这篇是对下面两篇文章的笔记整理。两篇文章都是同一个作者,前一篇是 ECCV 2018 的文章,后面作者挂在了 arXiv 上,看样子是投 CVPR 的。
Yohanandan, ECCV 2018, Saliency Preservation in Low-Resolution Grayscale Images
Yohanandan, arXiv 2018, Fast Efficient Object Detection Using Selective Attention
注意力机制一般分为 bottom-up 和 top-down 两种。Bottom-up 的注意力机制是外界刺激和特征驱动的,负责快速、自动且不由自主的注意力和凝视的快速转变;相反,top-down 机制是任务驱动、基于经验(记忆)的,因人而已。这篇笔记,或者说上面两篇论文只针对 Bottom-up,主要内容是从生理机制上解释为何人类的显著性检测和选择性注意力能够如此高效。此外,对我而言,读完这两篇文章另外一个收获是对于 Object Detection 中的 One-stage method 和 Two-stage method 中的选择,让我坚定了对 Two-stage method 的信仰,因为在我看来人眼 Bottom-up 的视觉选择性注意就是一个 two-stage 过程。
Biological Explanation
作者先是讲了一个生物视觉进化的故事:
- 最早的生物都是没有视觉的
- 后来略微进化出一点感光细胞,有了 discriminated night and day 的能力;
- 再后来,有了一点光源定位的能力,能够 distinguishing light from shadow;
- 接着是进化出能够粗略认出周围物体的能力,这被认为是 the birth of stimulus-driven, bottom-up visual salience detection,到这一阶段是 blurry achromatic peripheral vision,模糊的消色的外围视觉
- 然后,进化出 focus-sharpening lenses
- 再然后是 foveated central vision
- 最后才是感知 彩色 的能力,到这一步才有 high-acuity chromatic central vision,高度敏锐的彩色中央视觉
从这个故事叙述里,作者已经开始在暗示 彩色 和 高敏锐度的视觉都是在 粗略认出周围物体的能力 之后发展出来的。如果只是要模拟粗略认出周围物体的能力(这就是 Region Proposal 干的事情),那么就不需要在我们的 computational model 里面去涉及对彩色 和 高敏锐度的视觉的模拟,彩色就是彩色,高敏锐度的视觉则指的是高分辨率图像,也就是说 Region Proposal 或者 Saliency Detection 不需要在彩色高分辨率图像上做,只要 blurry achromatic peripheral vision 就可以了。
由此可见,人类 bottom-up Attention 其实有两部分构成,一部分是 blurry achromatic peripheral vision,另一部分是 high-acuity chromatic central vision。Peripheral vision 相当于 Region Proposal,负责 bottom-up visual salience detection,用来指示 the sharper, high-resolution foveated (sometimes chromatic) vision to investigate objects and regions further,由此实现了人类可以 rapidly shift foveal gaze to salient regions 的能力。但这样机制的背后,是有具体的生理基础。
总所周知,我们视网膜上的感光细胞分为视杆细胞(Rods)和视锥细胞(Cones),这两种细胞在分工、数量、分布和连接的后续细胞的数量上都有以下不同:
- 在分工上,Rods primarily encode achromatic luminance (brightness) information;而 cones encode chrominance (color);
- 在分布上,Rods have a higher distribution outside the fovea;而 are concentrated in the fovea (center of the retina),这就是为什么一个被叫做 peripheral vision,一个被叫做 foveated central vision,下图展示了 Rods 和 Cones 的分布情况
- 在连接的后续细胞的数量上,multiple rods converge to and activate a single retinal ganglion neuron,而 each cone activates multiple ganglion neurons。这个 Retinal ganglion cells (RGCs) 是 Final output neurons of the retina,可以代表输出图像的分辨率。因为连接的后续细胞的数量上,Rods 少于 Cones,这也是为什么 rod vision has lower spatial resolution,而 Cones vision 是 higher acuity vision。为什么最后输出的图像分辨率会不同,因为决定感知到的图像分辨率(perceived image resolution)的 并不是 光感受体(photoreceptors)数量,而是 视网膜传入神经节神经元 RGCs,而视锥细胞连接的 视网膜传入神经节神经元 比 视杆细胞多。
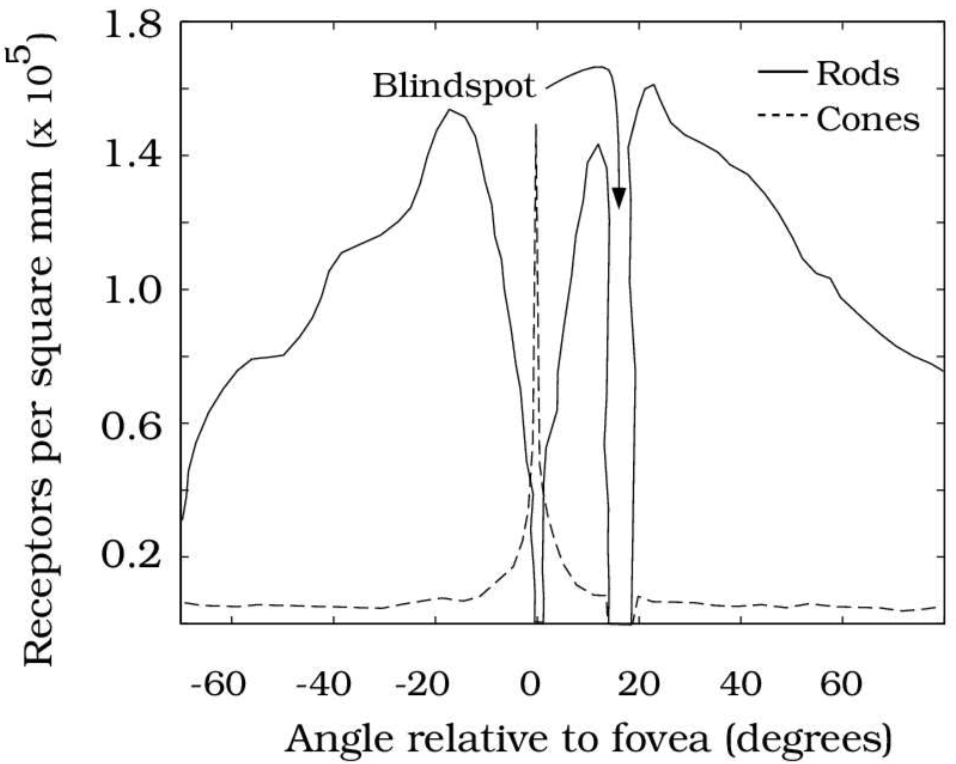
因此,可以稍微概括下,Cones, concentrated in the fovea, encode high-resolution color. Rod photoreceptors distributed outside the fovea encode low-resolution grayscale information。
那么具体 Rods 对应的 RGCs 和 Cones 对应的 RGCs 分别是什么,又是怎么一个数量关系呢?RGCs 作为视网膜最后的输出神经元,有 P$\beta$ RGCs,P$\alpha$ RGCs 和 P$\gamma/\epsilon$ RGCs 三类。其中,P$\beta$ RGCs 负责通过 longwave (red), medium-wave (green), and shortwave (blue) sensitive detectors 表现 color opponency 颜色对比。什么是这些 RGB sensitive detectors 呢?就是 Cones 视锥细胞。而 P$\alpha$ RGCs 和 P$\gamma/\epsilon$ RGCs 是消色的,编码 primarily luminance information。P$\beta$ RGCs,P$\alpha$ RGCs 和 P$\gamma/\epsilon$ RGCs 的分布分别是 Laplacian,Gaussian 和 Poisson,前两者分布相对集中、中心化,而后者分布相对均匀、平坦。具体如下图所示。
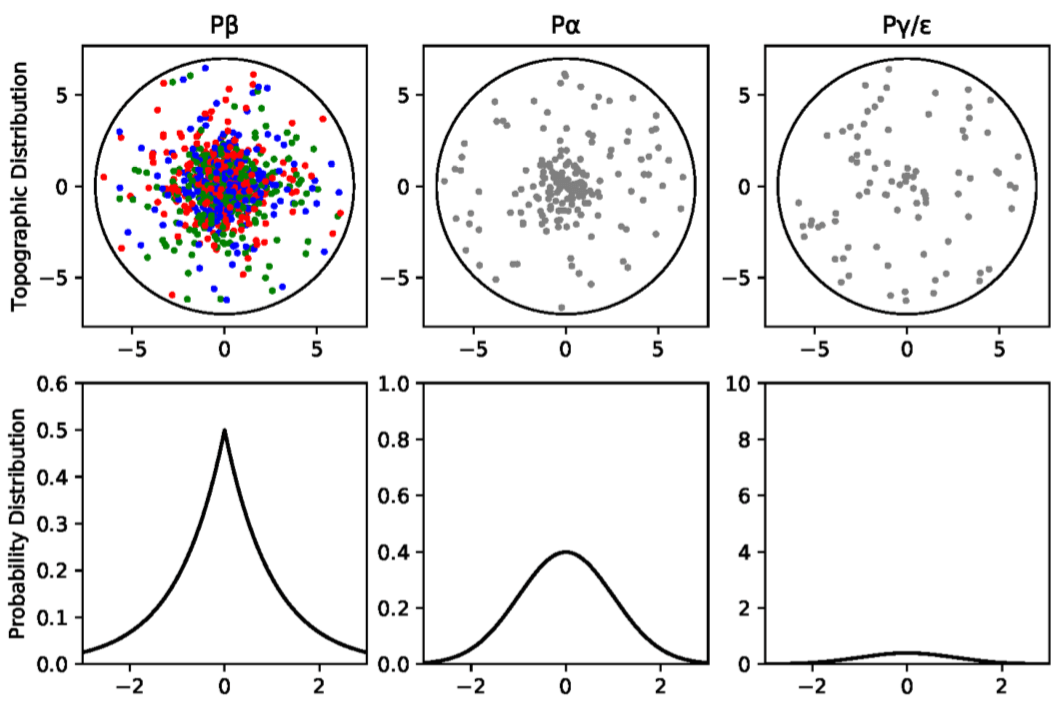
在所有 RGCs 中,大约 80% 是表现颜色对比度的 P$\beta$ RGCs;大约 10% 的 RGCs 是消色的 P$\alpha$ neurons,他们的轴突投射都是从视网膜的 foveal region 到 lateral geniculate nucleus 外侧膝状体,简称 LGN。只有剩下 10% 的 P$\gamma$ RGCs 和 P$\epsilon$ RGCs 以及某一些 P$\alpha$ RGCs,被投影到了一个叫做 optic tectum,中文叫视顶盖,也叫 superior colliculus,中文叫 上丘 的结构,简称 SC。由于 SC 接收到的信息只有所有 RGCs 的 10%,这就是为什么论文中会说 SC 所接收的信息只有输入视网膜信息的 10% 的依据,是属于较低分辨率的视觉信息,且是消色的。而近年来神经科学的研究发现,SC 是负责产生显著性图的区域,是 bottom-up salience detection 的先驱。 此外,SC 还对眼部肌肉有着直接控制,direct retinal input into the SC 引发由脑干动眼神经核控制的反射般的跳视 reflex-like saccades,这个应该是为了输入 High-Resolution Color Foveal Image。Eye movements align objects with the high-acuity fovea of the retina, making it possible to gather detailed information about the world。因此,在我看来,Rods 负责完成消色下采样,SC 负责 generate Saliency map 并在此基础上做 Region Proposal(通过 control eye muscles 实现)。
多提一句 Saliency map 的价值在于 This mapping projects the locations of salient and interesting regions in visual space, thus making vision more efficient by narrowing down the regions an observer must attend to in a typically large visual field. 这是 Region Proposal 的作用。
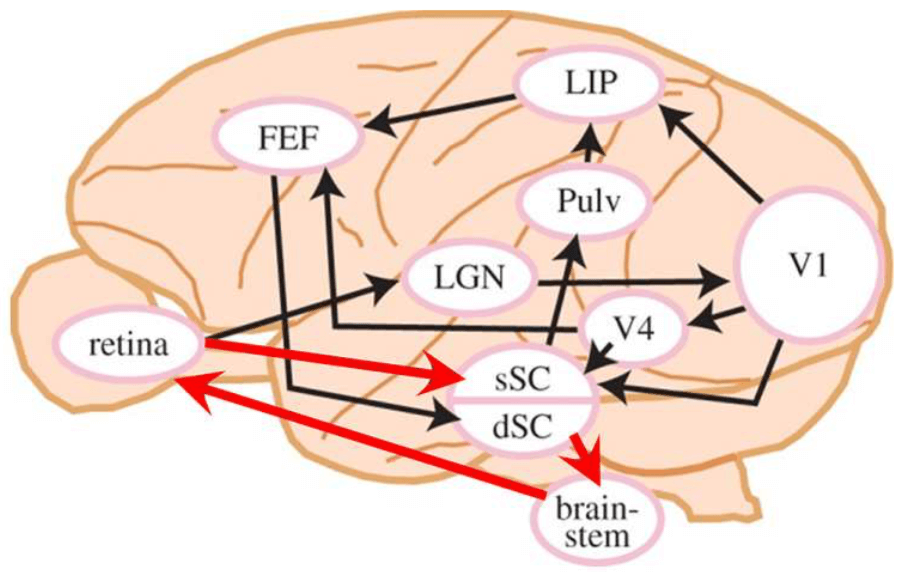
这里表明,人类视觉有两条视觉通路,一条是开始与消色的 Rods 光感受体 -> P$\gamma$ RGCs 和 P$\epsilon$ RGCs -> SC 的通路,这条通路叫作 the retinocollicular pathway,也是下图中红色箭头所指的;另一条是 Cones -> P$\beta$ RGCs 和 P$\alpha$ RGCs -> LGN -> V1 的通路,具体如下图所示。两条通路这件事对我震动蛮大的,以前人们认为 the saliency map was generated in the primary visual cortex (V1),也就是认为图像只有一个输入,就是高分辨率的输入;但现在发现,图像其实有 两个输入,different visual pathways,一个是输入 SC 的 LG 图像,另一个是根据 SC 产生的 Saliency Map 指导下输入的 high-resolution region。但目前我们 end-to-end 的算法都只有高分辨率输入,要不要为此做出相应的改变呢?
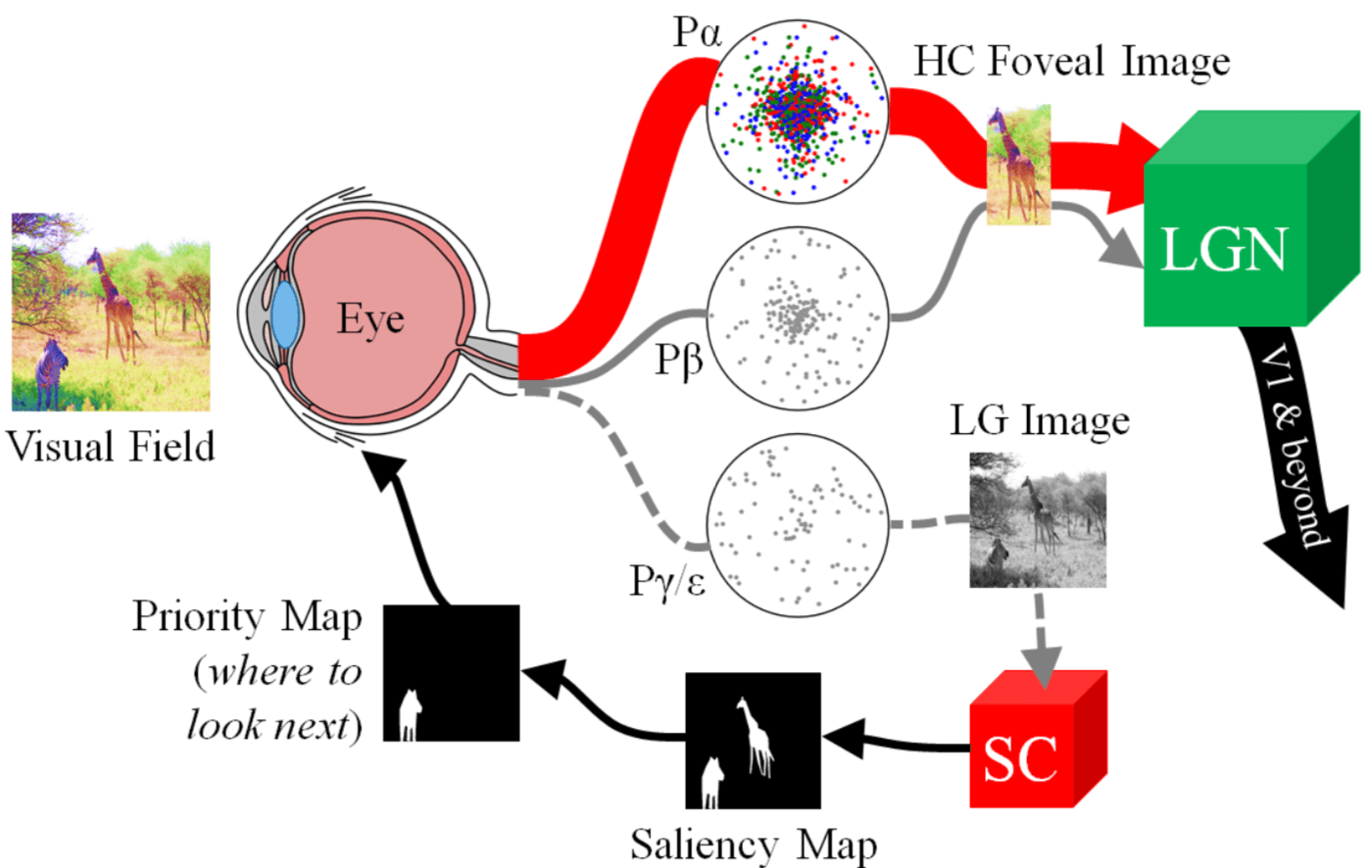
现在我们已经知道人类视觉是在以 Rods 为起点的 blurry achromatic peripheral vision 通路,和以 Cones 为起点的 high-acuity chromatic central vision 两条通路合作下工作的,那么它们是怎么合作的呢?
快速高效的 Bottom-Up Visual Attention 的机制如下,关键在于 processing low-resolution achromatic visual information from the retina:
- 首先,the retinocollicular pathway shrinks the high-resolution color image projected onto the retina from the visual field into a tiny colorless, e.g. low-resolution grayscale, image, which can then be scanned quickly by the SC to highlight peripheral regions worth attending to via the saliency map.
- The SC then aligns the fovea to attend to one of these regions, thereby sending higher-acuity, e.g. high-resolution color, visual information to the LGN and beyond for further processing.
- In doing so, a new image of the visual field is now projected onto the retina, and the cycle repeats.
具体的示意图如下图所示:
由此可见,Visual signals from the retina to the cerebral cortex are mediated through the primary visual cortex (V1) and the superior colliculus (sSC and dSC). 输入大脑皮层的视觉信息同时受到 primary visual cortex (V1) 和 superior colliculus 的调解,这也应了一个很早以前就看到的观点,大脑并不是一个中央处理器,而是由多个处理器共同决策、控制的结果。
除了输入是 Low-Resolution Grayscale Images 之外,Visual Saliency Attention 能够快速有效的还有一个生理基础在于存在一个 a shortcut from the superficial (sSC) to the deep (dSC) superior colliculus, which then sends outputs directly to the brainstem oculomotor nuclei, resulting in rapid saccades,也就是 现在的 shortcut 是 retina -> sSC -> dSC -> brain-stem -> retina,否则得话,我看图上有 retina -> LGN -> V1 -> V4 -> FEF -> dSC -> brain-stem -> retina 这种绕一圈的通路,这就没法 rapid 了。
Computational Approximation
我们稍微概括一下上面的生物机制,然后看看如何用计算模型模拟这种生物机制
- SC 是产生显著性图的地方
- SC 的输入是 low-resolution grayscale image
对上述生物机制的计算模型逼近显然易见,就是在 Low-Resolution Grayscale Images 上计算显著性图,并以此显著性检测的结果作为高分辨彩色输入图像上的 Region Proposal,然后再进一步识别。 在 Low-Resolution Grayscale Images 上计算显著性图先比在 High-Resolution Color Images 上计算并不会有什么信息缺失,这一点不管是上面的生物机制启示还是论文后面的数值实验都验证了,这就是论文标题的 Argument, Saliency Preservation in Low-Resolution Grayscale Images,而这么做的好处是非常高效。
- 怎么将 High-Resolution Color Images 降采样成 Low-Resolution Grayscale Images?(模拟 视杆细胞 负责对图像下采样)
- 怎么在 Low-Resolution Grayscale Images 上实现显著性检测?(模拟 SC 负责的基于显著性检测的 Region Proposal)
- 怎么对 High-Resolution Color 的 Foveal Image(比如上图右上角的长颈鹿所在的 Region Proposal)实现识别?
那么降采样改怎么做呢?分为两步。感觉这个就很平常了
- 第一步,transforming the color space of high-resolution color (HC) images $I_HC$ to 8-bit grayscale $I_HG$
- 第二步是 down-sampled the original image resolution using bicubic interpolation (单边 64 像素,或者 downsample the original image to 10% of its original size,但作者也提到了,10% 是依据猕猴的生理机制来的,未必对于计算机视觉里的Object Detection 就是最优的)
但作者说这篇文章是提出本文是最早提出 Saliency Preservation in Low-Resolution Grayscale Images,感觉也有点过了,我印象里至少 Hou Xiaodi 在 CVPR 2007 的 Spectral Residual 里面就提到 64 x 64 就足好地可以计算显著性了。
至于怎么实现显著性检测,作者虽然给了方案,但是太简略了,也不是我对论文感兴趣的原因。至于第三个问题,论文中也没有提。
对目标检测的启示
目前方法慢的原因:不管是 One-Stage 还是 Two-Stage 的 Region Proposal 阶段,虽然他们都是在 downsampling 后的 feature map 上做的,但是这些 feature map 都来自于 High-Resolution Color Images。从 High-Resolution Color Images 得到这些 Feature Map 需要消耗很多的计算量,这是一个慢的原因。另一个慢的原因是 exhaustive classification,为了要 densely covering many different spatial positions, scales, and aspect ratios 需要 evaluate $10^4 − 10^5$ candidate regions per image. 但我不是很赞成后面一点,因为在不知道目标可能在哪之前,总要考虑所有区域,做 Saliency Detection 本身也是一件需要 exhaustive search 的事情,计算的绝大多数区域而是一样的 uninformative background。
而在 Low-Resolution Grayscale Images 上做 Region Proposal 的好处是,significantly reducing the visual search space of objects and regions of interest;因为 输入是 LG,总的计算量不大,另外一个好处是,generating a saliency map 只要 a relatively small and simple neural network 就够了,模型不需要很大。
作者这里还有一个 argument,是 detecting the presence of an object,如果仅仅是 detect 也就是判断有无,而不是判断哪一类(Classification),那么high-resolution details about objects, such as texture, patterns, and shape 这些是没有用的,color or other feature-specific properties are seem only essential for classification,这个 argument 支持了为什么 natural vision 会有 LG transformation。但作者这里的 Detect 是 Region Proposal 阶段的 Saliency Detection,并不是现在我们常说的 Object Detection 的 Detection。
最后的最后,这篇文章给我留下的疑惑是,这丫不就又回到 R-CNN,Region Proposal 和后面的 Classification 分开做,且 Region 要 resize 之后的路线了么?
最后,推荐下知乎上的两篇专栏文章,介绍了 视网膜神经回路、外侧膝状体和初级视觉皮层。
如果您觉得我的文章对您有所帮助,不妨小额捐助一下,您的鼓励是我长期坚持的动力。
 |
 |
|---|---|