什么?
Denote feature slices in the feature cube as X = [xi,···,xK2], where xi(i = 1,···,K2) is with D dimension.
At each time-step t, the attention model predicts a weighted map lt+1, a softmax over K×K locations. This is probabilistic estimation about whether the corresponding region in the input image is beneficial for the object classification from the global view.
a K × K attentive location map is cal- culated to selectively combine the features of all locations into a 1 × 1 × D global attention-based feature. 这个怎么做到的?
Inside-Outside Net: Detecting Objects in Context With Skip Pooling and Recurrent Neural Networks
在 F-RCNN 的框架下如何对特征进行增强,文章主要考虑了 multi-layer fusion 和 context 信息。
Contextual 和 multi-scale representations 对于视觉识别是很重要的。论文考虑结合 ROI 内外的有用信息,其中 ROI 外部 Contextual 信息的集成利用 spatial RNN。其四向 IRNN 结构如下,之后再将此 context 特征与局部特征结合:
ION(inside-outside-network):这个工作的主要贡献有两个,第一个是如何在 Fast R-CNN 的基础之上增加 context 信息,所谓 context 在目标检测领域是指感兴趣的 ROI 周围的信息,可以是局部的,也可以是全局的。为此,作者提出了 IRNN 的概念,这也就是 outside-network。第二个贡献是所谓 skip-connection,通过将 deep ConvNet 的多层 ROI 特征进行提取和融合,利用该特征进行每一个位置的分类和进一步回归,这也就是 inside-network。
探索怎么利用 two additional sources of information,一个是 a multi- scale representation,captures fine-grained details by pooling from multiple lower-level convolutional layers in a ConvNet。These skip-layers [36, 25, 26, 13] span multiple spatial resolutions and levels of feature abstraction. The information gained is especially important for small objects, which require the higher spatial resolution provided by lower-level layers. 另一个是 the use of contextual information.
一个纵向从 Multi-scale feature 上找,另一个横向从 context 上找
context and multi-scale, are complementary in na- ture. This matches our intuition that context features look broadly across the image, while multi-scale features capture more fine-grained details.
[3, 42] explore running an RNN spatially (or laterally) over a feature map in place of convolutions 什么是 Spatial RNNs?
[3] W. Byeon, T. M. Breuel, F. Raue, and M. Liwicki. Scene labeling with LSTM recurrent neural networks. In CVPR, 2015.
[42] F. Visin, K. Kastner, K. Cho, M. Matteucci, A. Courville, and Y. Bengio. ReNet: A recurrent neural network based alternative to convolutional networks. arXiv e-prints, arXiv:1505.00393 [cs.CV], 2015.